C北大博士生提出CAE,下游任务泛化能力优于何恺明MAE( 二 )
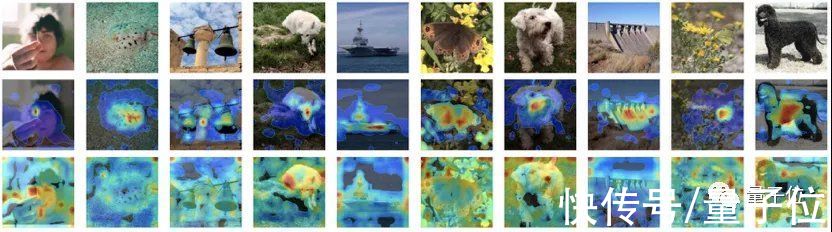
文章插图
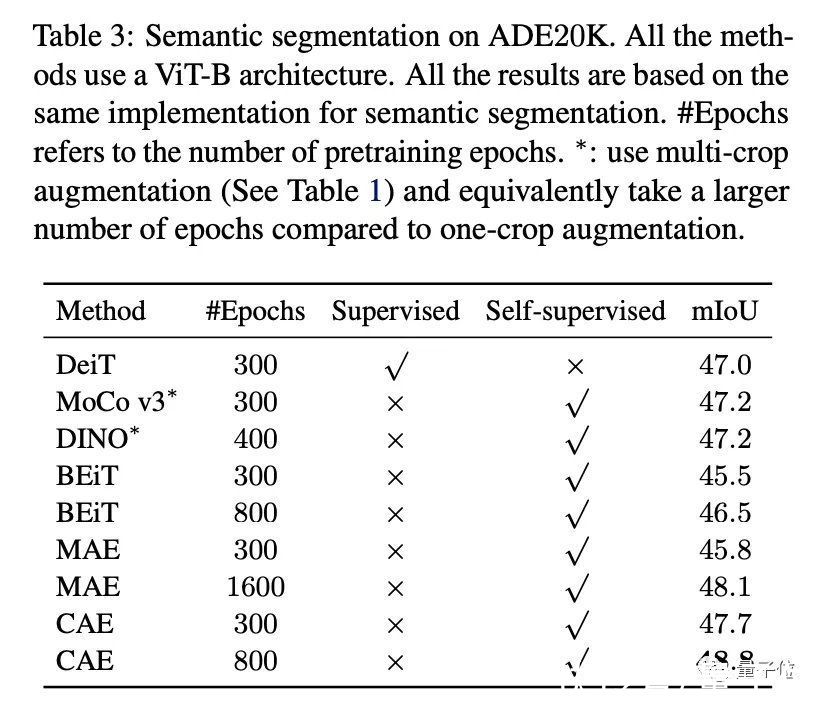
实验结果研究团队使用ViT-small和ViT-base在 ImageNet-1K 上进行实验,输入图像的分辨率224*224,每张图被分成14*14的patch,每个patch的大小为16*16。
每次将有75个patch被随机掩码,其余patch则为可见的。
本文参照BEiT,使用DALL-E tokenizer对输入图像token化,得到预测目标。
最终结果显示,在语义分割任务中,跟其他MIM方法,比如MAE、BEiT,以及对比学习、有监督预训练方法的表征结果更好。
文章插图
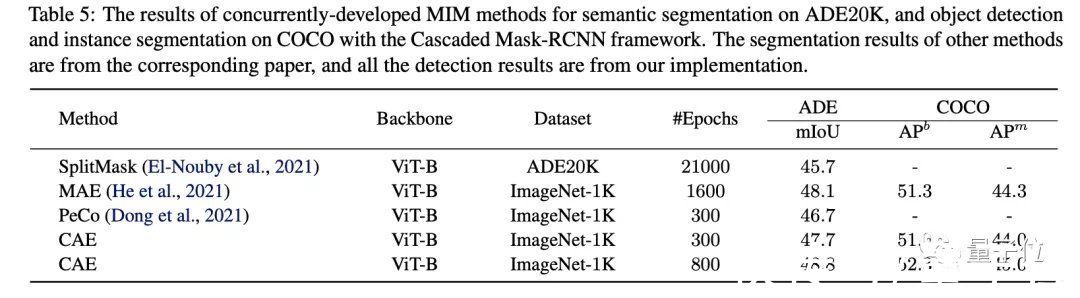
在物体检测、实例分割的结果也是如此。
文章插图
文章插图
百度CV大牛领衔本次研究由北京大学、香港大学、百度共同完成。
第一作者是在读博士生陈小康,来自北京大学机器感知与智能(教育部)重点实验室。
通讯作者是百度计算机视觉首席架构师王井东,同时也是IEEE Fellow。
在加盟百度之前,曾在微软亚研院视觉计算组担任首席研究员。

文章插图
感兴趣的旁友,可戳下方链接进一步查看论文~
论文链接:
https://arxiv.org/abs/2202.03026
— 完 —
量子位 QbitAI · 头条号签约
- MWC2022|无线网络如何更智能?华为提出IntelligentR 华为
- 硅谷|为什么去美国硅谷工作,成为很多清华北大毕业生的首选?
- 创新中心|集成电路高精尖创新中心在北京成立:依托北大、清华共同建设
- 科技日报|北大研究团队发现水星存在磁暴与环电流
- https|陈丹琦带着清华特奖学弟发布新成果:打破谷歌BERT提出的训练规律
- 软件|美国提出新法,要求软件市集业者不得限制App使用支付系统
- 中兴|中兴宣布全新代言人,同时提出三大消费电子品牌的全新规划
- 网红博主|品牌营销,从提出一个好问题开始
- 注意力流|AAAI2022丨创新奇智提出双注意力机制少样本学习 助力工业场景细粒度识别
- 服务业|曝青海某运营商提出“品质宽带”战略意在“千兆城市”所图甚远