参与者模块提供行动建议。参与者模块可以找到一个使估计的未来成本最小化的最佳行动序列,并在最佳序列中输出第一个行动,其方式类似于经典的最优控制。 - 短期记忆模块可以记录当前情况,预测世界状态,以及相关成本。
构建世界模型的一个关键挑战是如何使该模型能够表示多个模糊的预测。现实世界并不是完全可以预测的:一个特定的情况可能有多种演变的方式,并且许多与情况相关的细节与手头的任务无关。比如,我可能需要预测我开车时周围的汽车会做什么,但我不需要预测道路附近树木中个别叶子的详细位置。那么,世界模型如何学习现实世界的抽象表示,做到保留重要的细节、忽略不相关的细节,并且可以在抽象表示的空间中进行预测呢?
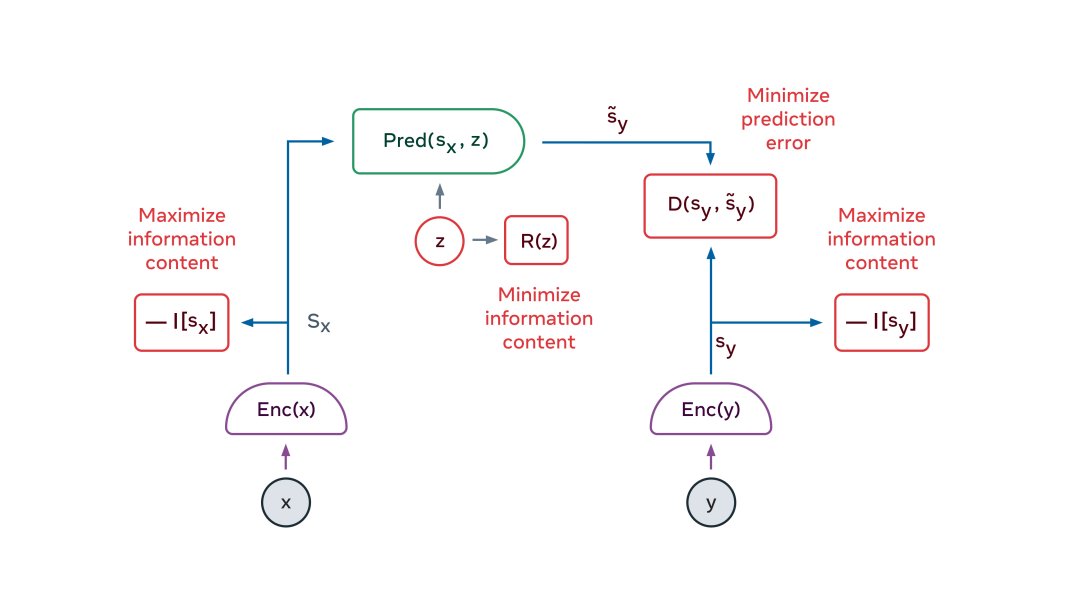
解决方案的一个关键要素是联合嵌入预测架构 (Joint Embedding Predictive Architecture ,JEPA)。JEPA 捕获两个输入(x 和 y)之间的依存关系。例如,x 可以是一段视频,y 可以是视频的下一段。输入 x 和 y 被馈送到可训练的编码器,这些编码器提取它们的抽象表示,即 sx 和 sy。预测器模块被训练为从 sx 预测 sy。预测器可以使用潜在变量 z 来表示 sy 中存在但 sx 中不存在的信息。JEPA 以两种方式处理预测中的不确定性:(1)编码器可能会选择丢弃难以预测的有关 y 的信息;(2)当潜在变量 z 在一个集合上变化时,将导致预测在一个集合上变化一组似是而非的预测。
那么,我们如何训练 JEPA 呢?
