深入理解Ceph存储架构( 三 )
下面的图描述了CRUSH是如何将对象分配到PG中 , 以及PG分配到OSD中的 。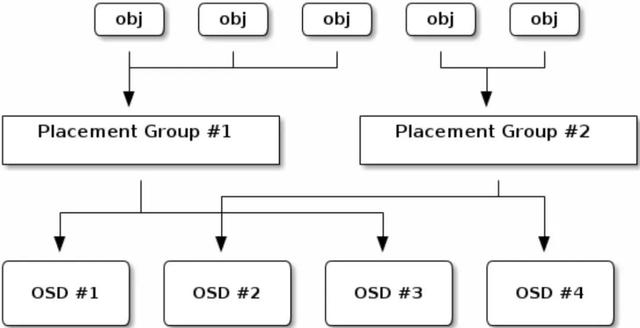 文章插图
文章插图
相对整体集群规模来说 , 如果存储池设置的PG较少 , 那么在每个PG上Ceph将会存储大量的数据;如果存储池设置的PG过大 , 那么Ceph OSD将会消耗更多的CPU与内存 , 不管哪一种情况都不会有较好的处理性能 。所以 , 为每个存储池设置适当数量的PG , 以及分配给集群中每个OSD的PG数量的上限对Ceph性能至关重要 。
译者注: PG是对象的集合 ,在同一个集合里的对象放置规则都一样(比如同一集合中的对象统一都存储到osd.1、osd.5、osd.8这几台机器中);同时 , 一个对象只能属于一个PG , 而一个PG又对应于所放置的OSD列表;另外就是每个OSD上一般会分布很多个PG 。
2.4 CRUSHCeph会将CRUSH规则集分配给存储池 。 当Ceph客户端存储或检索存储池中的数据时 , Ceph会自动识别CRUSH规则集、以及存储和检索数据这一规则中的顶级bucket 。 当Ceph处理CRUSH规则时 , 它会识别出包含某个PG的主OSD , 这样就可以使客户端直接与主OSD进行连接进行数据的读写 。
为了将PG映射到OSD上 , CRUSH 映射关系定义了bucket类型的层级列表(例如在CRUSH映射关系中的types以下部分) 。 创建bucket层级结构的目的是通过其故障域和(或)性能域(例如驱动器类型、hosts、chassis、racks、pdu、pods、rows、rooms、data centers)来隔离叶子节点 。
除了代表OSD的叶子节点之外 , 层次结构的其余部分可以是任意的 , 如果默认类型不符合你的要求 , 可以根据自己的需要来定义它 。CRUSH支持一个有向无环图的拓扑结构 , 它可以用来模拟你的Ceph OSD节点在层级结构中的分布情况 。
因此 , 可以在单个CRUSH映射关系中支持具有多个Root节点的多个层级结构 。 例如 , 可以创建SSD的层级结构、使用SSD日志的硬盘层级结构等等 。
译者注: CRUSH的目的很明确 ,就是一个PG如何与OSD建立起对应的关系 。
2.5 I/O操作Ceph客户端从Ceph mon获取‘集群映射关系Cluster map , 然后对存储池中的对象执行I/O操作 。 对于Ceph如何将数据存于目标中来说 , 存储池的CRUSH规则集和PG数的设置起主要的作用 。 拥有最新的集群映射关系 , 客户端就会知道集群中所有的mon和OSD的信息 。 但是 , 客户端并不知道对象具体的存储位置(不知道对象具体存在哪个OSD上) 。
对于客户端来说 , 需要的输入参数仅仅是对象ID和存储池名称 。 逻辑上也比较简单:Ceph将数据存储在指定名称的存储池中(例如存储池名称为livepool) 。 当客户端想要存储一个对象时(比如对象名叫 “john”、“paul”、"george”、 “ringo”等) , 客户端则会以对象名、根据对象名信息计算的hash码、存储池中的PG数、以及存储池名称这些信息作为输入参数 , 然后CRUSH(可控的、可扩展的、分布式的副本数据放置算法)就会计算出PG的ID(PG_ID)及PG对应的主OSD信息 。
译者注:根据设置的副本数(比如3副本)则计算出的列表如(osd.1、osd.3、osd.8) ,这里的第一个osd.1就是主OSD 。
Ceph客户端经过以下步骤来计算出PG ID信息 。
- 客户端输入存储池ID以及对象ID(例如 , 存储池pool=”liverpool”, 对象ID=”john”) 。
- CRUSH获取对象ID后对其进行HASH编码 。
- CRUSH根据上一步的HASH编码与PG总数求模后得到PG的ID 。 (译者注:例如HASH编码后为186 , 而PG总数为128 , 则求模得58 , 所以这个对象会存储在PG_58中;另外这也可以看出PG数对存储的影响 , 因为涉及到对象与PG的映射关系 , 所以轻易不要调整PG数)
- CRUSH计算对应PG ID的主OSD 。
- 客户端根据存储池名称得到存储池ID(例如”liverpool”=4) 。
- 客户端将PG ID与存储池ID拼接(例如 4.58)
- 客户端直接与Activtin Set集合中的主OSD通信 , 来执行对象的IO操作(例如 , 写入、读取、删除等) 。
 文章插图
文章插图Ceph存储集群的拓扑和状态在会话(I/O上下文)期间相对比较稳定 。 与客户端在每个读/写操作的会话上查询存储相比 , Ceph客户端计算对象存储位置的速度要更快些 。 CRUSH算法不但能使客户端可以计算出对象应当存储的位置 , 同时也使得客户端可以和Acting Set集合中的主OSD直接交互来实现对象的存储与检索 。由于EB规模的存储集群一般会有数千个OSD存储节点 , 所以客户端与Ceph OSD之间的网络交互并不是什么大的问题 。 即使集群状态发生变化 , 客户端也可以通过Ceph mon查询到更新的集群映射关系 。
- 启动|拼多多深入布局母婴产业带 补贴+直播启动“母婴产品溯源”行动
- RFID在冷链物流中的作用-RFID冷链资产管理解决方案
- 《深入理解Java虚拟机》:对象创建、布局和访问全过程
- 都说编程要逻辑好,如何理解这个逻辑
- 成长思维:我大哥对“道法术器”的理解,80%的人不懂
- Linux信号透彻分析理解与各种实例讲解
- 深入理解Netty编解码、粘包拆包、心跳机制
- 从底层理解this是什么
- 《深入理解Java虚拟机》:锁优化
- 不外|一发工资就转走,损失的是银行吗?原来我们都理解错了