按关键词阅读:

文章插图
样本检索
在解码的每一步中,NMT 模型会计算出一个基于模型的下一个词分布 。另外,NMT 模型会计算当前上下文的向量表示作为查询,从翻译数据库中检索Top- k 个 L2 距离最小的样本。
可学习的核函数
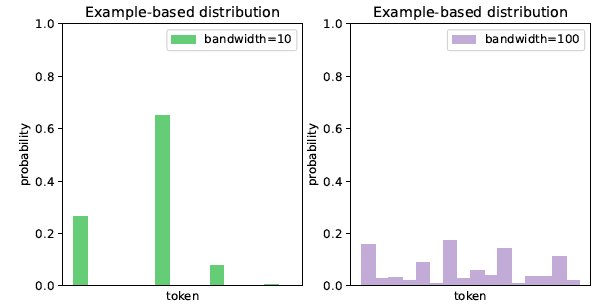
然后利用核密度估计根据检索到的样本估计出一个基于样本的分布 ,其中核函数是一个具有可学习带宽参数的高斯核或拉普拉斯核。带宽参数基于当前上下文和检索到的样本动态估计得出,主要是为了调整 的锐度。当检索出的 k 个样本只有几个头部样本与当前上下文相似时,低带宽的核密度估计会生成一个尖锐的分布,将绝大多数概率质量分配给头部样本,忽略尾部样本引入的噪声。
文章插图
文章插图
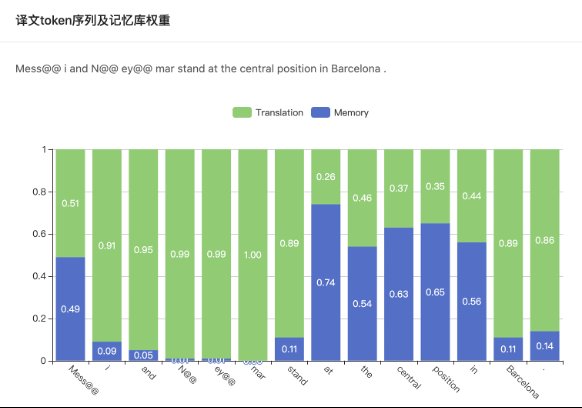
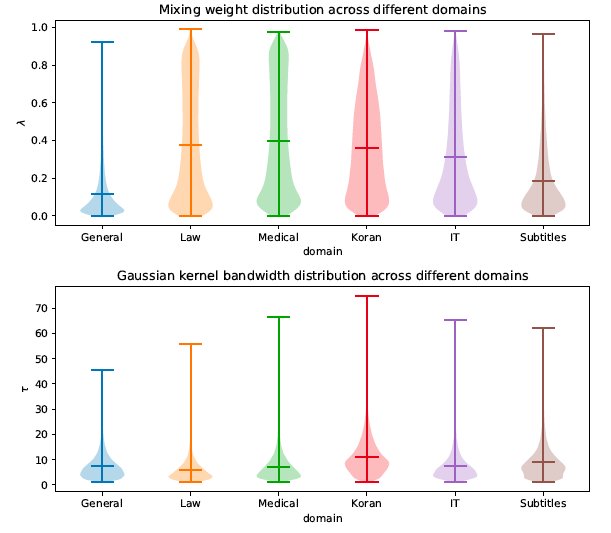
图4 动态的混合权重。Memory 表示基于样本的分布权重 ,Translation 表示基于模型的分布权重 。
模型训练策略
在 KSTER 训练过程中,NMT模型参数是固定不变的,需要训练的部分只有一个带宽参数估计器和一个混合权重估计器。作者使用交叉熵损失函数对翻译系统整体进行优化,但只更新带宽参数估计器和混合权重估计器的参数。
