爱可可AI论文推介(10月9日)
AI - 人工智能 LG - 机器学习 CV - 计算机视觉 CL - 计算与语言
1、[CV]*Contrastive Learning of Medical Visual Representations from Paired Images and Text
Y Zhang, H Jiang, Y Miura, C D. Manning, C P. Langlotz
[Stanford University]
用无监督对比学习方法(ConVIRT)从图像-文本对学习医学视觉表示 , 用图像表示与文本数据两模态间的双向对比目标 , 进行医学图像编码器的预训练 , ConVIRT是领域不可知(domain-agnostic)的 , 无需额外的专家输入 。 在4个医学图像分类任务和2个图像检索任务中 , ConVIRT的表现优于其他同样使用文本数据的强域内初始化方法 , 表示质量显著提高 。 与ImageNet预训练相比 , ConVIRT能以更少的标记数据实现同水平的分类精度 。
Learning visual representations of medical images is core to medical image understanding but its progress has been held back by the small size of hand-labeled datasets. Existing work commonly relies on transferring weights from ImageNet pretraining, which is suboptimal due to drastically different image characteristics, or rule-based label extraction from the textual report data paired with medical images, which is inaccurate and hard to generalize. We propose an alternative unsupervised strategy to learn medical visual representations directly from the naturally occurring pairing of images and textual data. Our method of pretraining medical image encoders with the paired text data via a bidirectional contrastive objective between the two modalities is domain-agnostic, and requires no additional expert input. We test our method by transferring our pretrained weights to 4 medical image classification tasks and 2 zero-shot retrieval tasks, and show that our method leads to image representations that considerably outperform strong baselines in most settings. Notably, in all 4 classification tasks, our method requires only 10% as much labeled training data as an ImageNet initialized counterpart to achieve better or comparable performance, demonstrating superior data efficiency.
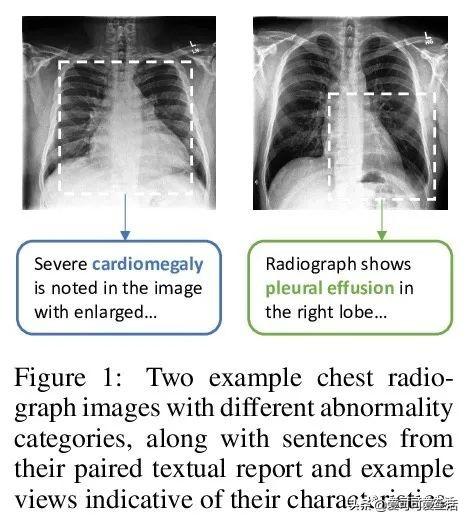 文章插图
文章插图
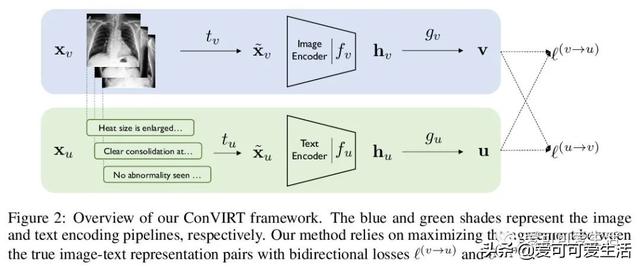 文章插图
文章插图
 文章插图
文章插图
2、[CL]Autoregressive Entity Retrieval
N D Cao, G Izacard, S Riedel, F Petroni
[University of Amsterdamii) a large memory footprint is needed to store dense representations when considering large entity sets; iii) an appropriately hard set of negative data has to be subsampled at training time. We propose GENRE, the first system that retrieves entities by generating their unique names, left to right, token-by-token in an autoregressive fashion, and conditioned on the context. This enables to mitigate the aforementioned technical issues: i) the autoregressive formulation allows us to directly capture relations between context and entity name, effectively cross encoding both; ii) the memory footprint is greatly reduced because the parameters of our encoder-decoder architecture scale with vocabulary size, not entity count; iii) the exact softmax loss can be efficiently computed without the need to subsample negative data. We show the efficacy of the approach with more than 20 datasets on entity disambiguation, end-to-end entity linking and document retrieval tasks, achieving new SOTA, or very competitive results while using a tiny fraction of the memory of competing systems. Finally, we demonstrate that new entities can be added by simply specifying their unambiguous name.
- 谷歌:想发AI论文?请保证写的是正能量
- 谷歌对内部论文进行“敏感问题”审查!讲坏话的不许发
- 2019年度中国高质量国际科技论文数排名世界第二
- 谷歌通过启动敏感话题审查来加强对旗下科学家论文的控制
- Arxiv网络科学论文摘要11篇(2020-10-12)
- 聚焦城市治理新方向,5G+智慧城市推介会在长举行
- 中国移动5G新型智慧城市全国推介会在长沙举行
- 年年都考的数字鸿沟有了新进展?彭波老师的论文给出了解答!
- 打开深度学习黑箱,牛津大学博士小姐姐分享134页毕业论文
- 兰州科技大市场牵线搭台,6项兰州大学科技成果在兰推介