|搅局GDC GTC AMD提前推出Instinct MI210加速器

文章图片

文章图片

文章图片
【锚思科技讯】本周将举行GDC和GTC , 英特尔和NVIDIA都会带来自己的全新GPU或相关技术 。 今天 , AMD也加入到了这场游戏当中 , 推出其MI200加速器系列的PCIe版本MI210 。
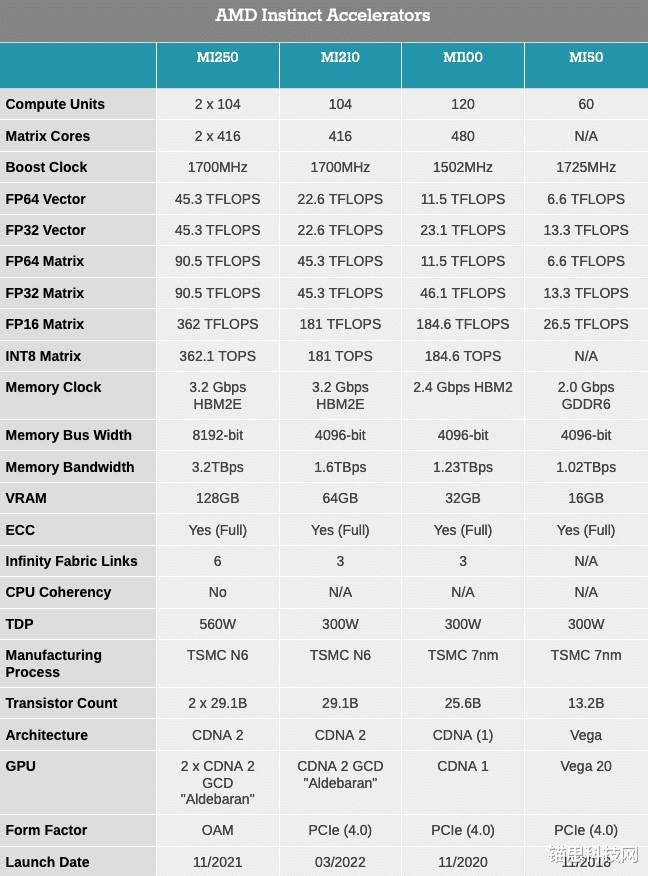
MI210是AMD最新一代基于GPU的加速器的第三个也是最后一个成员 , 它与MI250和MI250X一起在去年11月首次亮相 , 当时AMD推出了Instinct MI200系列 。 MI210将CDNA 2体系结构引入PCIe卡 , 面向那些追求MI200系列HPC和机器学习性能 , 但需要主流服务器标准化外形的客户 。 总体而言 , 作为AMD的一部分 , MI200今天被广泛推出 , 将整个MI200产品系列向OEM客户推广 。
从顶级规格开始 , MI210是现有MI250加速器的有趣变体 。 这两个部分是基于单个封装上MCM配置中的一对Aldebaran(CDNA 2)芯片 , 而对于MI210 , AMD正在将所有组件缩减为单个芯片和相关硬件 。 由于MI250(X)的OAM外形尺寸需要560W , AMD基本上需要将硬件减半 , 才能将PCIe卡的功耗降至300W 。 所以他们放弃了第二个封装芯片 。
最终的结果是 , 从物理硬件和预期性能来看 , MI210基本上是MI250的一半 。 CNDA 2图形计算芯片具有与MI250相同的104个CU , 芯片以1.7GHz的峰值时钟速度运行 。 因此 , 撇开工作负载可伸缩性不谈 , MI210的性能在所有实际用途上都是MI250的一半 。
随着MI250将64GB的HBM2e内存与每个GCD配对(总共128GB内存) , MI210将单个GCD的容量降至64GB 。 AMD在这里使用相同的3.2GHz HBM2e内存 , 因此该芯片的总体内存带宽为1.6 TB/秒 。
性能方面 , 使用一个Aldebaran芯片与AMD上一代PCIe卡Radeon MI100进行比较 。 虽然时钟更高 , 但相对于MI100 , CU的数量略有减少 , 这意味着对于某些工作负载 , 旧的加速器至少在纸面上要快一点 。 实际上 , MI210有更多的内存和更多的内存带宽 , 因此它应该仍然具有性能优势 。 在无法利用CDNA 2架构改进的工作负载中 , MI210不会比MI100高出太多 。
所有这些都强调了CDNA(1)和CDNA 2体系结构之间的整体相似性 , 以及开发人员需要如何利用CDNA 2的新功能来充分利用硬件 。 与CDNA(1)相比 , CDNA 2的亮点在于FP64载体工作负载、FP64基质工作负载和压缩FP32载体工作负载 。 AMD将其ALU的宽度增加了一倍 , 达到了64位的全宽 , 使FP64操作能够以全速处理 , 这三个用例都从中受益 。 同时 , 当FP32操作打包在一起以完全填充更宽的ALU时 , 它们也可以从新的ALU中受益 。