由于训练翻译系统的数据与构建翻译数据库的数据是相同的,在训练时总能检索到 top 1 相似的翻译样本就是查询自身。而测试数据通常在翻译数据库中没有出现过。这种训练和测试的不一致性,导致翻译系统容易过度依赖检索到的样本,产生过拟合的现象。为了缓解训练和测试的不一致性,作者在训练时检索最相似的 k + 1 个样本,并把第 1 相似的样本丢弃,保留剩下的 k 个样本用于后续的计算。这种训练策略被称为检索丢弃,在测试时并不使用这种策略。
文章插图
文章插图
文章插图
文章插图
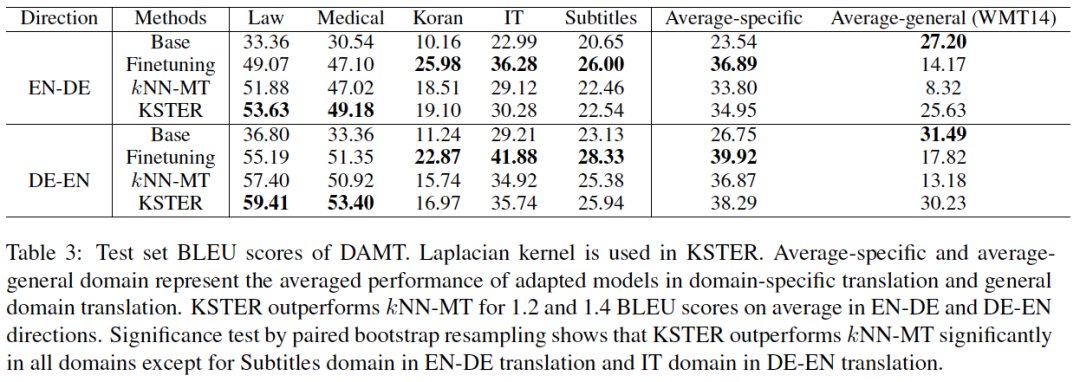
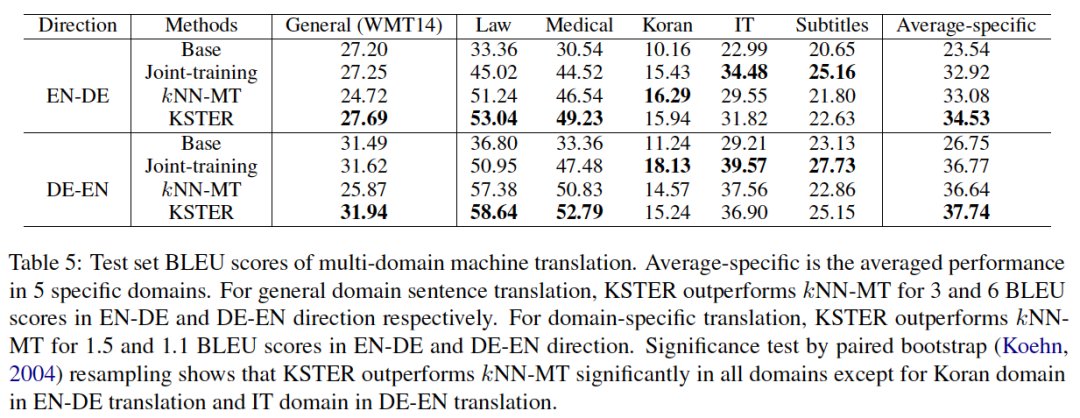
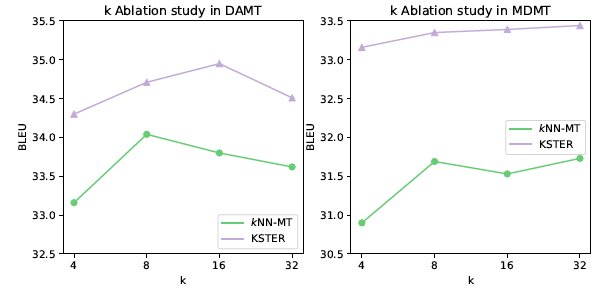
图8 检索不同数量样本 k 时,kNN-MT 和 KSTER 的翻译效果
图9 验证了检索丢弃这种训练策略的必要性。在不使用检索丢弃策略时,KSTER模型产生了严重的过拟合。而使用检索丢弃策略后,过拟合的现象得到明显缓解。![]()
稿源:(雷锋网)
【傻大方】网址:http://www.shadafang.com/c/110Y512392021.html
标题:基于相似样本检索的在线更新机器翻译系统|EMNLP 2021 | 机器翻译( 二 )