token|中国力量在人工智能顶会崛起,这枚NLP“金牌”奥妙何在?

文章插图
以学术界为主力军的中国AI研究力量正在悄然变化,工业界的作用愈发凸显,与学术界一起形成双轮驱动之势。
伦敦帝国理工学院 Marek Rei 教授对ML&NLP;相关会议论文的统计显示,自2012年至2020年期间,美国以近4000篇论文的数量遥遥领先,中国、英国、德国和加拿大分别名列第二至五位。
美国科技公司在各大人工智能顶会上格外强势,微软和谷歌排名前二,IBM和Facebook也名列前十;与此形成鲜明反差的是,中国AI研究界则由学术机构当家,仅清华和北大跻身前十,分别排名第八和第九位。

文章插图
但是在AI技术应用火热的推动下,中国科技企业也逐渐从“辅助角色”进化为中坚力量。在刚刚结束的NLP顶会ACL 2021上,中国的论文投稿数量已经大幅超越美国,共有 1239 篇论文投稿来自中国大陆,其中 251 篇被接收,接收率 20.3%,工业界在其中出力甚多。
更值得欣喜的是,字节跳动AI Lab的词表学习方案VOLT赢得“最佳论文”奖项。这是ACL举办59年以来,中国团队第二次获得会议最高荣誉,上一次是由中科院计算所研究员冯洋获得ACL 2019年最佳长论文奖。此外,香港中文大学与腾讯AI Lab的合作论文成功入选“杰出论文”。
本次我们采访到了字节跳动AI Lab获奖论文作者,向读者介绍他们在ACL 2021上的工作。
字节跳动获奖论文“Vocabulary Learning via Optimal Transport for Machine Translation”提出了VOLT方法,能以非常低的代价学习词表,在机器翻译上取得了更好的性能。而词表几乎可以用于所有NLP任务,团队也在积极推动VOLT在其他NLP任务上的应用。
另外这项工作是从经济学和数学中获取灵感,从而给出了一个可行的词表学习方案。该论文第一作者许晶晶说:“我们给出了基于最大边际效应的一种可能的解释,和把词表学习建模成一个最优运输问题的全新想法。”

文章插图
论文地址:https://arxiv.org/abs/2012.15671
项目地址:https://github.com/Jingjing-NLP/VOLT
许晶晶于2015年进入北京大学电子工程与计算机科学学院,攻读博士学位,在计算语言学教育部重点实验室跟随孙栩教授做研究。
2021年2月,也就是五年后,AAAI首次评选“学术新星”(New Faculty Highlight),许晶晶成功入选,是入选者中唯一的中国机构学者。
回首五年前,许晶晶认为自己非常幸运,刚进入AI领域的时候,恰好就是自然语言处理从传统的浅层模型走向深度模型的过渡点。“对于NLP领域而言,深度学习在当时还是一种比较新的方法,入学的时候比较幸运赶上了深度学习在自然语言处理应用的浪潮”。
今年中国团队再次获得ACL最高荣誉,但光芒的背后,是一步一步的扎实积累。“最近几年华人在NLP领域的进步是非常大的。在15年的时候,对于一家中国研究机构来说,可能一年中一篇ACL,就是非常了不起的事情。随着时代的进步,华人的名字开始越来越多地出现在会议上,这是一个可喜的进步。相信在不久的将来,华人也可以做出很多可以引领整个时代潮流的工作。”许晶晶说道。
许晶晶对自然语言处理(NLP)的基础研究比较感兴趣,而词表又是自然语言处理的基础组件。
团队成员们非常尊重和支持她的个人研究兴趣,当她最开始提出想要研究词表的时候,很快就获得了团队成员们的支持。
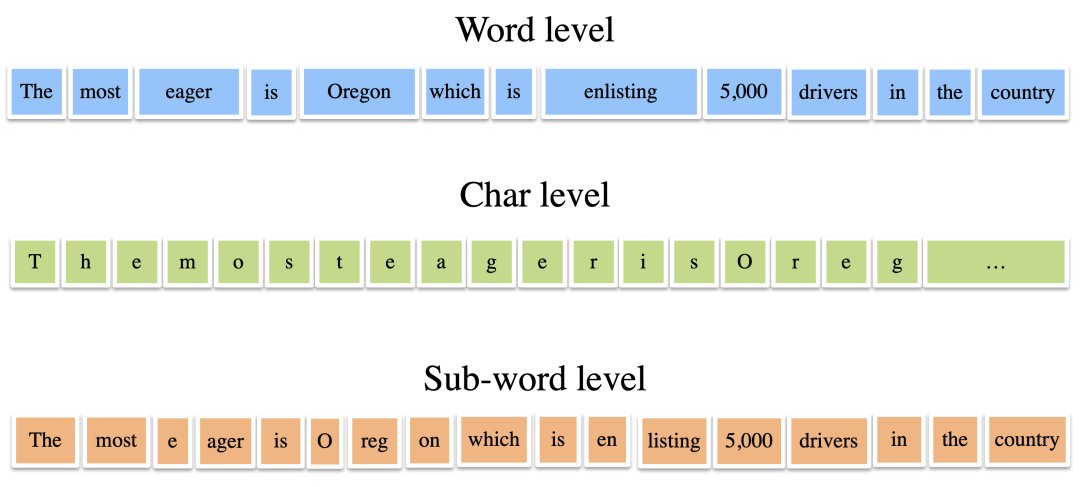
词表,也就是把句子拆分表示的参考表,有多种形式,比如词级别、字符级别、子词级别等等,如下图所示。
文章插图
在机器翻译架构中,这些句子在输入后会依据词表拆分成token(比如”Oregon“被拆分成“O”、“re”、“gon”三个token),然后将每个token分别表示为向量,再进行神经网络的编码、解码,然后先输出token级别的表示,再依据词表组合成完整的翻译句子输出。
在三种级别的词表中,词级别简单按照词汇水平对句子进行分割,对应的词表就是语料中所有的单词;字符级别把所有单词都拆分成字母。子词级别介于两者之间,比如在上图这句话中,”Oregon“被拆分成“O”、“re”、“gon”三个token,“enlisting”被拆分成“en”、“listing”。
- 浙江省|浙江的五大富豪,四位做过中国首富,仅马云的阿里就1年纳税366亿
- 运营商|信号走丢的锅该谁背?运营商:咱中国人别坑中国人……
- 人机|人机融合时代,中国机器人如何弯道超车
- |与任正非并称“二任”,把千亿公司给国家,堪称中国“并购之王”
- Python|联想真的没有问题?中国院士公布数据,胡锡进改变立场
- 显卡|中国供应链无可替代!美企提交超1700份意见,请求美国“免税”
- 科技日报|中国空间站首次太空授课将面向全球直播
- 传感器|认清差距!看清我国这三大技术短板,中国科技还需努力!
- 阿里巴巴|超过家乐福、沃尔玛,中国最大超市巨头诞生,大股东阿里亏损百亿
- 荣耀|产品力全面溢出 荣耀60系列将续写中国安卓机型Top1神话