如何做到性能翻倍 NVIDIA Ampere架构解析( 二 )
完整的GeForce RTX 3080核心
我们在发布会中经常听到性能翻倍的说法 , 其实是因为本次NVIDIAAmpere的SM在Turing基础上增加了一倍的FP32运算单元 , 这就使得每个SM的FP32运算单元数量提高了一倍 , 同时吞吐量也就变为了一倍 。
而通常我们计算显卡的CUDA数量 , 并不是把SM中的所有单元加起来计数 , 而是只统计FP32单元的数量 , 所以这样一来 , SM中的【FP32 : INT32】 从 1:1 变为 2:1 。
如RTX 3080的8704个CUDA , 其实它只有4352个INT32单元 , 但由于内部的FP32数量翻了一倍 , 所以最终实现了8704这个惊人的数字 。
而这样粗暴的提升CUDA数量对于游戏有帮助吗?答案是有 , 不仅有提升还很大 。 其实通常在游戏中浮点运算相比整数计算要常用的多 , 图形、算法以及各种计算操作中着色器工作负载通常需要混合使用FP32算数指令 , 而FP32的加速也有助于光线追踪降噪着色器 。
03第二代RT Core
 文章插图
文章插图
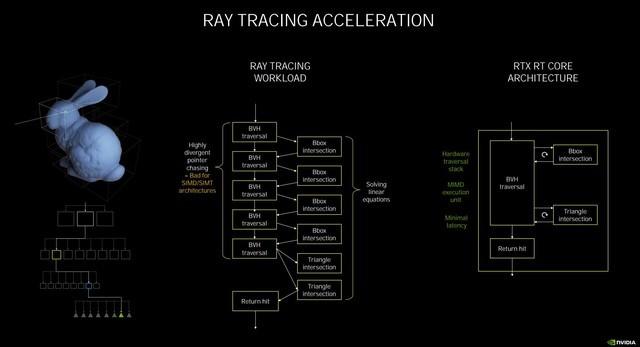
光追工作原理示意
在此次的NVIDIAAmpere架构中 , NVIDIA官方宣布为第二代RT Core , 它和第一代有什么不同呢 。 首先要知道RT Core的工作原理是 , 着色器发出光线追踪的请求 , 交给RT Core来处理 , 它将进行两种测试 , 分别为边界交叉测试(Box Intersection testing)和三角形交叉测试(Triangle Intersectiontesting) 。 基于BVH算法来判断 , 如果是方形 , 那么就返回缩小范围继续测试 , 如果是三角形 , 则反馈结果进行渲染 。
而光线追踪最耗时的正是求交计算 , 因此 , 要提升光线追踪性能 , 主要是对两种求交(BVH/三角形求交)进行加速 。
 文章插图
文章插图
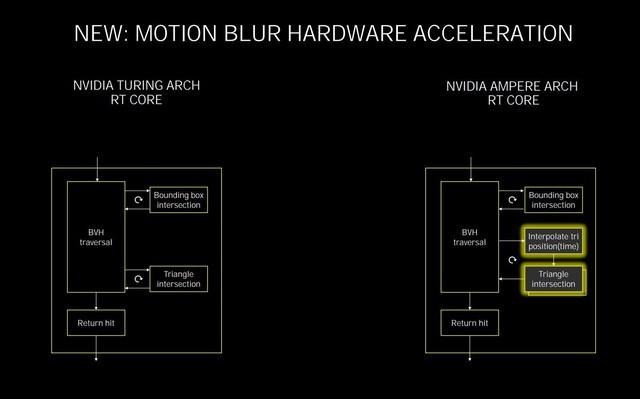
RT Core的变化
在Turing的RT Core中 , 可以每个周期完成5次BVH遍历、4次BVH求交以及一次三角形求交 , 在第二代RT Core 里 , NVIDIA增加了一个新的三角形位置插值模块以及一个的额外的三角形求交模块 , 这样做的目的是为了提升诸如运动模糊特效时候的光线追踪性能 。
 文章插图
