按关键词阅读:
IT之家 11 月 8 日消息,今天,阿里巴巴达摩院公布多模态大模型 M6 最新进展,其参数已从万亿跃迁至 10 万亿,成为全球最大的 AI 预训练模型。
M6 是达摩院研发的通用性人工智能大模型,拥有多模态、多任务能力,尤其擅长设计、写作、问答,在电商、制造业、文学艺术、科学研究等领域有广泛应用前景。
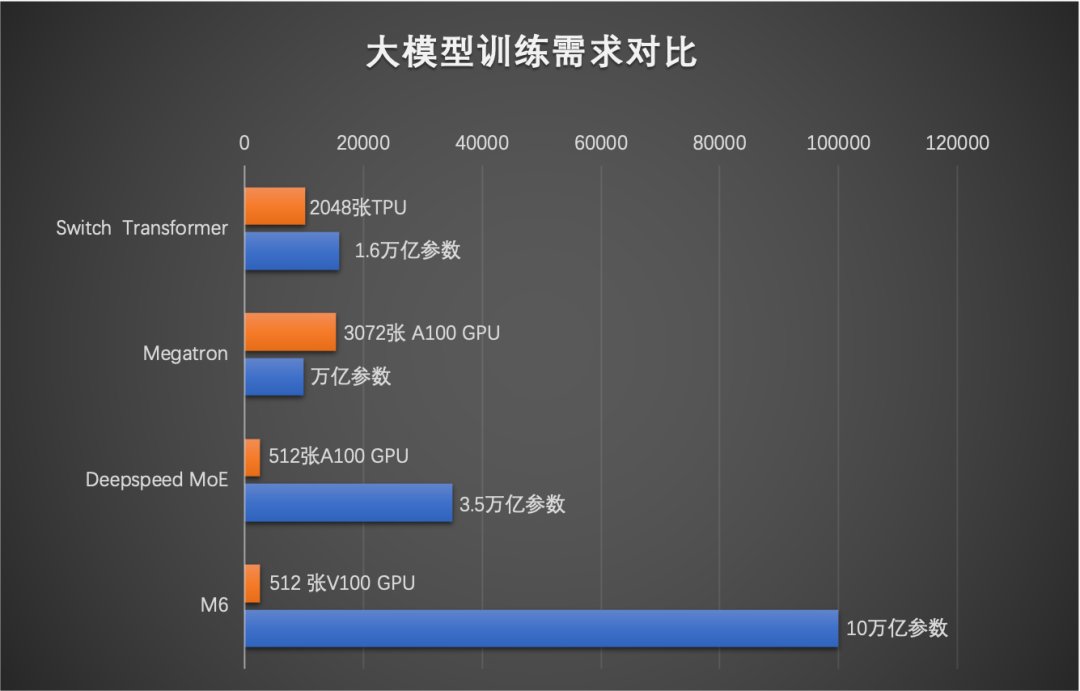
与传统 AI 相比,大模型拥有成百上千倍“神经元”数量,认知和创造能力也更胜一筹,被普遍认为是未来的“基础模型”。但大模型的算力成本相当高昂,训练 1750 亿参数语言大模型 GPT-3 所需能耗,相当于汽车行驶地月往返距离。
今年 5 月,通过专家并行策略及优化技术,达摩院 M6 团队将万亿模型能耗降低超八成、效率提升近 11 倍。
10 月,M6 再次突破业界极限,使用 512 GPU 在 10 天内即训练出具有可用水平的 10 万亿模型。相比去年发布的大模型 GPT-3,M6 实现同等参数规模,能耗仅为其 1%。
文章插图
▲ 将 10 万亿参数放进 512 张 GPU
模型扩展到千亿及以上参数的超大规模时,将很难放在一台机器上。
为了帮助多模态预训练模型进行快速迭代训练,达摩院在阿里云 PAI 自研 Whale 框架上搭建 MoE 模型,并通过更细粒度的 CPU offload 技术,最终实现将 10 万亿参数放进 512 张 GPU:
- 自研 Whale 框架:自研 Whale 分布式深度学习训练框架,针对数据并行、模型并行、流水并行、混合并行等多种并行模型进行了统一架构设计,让用户在仅仅添加几行 API 调用的情况下就可以实现丰富的分布式并行策略。
- MoE 专家并行策略:在 Whale 架构中实现 Mixture-of-Experts(MoE)专家并行策略,在扩展模型容量、提升模型效果的基础上,不显著增加运算 FLOPs(每秒所执行的浮点运算次数),从而实现高效训练大规模模型的目的。
- CPU offload 创新技术:在自研的分布式框架 Whale 中通过更细粒度的 CPU offload,解决了有限资源放下极限规模的难题,并通过灵活地选择 offload 的模型层,进一步地提高 GPU 利用率。
对比不使用该机制,预训练达到同样 loss 用时仅需 6%;和此前万亿模型相比,训练样本量仅需 40%。
文章插图
作为国内首个商业化落地的多模态大模型,M6 已在超 40 个场景中应用,日调用量上亿。
今年,大模型首次支持双 11,应用包括但不限于:
- M6 在犀牛智造为品牌设计的服饰已在淘宝上线;
- 凭借流畅的写作能力,M6 正为天猫虚拟主播创作剧本;
- 依靠多模态理解能力,M6 正在增进淘宝、支付宝等平台的搜索及内容认知精度。

文章插图
▲ M6 设计的飞行汽车
未来,M6 将积极探索与科学应用的结合,通过 AI for science 让大模型的潜力充分发挥,并加强 M6 与国产芯片的软硬一体化研究。
【 阿里达摩院发布全球最大 AI 预训练模型 M6:参数跃迁至 10 万亿】目前,达摩院联合阿里云已推出 M6 服务化平台(https://m6.aliyun.com),为大模型训练及应用提供完备工具,首次让大模型实现“开箱即用”,算法人员及普通用户均可方便地使用平台。
稿源:(IT之家)
【傻大方】网址:http://www.shadafang.com/c/110Y513E2021.html
标题:阿里达摩院发布全球最大 AI 预训练模型 M6:参数跃迁至 10 万亿