中国|中国提出的AI方法影响越来越大,天大等从大量文献中挖掘AI发展规律( 二 )
通过基于 AI 标记的 AI 文献挖掘,我们可以得到如下主要发现与结论:
我们从有效方法和数据集的新角度,通过对 AI 标记进行统计分析,获得了反映 AI 领域年度发展情况的重要信息。例如,2017 年无人驾驶领域的经典数据集 KITTI 跻身于 top10 数据集,说明无人驾驶是 2017 年的热门研究主题;
在对 AI 标记进行溯源得到的原始文献的统计分析层面,我们发现新加坡、以色列、瑞士提出的有效方法数量相对较多;从有效方法在数据集上的应用情况来看,随着时间的发展,有效方法应用在不同数据集上的速度越来越快;从有效方法在国家间的传播程度来看,中国提出的有效方法对其他国家的影响力越来越大,而法国恰好相反;
基于方法簇和数据集信息,我们构建了方法路径图,能够展示同一方法簇内各个方法的时间发展史及数据集应用情况;对于场景簇,我们发现与显著性检测相关的经典计算机视觉研究场景最不容易受到其他研究场景的影响。
2 数据
在我们文献挖掘的研究过程中,需要用到大量的文献数据,因此,本节首先介绍了我们收集的文献数据。此外,在研究过程中,我们需要用到两个机器学习模型。因此,本节对这两个模型的训练数据也分别进行了介绍。
2.1 收集的文献数据
我们使用中国计算机学会(CCF) 等级(Tier-A、Tier-B 和 Tier-C)中的 AI 期刊和会议列表,收集了 2005 年至 2019 年出版的 122,446 篇论文。用 GROBID 将 PDF 格式的论文转换为 XML 格式,从 XML 格式论文中提取标题、国家、机构和参考文献等信息。为了便于阅读,我们将收集到的这些数据称为 CCF corpus。
2.2 章节分类的训练数据
通常,一篇 AI 文献的正文包括引言、方法介绍、实验章节、结论四个部分。本文利用章节分类策略将 AI 文献的正文按上述四部分进行分类。
我们随机选取 2000 篇 CCF corpus 中的文献,并招募 10 名 AI 领域研究生标注这 2000 篇论文中的 63110 个段落。我们称该数据为 TCCdata。TCCdata 用来构建章节分类中的 BiLSTM 分类器[3]。TCCdata 中每类章节的数量以及每类章节包含的段落数量如表 1 所示。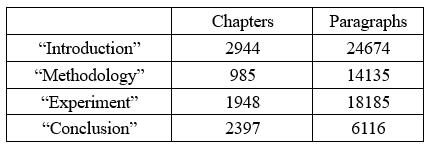
文章插图
Table 1:TCCdata 中章节和段落的数量
2.3 AI 标记抽取的训练数据
为了训练 AI 标记抽取模型,我们随机选取 1000 篇 CCF corpus 中的文献。将文献正文中方法章节和实验章节的内容按标点符号切分成句子,并招募 10 名 AI 领域研究生对这些句子进行标注。我们采用 BIO 标注策略标注方法、数据集、指标这三种实体,利用机器之心编译好的方法、数据集、指标作为标注参考。最后我们得到 10410 个句子,称之为 TMEdata。
在构建 AI 标记抽取模型时,我们将 TMEdata 按照 7.5:1.5:1 的比例划分成训练集、验证集和测试集。训练集、验证集和测试集中包含的三种 AI 标记的数量如表 2 所示。
Table 2:TMEdata 中 AI 标记的数量
3 方法
本节介绍本项研究所涉及的具体方法,包括章节分类、AI 标记的抽取与归一、AI 标记原始文献的溯源、方法和研究场景的聚类、方法簇内路径图的生成以及研究场景簇的影响程度。
3.1 章节分类
在一篇 AI 文献正文中,位于方法章节和实验章节的 AI 标记对该篇文献起着实质性作用,因此我们只对 AI 文献正文中方法章节和实验章节的 AI 标记进行抽取。但是,由于 AI 文献正文结构的多样性,难以用简单的规则策略对 AI 文献正文章节进行较为准确的分类。因此,本文提出了BiLSTM 分类器和规则相融合的章节分类策略。
3.1.1 提出的分类策略
章节分类的整体流程如图 2 所示。对于一篇 AI 文献的正文内容,我们首先利用规则匹配(关键词和顺序)对正文章节进行标注。对于匹配到的章节,则输出章节标签。对于未匹配到的章节,则将章节下的段落输入到基于 TCCdata 训练的 paragraph-level BiLSTM 分类器进行预测。接下来对相同章节标题下的段落预测结果进行投票,将出现次数最多的标签作为该章节类别。最后,将基于规则匹配得到的章节标签与基于投票得到的章节标签结合,得到整个正文的章节标签。
我们采取了常规的 one layer BiLSTM 架构。其中最大句子长度选取为 200,词向量的维度选取为 200,hidden 维度选取为 256,batchsize 选取为 64。采用交叉熵作为损失函数,TCCdata 作为训练数据。
文章插图
Figure 2:章节分类整体流程
3.1.2 评估结果
我们将 TCCdata 以 8:1:1 的比例划分成训练集、验证集、测试集。在测试集上,我们对规则匹配、paragraph-level BiLSTM、规则匹配与 paragraph-level BiLSTM 结合这三种章节分类方式分别进行了评估。结果表明,仅利用规则匹配,准确率为 0.793。仅利用基于 TCCdata 训练的 paragraph-level BiLSTM,准确率为 0.792。将规则匹配与基于 TCCdata 训练的 paragraph-level BiLSTM 结合后,准确率达到了 0.928。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 手机基带|为了5G降低4G网速?中国移动回应来了:罪魁祸首不是运营商
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化