数据库|向量将死,哈希是 AI 未来

文章插图
事实上,人工智能的许多领域都可以从向量变为基于哈希的结构,带来飞跃的提升。本文将简要介绍哈希背后的应用逻辑,以及它为什么可能会成为 AI 的未来。
文章插图
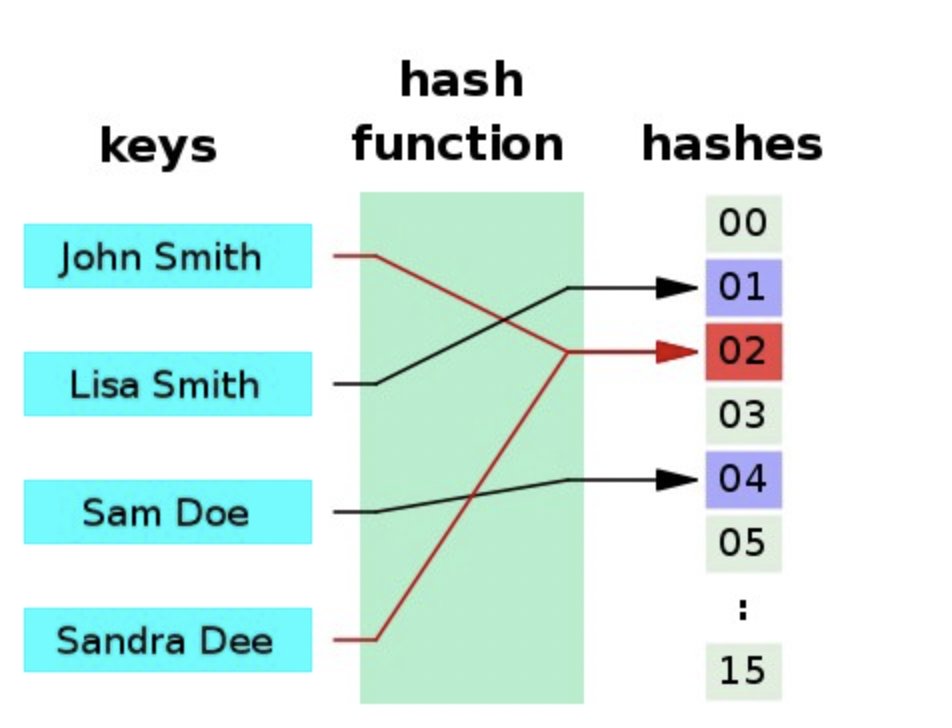
哈希在数据的准确性识别、数据存储大小、性能、检索速度等方面具有突出的优势。更重要的是,它们本质上是概率性的,因此多个输入项可以共享相同的哈希值。
在向量表示中,浮点数往往是首选的数据表示形式,尽管它们在本质上比哈希更绝对,但它们却并不精确。
对于微小的数值变化(关于向量计算),二进制表示也可以有很大的不同,这些数值变化对模型预测几乎没有影响。
例如:取 0.65 vs 0.66 在 float64(64 位浮点)二进制中可以分别用这两个二进制数表示:
- 11111111100100110011001100110011001100110011001100110011001101
- 11111111100101000111101011100001010001111010111000010100011111
对于神经元来说,这听起来像是一件愚蠢的事情,人类的大脑肯定不会这样工作,它们显然不会使用浮点二进制表示来存储数字,除非有人可以记住圆周率小数点后六万多位。
事实上,我们的大脑神经网络是非常形象的,在处理复杂的小数和分数方面非常擅长。但是,当我们算到一半或四分之一时,就会立即想象出一些东西,比如半杯水、四分之一杯水或者披萨等其他东西,可能根本没有想到尾数和指数。
一个常用的提高浮点运算速度和使用更少空间的方法是将分辨率降低到 float16(16位),甚至是float8 (8位),它们的计算速度非常快,但缺点是,它会造成分辨率的明显下降。
由于浮点数运算很慢,所以它真的没有一点优势吗?
答案是否定的。芯片硬件和它们的指令集被设计来提高效率,并使更多的计算并行处理,而 GPU 和 TPU 现在正在被广泛使用,因为它们处理基于浮点的矢量算法更快。
研究表明,有一系列哈希算法的确可以做到这一点,它被称为局部敏感哈希(LSH)。原始项越接近,其哈希中的位也越接近相同。

文章插图
不过,这个概念并不是什么新鲜事,只是最新的技术发现了更多的优势。从历史上来看,LSH 使用了诸如随机投影、量化等技术,但它们的缺点是需要较大的哈希空间来保持精度,因此其优点在某种程度上被抵消了。
对于单个浮点数来说这是微不足道的,但是具有高维数(多个浮点数)的向量呢?
因此,神经哈希的新技巧是用神经网络创建的哈希替换现有的 LSH 技术,以此得到的哈希值可以使用非常快速的 Hammin 距离计算来估计它们的相似度。
这听起来虽然很复杂,但实际上并不太难。总体来看,神经网络就是优化了一个哈希函数,具体表现如下:
- 与原始向量相比,几乎完美地保留了所有的信息;
- 生成比原始向量尺寸小得多的哈希;
- 计算速度明显更快;
- 数据库|提前三天自动续费,这合理吗?
- 微软|打工人必备技能!django查询数据库操作合集!
- 安卓|django怎么连接数据库?你知道吗?
- 数据库|不惜1.88亿置地造零件 华为做“中国博世”实锤了?
- 数据库|Jedis操作Redis数据库(八)
- 数据库|有没有适合学生的品牌蓝牙耳机?学生党最爱的平价蓝牙耳机推荐
- 一个 Babelfish ,看懂云数据库的发展方向
- 量子技术|贼心不死?自5G博弈后美国将遏制中国之手,伸向量子技术领域
- 研发中心|36氪首发|「四维纵横」完成1亿人民币A轮融资,打造超融合时序数据库
- 数据库|苹果VR头盔将拥有Mac级别的计算能力,将于2022年第四季度推出