截至目前为止,研究者所使用的唯一方法就是“对比”,包括显示兼容 x 和 y 的示例,以及许多 x 和不兼容 y 的示例。但是当表示是高维状态时,这是相当不切实际的。
过去两年还出现了另一种训练策略:正则化方法。当应用于 JEPA 训练时,该方法使用了四个标准:
- 使 x 的表示最大限度地提供关于 x 的信息
- 使 y 的表示最大限度地提供关于 y 的信息
- 使 y 的表示可以从 x 的表示中最大程度地预测
- 使预测器使用尽可能少的潜在变量信息来表示预测中的不确定性
文章插图
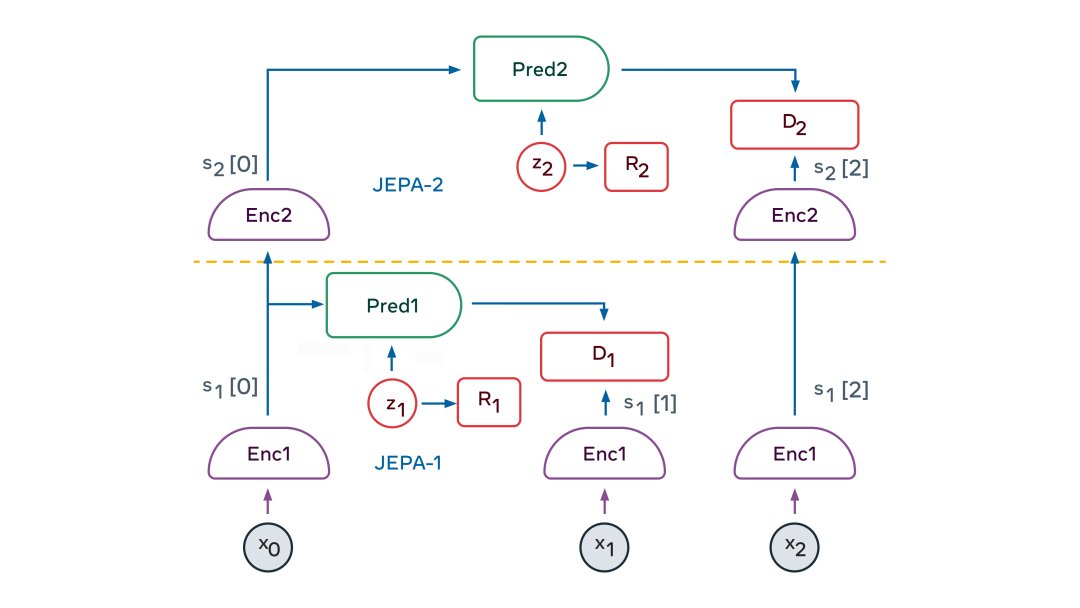
JEPA 的美妙之处在于它自然地产生了输入的信息抽象表示,消除了不相关的细节,并且可以执行预测。这使得 JEPA 可以相互堆叠,以便学习具有更高抽象级别的表示,可以进行长期预测。
例如,一个场景可以在高层次上描述为“厨师正在制作可丽饼”。它可以预测厨师会去取面粉、牛奶和鸡蛋,将食材混合,把面糊舀进锅里,将面糊油炸,并翻转可丽饼,然后不断重复该过程。在较低层次的表达上,这个场景可能是倒一勺面糊并舀均匀,且将其铺在锅周围。一直持续到每一毫秒的厨师的手的精确轨迹。在低层次的手部轨迹上,我们的世界模型只能进行短期的准确预测。但在更高的抽象层次上,它可以做出长期的预测。
文章插图
分层 JEPA 可用于在多个抽象级别和多个时间尺度上执行预测。训练方式主要是通过被动观察,很少通过互动。
婴儿在出生后的头几个月主要通过观察来了解世界是如何运作的。她了解到世界是三维的,知道有些物体会摆在其他物体的前面,当一个物体被遮挡时,它仍然存在。最终,在大约 9 个月大的时候,婴儿学会了直观的物理学——例如,不受支撑的物体会因重力而落下。
分层JEPA 的愿景在于它可以通过观看视频和与环境交互来了解世界是如何运作的。通过训练自己来预测视频中会发生什么,它可以生成对世界的分层表示。通过在世界上采取行动并观察结果,世界模型将学会预测其行动的后果,进而能够推理和计划。
- https|陈丹琦带着清华特奖学弟发布新成果:打破谷歌BERT提出的训练规律
- spec|KubeDL HostNetwork:加速分布式训练通信效率
- 大数据|深度学习也能不玩大数据?小企业训练大模型有新解
- 商汤|亚洲最大!上海“巨无霸”AI计算中心投用,支持万亿参数大模型训练
- gpu|亚洲最大!上海“巨无霸”AI计算中心投用,支持万亿参数大模型训练
- 推荐系统|真卷啊,快手和国外团队开源最大最新推荐系统Persia,人皆可训练
- 人工智能技术|登顶CLUE榜首,度小满“轩辕”刷新预训练模型纪录
- NVIDIA霸榜AI训练基准测试!三年性能涨超20倍
- r助力云端训练深度学习模型,亚马逊发布Trn1新实例
- 职业|初中毕业加1年经验,你就可以申报国家初级AI训练师了