按关键词阅读:

文章插图

文章插图
- 在线修复 bad case。机器翻译系统不是完美无缺的,有时系统对某些输入会生成错误的译文,这样的输入我们称之为 bad case。快速修复 bad case 是机器翻译系统实际应用中的硬需求。而使用 bad case 及其对应的正确译文更新机器翻译系统为快速修复 bad case 提供了一种巧妙的思路。
- 使用流式生成的翻译数据增量更新机器翻译系统。机器翻译的训练数据不总是固定的,在一些场景中语言专家每天都会标注出新的机器翻译数据。使用这种流式生成的数据对机器翻译系统做全量的更新是成本很高的,而借助在线更新机器翻译系统的方法,对翻译系统做增量的更新不仅可以提升翻译性能,更新成本也大大降低。
但是基于样本的机器翻译系统泛化性较差,在检索不到相似样本的情况下,很难生成高质量的译文。因此,最近一些工作将样本检索与神经机器翻译结合,在神经机器翻译模型解码的过程中检索相似的翻译样本辅助译文生成。这种样本检索机制赋予了机器翻译系统在线更新的能力。
在这个方向上,一个经典的工作是发表在 ICLR 2021 上的 kNN-MT[2]。kNN-MT 为神经机器翻译引入了词级别的样本检索机制,使得翻译系统在无需额外训练的情况下,显著提升多领域机器翻译和领域适应机器翻译的能力,同时具有了在线更新的能力。
但是 kNN-MT 仍然存在一些问题,使用固定的将神经机器翻译输出和样本检索进行组合的策略使得它难以适应多变的输入样本。如图1所示,带有领域内翻译语料库的 kNN-MT 领域内的翻译质量取得了明显提升,而通用领域翻译质量却剧烈下滑。造成这种现象的原因是,kNN-MT 过度依赖了检索到的样本,在检索到的样本与测试样本不相似时,检索到的样本对于机器翻译而言反而是噪声,从而降低了翻译质量。
【 基于相似样本检索的在线更新机器翻译系统|EMNLP 2021 | 机器翻译】这篇工作主要针对该问题[3],提出了一种动态结合样本检索和神经机器翻译的方法 KSTER (Kernel-Smoothed Translation with Example Retrieval),使得翻译系统在检索到相似样本的情况下能够提升翻译效果,在检索不到相似样本时,也能保持原有的翻译质量,同时保持在线更新的能力。
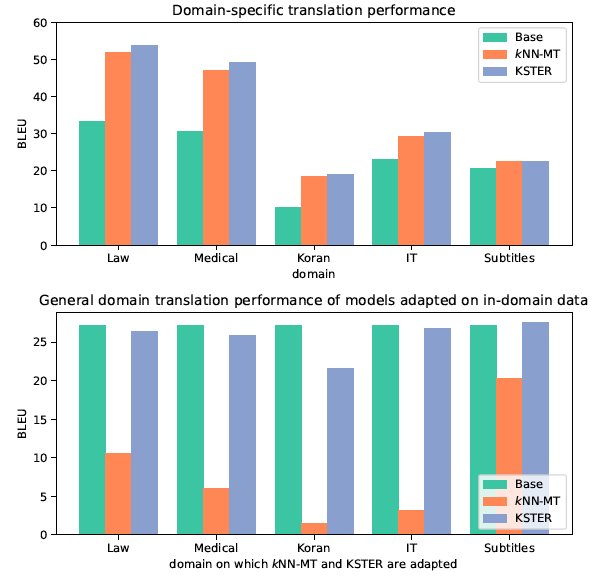
文章插图
图1 带有领域内数据库的kNN-MT,在领域内数据和通用领域数据上的翻译效果。
稿源:(雷锋网)
【傻大方】网址:http://www.shadafang.com/c/110Y512392021.html
标题:基于相似样本检索的在线更新机器翻译系统|EMNLP 2021 | 机器翻译