如何做到性能翻倍 NVIDIA Ampere架构解析
持续了一个月的“显卡发布季”已经告一段落 , 截止目前NVIDIA发布了GeForce RTX 3060 Ti/3070/3080/3090共4个型号的显卡 , 相比上一代显卡 , RTX 30系显卡再次做到了性能翻倍的神话 。 除了性能上的提升 , 新的NVIDIA Ampere架构还带来了第二代RT Core和第三代Tensor , 虽然RTX 30系显卡拥有诸多提升 , 但价格却与上一代显卡相同 , 在9月2日发布会当天 , 虽然过程仅有短短的40分钟 , 却震惊了全世界的用户 。
01算力提升
下面我们就来看看 , “有史以来最伟大性能提升”相比上一代的NVIDIA Turing架构 , 做了哪些提升 。
 文章插图
文章插图
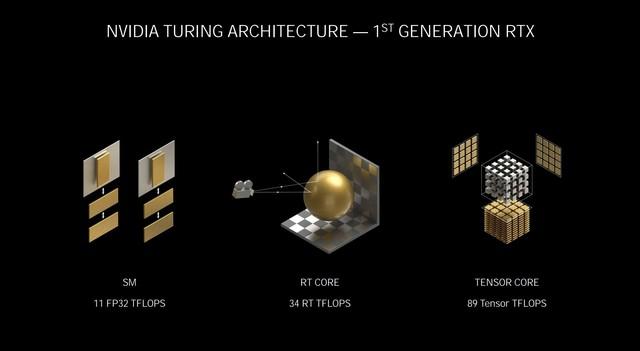
第一代RTX架构 Turing
 文章插图
文章插图
【如何做到性能翻倍 NVIDIA Ampere架构解析】第二代RTX架构 Ampere
首先来简单回顾一下在9月2日发布会的PPT上我们都看到了什么 , 相较于初代的Turing RTX架构 , NVIDIAAmpere架构在算力上有着成倍的增长 , 每个时钟执行2次着色器运算 , 而Turing为1次 , 着色器性能达到30 TFLOPS单精度性能 , 而Turing为11TFLOPS 。
NVIDIAAmpere架构翻倍了光线与三角形的相交吞吐量 , RT Core达到58 RTTFLOPS , 而Turing为34RT TFLOPS 。
另外在全新的Tensor Core中 , 可自动识别并消除不太重要的DNN权重 , 处理稀疏网络的速率是Turing的两倍 , 算力高达238 TensorTFLOPS , 而Turing为89 TensorTFLOPS 。
 文章插图
文章插图
芯片说明
全新的NVIDIAAmpere GPU核心拥有280亿个晶体管 , 628平方毫米的面积 , 基于三星的8nm NVIDIA定制工艺 , 来自美光的GDDR6X显存 , 以及我们上面说的 , 三大处理核心均为初代Turing的两倍速率 , 构成了有史以来性能最强大的Ampere 。
02SM单元的改变
而NVIDIAAmpere架构的强大性能并不是NVIDIA一蹴而就 , 可以说在20系显卡中所采用的Turing架构功不可没 , 下面我们先来看看完整的GA102核心 。
 文章插图
