深度学习?不一定非得搞“黑箱”
深度神经网络的参数网络极其庞大复杂,也因此让机器得以实现以往难以想象的各类功能。然而,这种复杂性也成为制约其广泛应用的祸根:神经网络的内部工作机理一直是个谜,就连创建者自己也搞不清它到底怎么做出决策。自深度学习在2010年初全面流行以来,这个难题一直困扰着人工智能业界。
随着深度学习在各个领域及应用中的拓展,人们对根据神经网络的结果以及学习到的参数组合来解释神经网络技术原理的兴致也越来越高。然而,这些解释方法往往并不靠谱,甚至充满种种误导性。更要命的是,这一切对于在训练过程中修复深度学习模型内的偏差/偏见几乎没有任何实际意义。
最近,《自然:机器智能》杂志发表了一篇经过同行评审的论文,杜克大学的科学家们在其中提出了“概念白化(concept whitening)”技术,希望在不牺牲性能的前提下引导神经网络学习特定概念。概念白化将可解释性引入深度学习模型,而不再由模型自主在数百万训练得出的参数中寻找答案。这项技术适用于卷积神经网络,展示出令人鼓舞的结果,亦有望为人工智能的未来发展及研究产生重大影响。
深度学习模型的特征与潜在空间
面对质量过硬的训练示例,拥有正确架构的深度学习模型应该有能力区分不同类型的输入素材。例如,在计算机视觉任务场景下,经过训练的神经网络能够将图像的像素值转换为相应的类别。(由于概念白化主要适用于图像识别,因此我们这里主要讨论机器学习任务的这一特定子集。当然,本文涉及的很多内容同样适用于整个深度学习领域。)
在训练期间,深度学习模型的每一层都会将训练图像的特征编码为一组数值,并将其存储在参数当中。这个过程,即AI模型的潜在空间。通常,多层卷积神经网络中的较低层负责学习基本特征,例如角度和边界。神经网络的较高层则学习检测更复杂的特征,例如人脸、物体、完整场景等。 
文章插图
图注:神经网络中的各层都会对输入图像中的特定特征进行编码。
在理想情况下,神经网络的潜在空间应代表与待检测图像类别相关的概念。但我们并不确定,因为深度学习模型往往倾向于学习最具区分性的特征——即使这些特征与结论并无因果关联。
例如,以下数据集中包含小猫的每一张图像,右下角都恰巧有个徽标。人类能够很快发现,徽标跟小猫没有任何关系。但深度学习模型却很可能选择取巧路线,即认定右下角有徽标的就是包含小猫的图像。同样的,如果训练集中所有包含绵羊的图像都有草地背景,那么神经网络学会的很可能是检测草地、而非绵羊。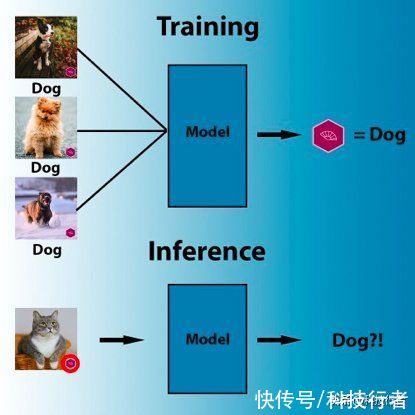
文章插图
图注:在训练期间,机器学习算法会搜索最容易将像素与标签关联起来的访问模式。
因此,除了深度学习模型在训练与测试数据集上的实际表现之外,更重要的是理解模型到底学会检测出哪些概念与特征。经典解释技术也正是从这个角度试图解决问题。
神经网络的事后解释
大部分深度学习解释技术都具有事后特性,意味着只能通过检查输出结果及参数值对经过训练的神经网络加以评估。例如,目前一种用于确定神经网络在图像中到底在观察哪些对象的流行技术,就尝试遮挡住输入图像中的不同部分,并观察这些变化会给深度学习模型的输出造成哪些影响。这项技术有助于创建热图,突出显示与神经网络相关度最高的各项图像特征。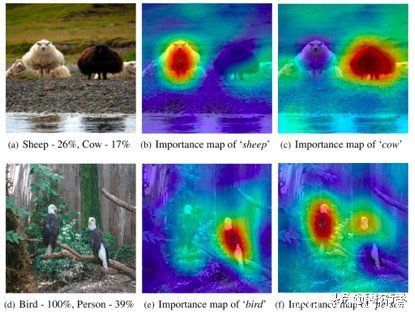
文章插图
图注:显著性图示例
其他事后技术还包括开启及关闭不同人工神经元,检查这些调整如何影响AI模型的输出。这些方法同样有助于找到相关特征与潜在空间之间的映射关系。
虽然这些方法效果不错,但本质上仍是在以“黑箱”形式看待深度学习模型,无法真正描绘出神经网络的确切情况。
白皮书作者写道,“「解释」方法通常属于性能的摘要统计信息(例如局部逼近、节点激活的总体趋势等),而非对模型计算的实际解释。”
例如,显著性图的问题在于,它们往往无法发现神经网络学习到错误信息的问题。当神经网络的特征分散在潜在空间中时,解释单一神经元的作用将变得极为困难。
文章插图
图注:显著性图解释,无法准确表示黑箱AI模型如何做出最终判断。
- mp4|Web前端培训:学习JavaScript重要知识点有哪些?
- find x|联发科的高端梦成了,深度解析Find X5,天玑9000真旗舰
- 淘宝|深度解析淘宝商品展示的底层逻辑,以及如何快速打上精准人群标签
- 抖音|学习“优爱腾”,抖音也要收费了
- 联想|性价比出众的联想小新平板,学习娱乐信手拈来
- Win10|仅1.2G的 win10深度精简版,比win7流畅,老旧机型首选!
- 华为|11张高清Python全知识地图,强烈建议收藏学习
- tiktok|Spotify学习TikTok,在线音乐平台为何“不务正业”
- |别瞧不起千元机,便宜不一定不好用,目前这3款手机足够使用了!
- 函数|Bengio 终于换演讲题目了!生成式主动学习如何让科学实验从寻找“一个分子”变为寻找“一类分子”?