但是 , 正如我们在最初的MI250讨论中所指出的 , 与所有压缩指令格式一样 , 压缩FP32也不是轻而易举的 。 开发者需要编码来利用它;压缩操作数需要与偶数寄存器相邻并对齐 。 对于专门为体系结构(如Frontier)编写的软件 , 这是很容易做到的 , 但需要更新更多的可移植软件来考虑这一点 。 正是出于这个原因 , AMD明智地仍然在全速率(22.6 TFLOPS)下宣传其FP32矢量性能 , 而不是假设使用压缩指令 。
MI210的推出也标志着AMD将改进的矩阵核引入PCIe卡 。 对于CDNA 2 , 它们已经被扩展到允许全速FP64矩阵运算 , 使其达到与FP32矩阵运算相同的256次浮点运算的速率 , 比以前的64次浮点运算/时钟/CU速率提高了4倍 。
接下来 , PCIe格式的MI210还可以在卡的顶部获得三个Infinity Fabric 3.0链路 , 就像MI100一样 。 这允许MI210卡与一个或三个其他卡连接 , 形成一个2路或4路卡簇 。 同时 , 通过PCIe 4.0 x16连接提供到CPU或任何其他PCIe设备的回程 , 该连接由GCD的一个灵活IF链路供电 。
如前所述 , MI210的TDP设置为300W , 与之前的MI100和MI50相同 , 基本上是PCIe服务器卡的限制 。 与大多数服务器加速器一样 , 这是一种完全被动的双插槽卡设计 , 依靠服务器机箱的大量气流来降温 。 GPU本身由PCIe插槽和卡后部的8针EPS12V连接器的组合供电 。
除此之外 , 尽管外形因素发生了变化 , AMD仍在追求与MI250(X)大致相同的市场 。 也就是说 , 特别需要快速FP64加速器的HPC用户 。 由于MI200系列是一款首先为超级计算机(即Frontier)设计的芯片 , 其FP64矢量和FP64矩阵性能目前独树一帜 , 因为竞争对手的GPU专注于在大多数工业/非科学工作负载中使用的较低精度下提高性能 。 尽管精度较低 , 但MI200系列在FP16和BF16矩阵运算中的每CU 1024次失败率也不值得一提 。
- 雷军|雷军再次搅局暴利行业!生态链产品59元媲美飞利浦7000性能,网友:尴尬
- 壁纸|ColorOS在GDC上放大招:光追落地手机端,实时可交互的壁纸太可了
- 小米科技|继小米后,又一手机巨头悄然搅局智能家居领域,成家装界黑马!
- 笔记本|巨头搅局AI芯片
- 英伟达|今年GTC将送出八张NVIDIA首席执行官Jensen签名RTX3090显卡
- 小米科技|奥克斯“跨界”搅局!用29元高级保温杯“硬怼”小米,网友:干得真漂亮
- 显示器|三星S22安卓旗舰又成有力搅局者?同价位这三款也很有优势
- 乘用车|宁德时代搅局,谁才是里程焦虑最优解?丨氪金 · 新能源
- 游戏手机|红魔7发布会前瞻:5大亮点提前看,或要搅局游戏市场!
- 抖音|英伟达宣布GTC大会将于3月31日举办:届时推出“琥珀”GPU