文章插图
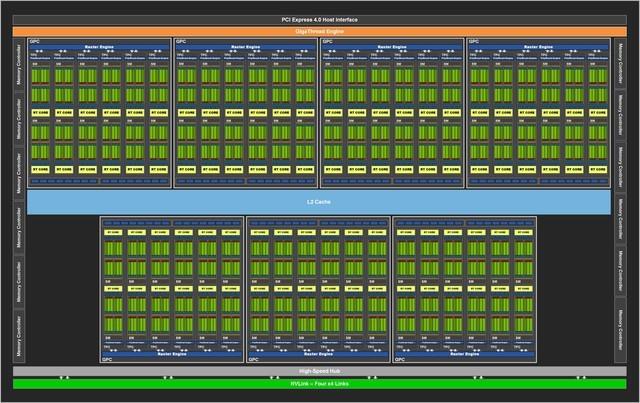
完整的GA102核心
完整的GA102 GPU包含7个GPC(图形处理集群)42个TPC(纹理处理集群)以及84个SM(流处理器)组成 。 GPC是占据主导地位的高级模块 , 拥有所有的关键图形处理单元 , 每个GPC包含一个专用光栅引擎 。 在新的NVIDIA Ampere架构中 , 每个GPC还包含了两个ROP分区 , 每个分区包含8个ROP单元 。 下面我们来看看每个SM单元的变化 。
 文章插图
文章插图
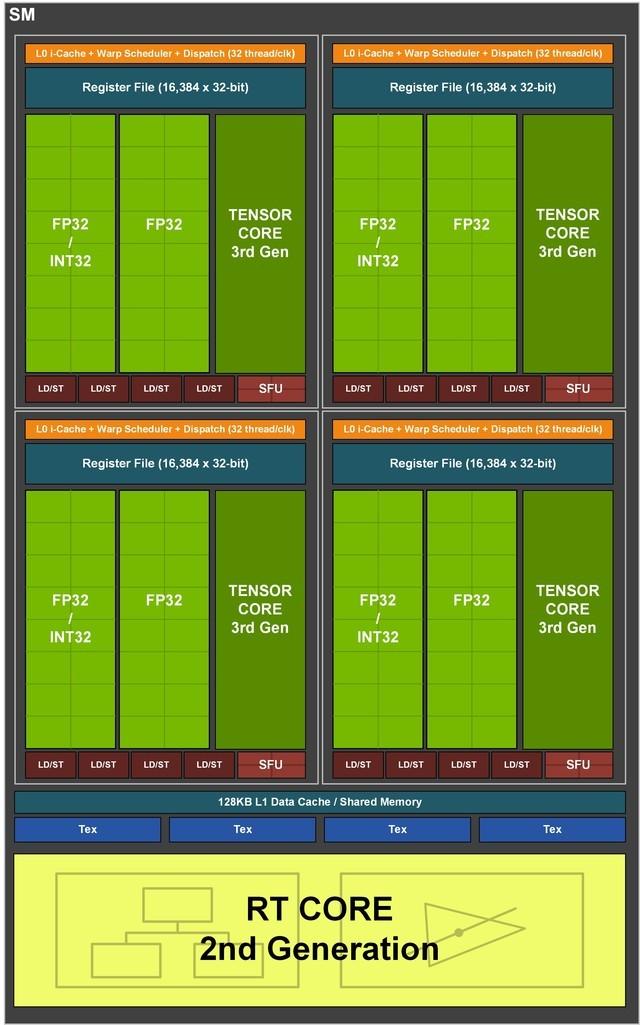
SM详解
在每个SM中 , 包含四个大的处理分区共128个CUDA核心 , 4个第三代Tensor Core , 1个第二代RT Core , 1个256 KB的缓存文件 , 1个128 KB的L1缓存 , 这个L1缓存可以根据不同的工作需求来调配缓存 , 工作效率发挥至最大 。
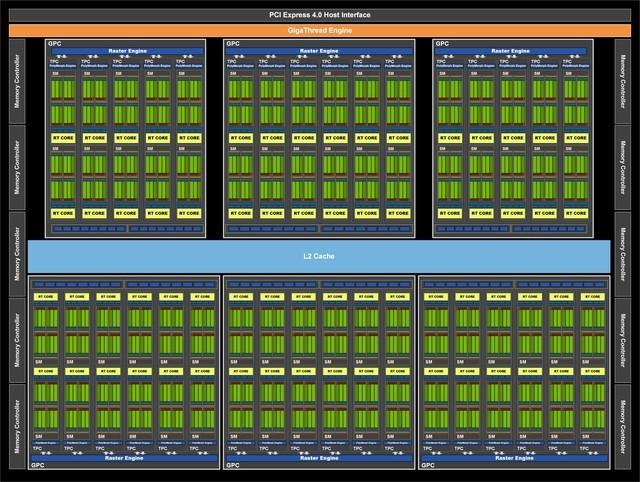
另外大家都知道本次RTX 3080的CUDA数量暴增至8704个 , 而RTX 3090的CUDA数量更是达到了惊人的10496个 , 但是大家要知道专业计算卡Tesla A100的GA100核心 , 拥有更大的核心面积 , 更多的晶体管数量 , 理论上只有8192个CUDA , 那RTX 3080又是如何达到这种效果的呢?
其实是因为本次NVIDIAAmpere的SM在Turing基础上增加了一倍的FP32运算单元 , 这就使得每个SM的FP32运算单元数量提高了一倍 。
 文章插图
文章插图
- 苹果两款新iPad齐曝光:性能提高、入门款更轻薄、售价便宜
- 红米K40渲染图曝光:居中挖孔+后置四摄,这外观你觉得如何?
- 发售仅7天,性能全国第一:华为、OV一起上,都不如这款手机?
- 传统1/10大小 七彩虹发布最小的mini SSD硬盘:性能首次公开
- 荣耀v40pro对比vivox60pro哪个好区别在哪 性能谁更强
- 奋斗|该如何看待拼多多员工猝死:鼓励奋斗,也要保护好奋斗者
- 装机点不亮 如何简易排查硬件问题?
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 华为nova8与小米10对比哪个好 参数配置区别性能评测
- 新型纯蓝OLED可克服目前显示屏蓝光性能不足的挑战