深入理解Ceph存储架构( 五 )
译者注: 注意上图中 , 5个块的名称都叫NYAN , 每个块的内容为K个均分的内容 ,同时被切分后的每个块都有一个唯一序号shard, 每个块都对应不同的OSD , 即块按HOST进行故障域隔离 。
译者注: 比如以下配置及图例中 , K=4 ,M=2 并且以rack作为故障域)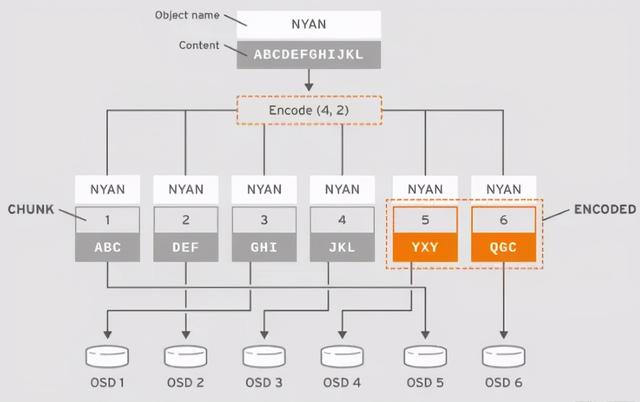 文章插图
文章插图
如果从纠删码存储池中读取对象 NYAN ,解码函数需要读取3个块: 包括ABC 的第一个块 ,包括GHI 的第3个块以及包括YXY 的第4个块;然后重构出对象的内容ABCDEFGHI。 解码函数来通知第2个块和第5个块缺失(一般称为纠删或擦写) 。
可在这2个缺失的块中 , 第5个块缺失可能因为OSD4 状态是OUT而读不到 , 只要读到3个块可读的话 , 解码函数就可以被调用:因为OSD2对应的是最慢的块 , 所以读取时排除掉不在考虑之内 。
将数据拆分成不同的块是独立于对象放置规则的 。 CRUSH规则集和纠删码存储池配置决定了块在OSD上的放置 。 例如 , 在配置中如果使用lrc(局部可修复编码)插件来创建额外块的话 , 那么恢复数据的话则需要更少的OSD 。
例如lrc配置信息: K=4、M=2、L=3 中 , 使用jerasure插件库来创建6个块(K+M) , 但局部值(L=3 )则要求需要再创建2个局部块 。 额外创建的局部块个数可以通过(K+M)/L 来计算得出 。 如果0号块的OSD出现问题 , 那么这个块的数据可以通过块1 , 块2以及第一个局部块进行恢复 。 在这个例子中 , 恢复也只需要3个块而不是5个块 。 关于CRUSH、纠删码配置、以及插件的内容 , 可以参考存储策略指南 。
注: 纠删码存储池的对象映射是失效的 , 不能设置为有效状态 。 关于对象映射的更多内容 , 可以参考对象映射章节 。
注: 纠删码存储池目前公支持RADOS网关(RGW) , 对于RADOS的块设备(RBD)目前还不支持 。
2.6 自管理的内部操作Ceph集群也会自动的执行一些自身状态相关的监控与管理工作 。 例如 , Ceph的OSD可以检查集群的健康状态并将结果上报给后端的Ceph mon;再比如 , 通过CRUSH算法将对象映射到PG上 , 再将PG映射到具体的OSD上;同时 , Ceph OSD也通过CRUSH算法对OSD的故障等问题进行自动的数据再平衡以及数据恢复 。以下部分我们将介绍Ceph执行的一些操作 。
2.6.1 心跳Ceph OSD加入到集群中并且将其状态上报到Ceph mon 。 在底层实现上 , Ceph OSD的状态就是up或为down ,这一状态反映的就是OSD是否运行并为Ceph客户端的请求提供服务 。 如果Ceph OSD在集群中的状态是donw且为in, 那么表明此OSD是有问题不能提供服务的;如果Ceph OSD并没有运行(比如服务crash掉了) , 那么这个Ceph OSD也不能上报给Ceph mon其自身状态为Down。
Ceph mon会定期的ping 这些OSD以此来确信这些OSD是否仍在运行 。 当然了 , Ceph也提供了更多的机制 , 比如使Ceph OSD可以评判与之关联的OSD是否状态为down(译者注:比如在副本OSD间相互ping状态的关系 , 没有副本关系的话 , OSD之间不会建立连接亦即更不会ping彼此) , 以及更新Ceph的集群映射关系并上报给Ceph mon 。 由于OSD分担了部分工作 , 所以对于Ceph mon来说 , 工作内容相对要轻量很多 。
2.6.2 同步Ceph OSD守护进程执行同步 , 这里的同步指的是将存储放置组(PG)的所有OSD中对象状态(包括元数据信息)达到一致的过程 。 同步问题通常都会自行解决无需人为的干预 。
注: 即使Ceph mon对于OSD存储PG的状态达成一致 , 这也并不意味着PG拥有最新的内容 。
当Ceph存储PG到OSD的acting set列表中的时候 , 会将它们分别标记为主 , 从等等 。 惯例上 , Acting set列表中的第一个是主OSD , 主OSD也负责协调组内的PG进行同步操作 , 这里的主OSD也是唯一 接收客户端的写入对象到给定PG请求的OSD 。
当一系列的OSD负责一个放置组PG , 则这一系列的OSD , 我们称它们为一个Acting Set 。 Acting Set可能指的是当前负责放置组的Ceph OSD守护进程或者某个有效期内 , 负责特定放置组的OSD守护进程 。
Acting Set中的部分Ceph OSD可能不会一直是up 状态 。 当Acting Set中的OSD状态是up 状态时 , 那么这个OSD也是Up Set中的成员 。 相对Acting Set来说 , Up Set是非常重要的 , 因为当OSD失败时 , Ceph可以将PG重新映射到其他Ceph OSD上 。
注: 对于PG包括osd.25、osd.32、osd.61的Acting Set列表 , 列表中第一个OSD即osd.25 是主OSD 。 哪果主OSD失败 , 那么从属OSD 即osd.32 就会成为新的主OSD , 同时原主osd.25 也会从Up Set列表中删除 。
2.6.3 数据再平衡与恢复当我们向Ceph存储集群中新增加Ceph OSD的时候 , 集群映射关系随着新增加的OSD同时也会更新 。 因此 , 由于这一变化改变了计算CRUSH时提供的输入参数 , 所以也就间接的改变了对象的放置位置 。 CRUSH算法是伪随机的 , 但会均匀的放置数据 。 所以集群中新增加一台OSD时 , 也只会有一小部分的数据发生迁移 。 一般迁移的数据量是集群总数据量与OSD数量的比值(例如 , 在有50个OSD的集群中 , 当新增加一台OSD时也只有1/50 或者2%的数据受到迁移影响) 。
- 启动|拼多多深入布局母婴产业带 补贴+直播启动“母婴产品溯源”行动
- RFID在冷链物流中的作用-RFID冷链资产管理解决方案
- 《深入理解Java虚拟机》:对象创建、布局和访问全过程
- 都说编程要逻辑好,如何理解这个逻辑
- 成长思维:我大哥对“道法术器”的理解,80%的人不懂
- Linux信号透彻分析理解与各种实例讲解
- 深入理解Netty编解码、粘包拆包、心跳机制
- 从底层理解this是什么
- 《深入理解Java虚拟机》:锁优化
- 不外|一发工资就转走,损失的是银行吗?原来我们都理解错了