文章插图
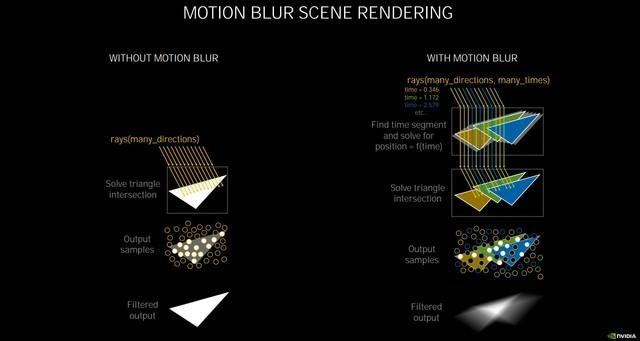
运动模糊渲染原理
第二代RT Core可以让光线追踪与着色同时进行 , 进行的光线追踪越多 , 加速就越快 , 它将光线相交的处理性能提升了一倍 , 在渲染有动态模糊的影像时 , 按照NVIDIA自己的实测 , 比Turing快8倍 。
04第三代Tensor Core
 文章插图
文章插图
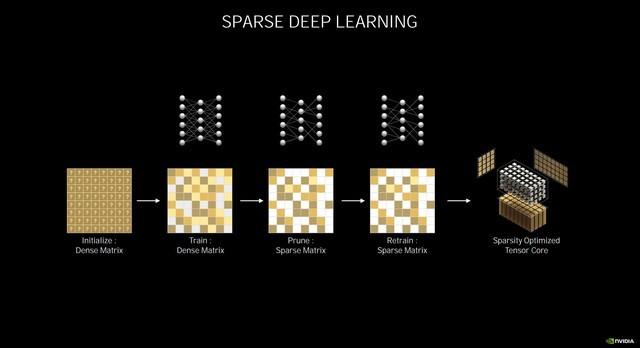
稀疏深度学习
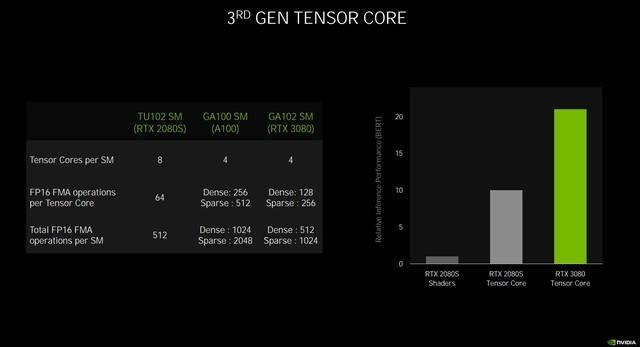
除了光线追踪的强化 , Ampere架构的Tensor Core也得到了极大地加强 , 在第三代Tensor Core中 , NVIDIA引入了稀疏化加速 , 可自动识别并消除不太重要的DNN(深度神经网络)权重 , 同时依然能保持不错的精度 。
首先原始的密集矩阵会经过训练 , 删除掉稀疏矩阵 , 再经过训练稀疏矩阵 , 从而实现稀疏优化 , 进而提高Tensor Core的性能 。
 文章插图
文章插图
第三代Tensor Core的处理能力大大提升
所以最终的结果就是Tensor Core在处理稀疏网络的速率是Turing的两倍 , 算力高达238 TensorTFLOPS , 而Turing为89 TensorTFLOPS 。
05RTX IO
与此次RTX 30系显卡一同发布的还有一项新技术——RTX IO 。 目前很多游戏动辄几十G甚至百G的安装空间 , 对于存储空间的负担暂且不提 , 但存放在硬盘中的数据 , 如果显卡想要读取到 , 需要先由CPU从硬盘中读取压缩过的数据 , 经过解压缩再发送到显存中 。
- 苹果两款新iPad齐曝光:性能提高、入门款更轻薄、售价便宜
- 红米K40渲染图曝光:居中挖孔+后置四摄,这外观你觉得如何?
- 发售仅7天,性能全国第一:华为、OV一起上,都不如这款手机?
- 传统1/10大小 七彩虹发布最小的mini SSD硬盘:性能首次公开
- 荣耀v40pro对比vivox60pro哪个好区别在哪 性能谁更强
- 奋斗|该如何看待拼多多员工猝死:鼓励奋斗,也要保护好奋斗者
- 装机点不亮 如何简易排查硬件问题?
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 华为nova8与小米10对比哪个好 参数配置区别性能评测
- 新型纯蓝OLED可克服目前显示屏蓝光性能不足的挑战