打开深度学习黑箱,牛津大学博士小姐姐分享134页毕业论文
 文章插图
文章插图
作者 | 青暮
深度神经网络在计算机视觉、自然语言处理和语音识别等领域读取得了革命性成功 。 但是 , 这些模型的决策过程通常无法解释 。
不可解释性制约着深度学习方法的结构化和研究创新性 , 在实际应用中调参往往占据了很大的工作量 , 让人不明其创新所在的调参型研究论文充斥着深度学习社区 。 此外在模型失效或出现偏见等问题时 , 不可解释性也会导致高成本的修复工作 。
深度学习模型通常只能将多个变量进行关联 , 而无法理解背后的机制 , 这会导致因果关系的模糊性 。 而确定因果关系 , 对于医疗、金融或法律等领域至关重要 。 在近年来 , 深度学习的可解释性也越来越受到学界和业界的重视 。
近日 , 一篇134页的博士论文《Explaining Deep Neural Networks》受到了广泛的关注 , 作者Oana-Maria Camburu在论文中介绍了不同类型的神经网络解释方法 , 即事后解释和自解释 , 并对两种方法进行了分析和验证 , 并表示“这项工作为获得更鲁棒的神经模型以及对它们预测的可信解释铺平了道路 。 ”
 文章插图
文章插图
论文地址:
第一个方向是基于特征的事后(post-hoc)解释方法 , 即旨在解释已经训练和固定的模型的方法(事后解释) , 并提供输入特征方面的解释 , 例如文本的token、图像的超像素(基于特征) 。
 文章插图
文章插图
图注:两个解释器给出至少两个基于特征的解释的示例 。 其中假设得分线性反映情绪强度 , 且0.1的差距是显著的 。
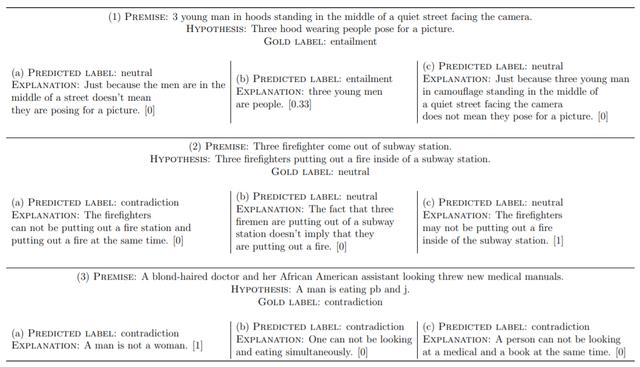
第二个方向是生成自然语言解释的自解释(self-explanatory)神经模型 , 即具有内置模块的模型 , 该模块生成对模型预测的解释 。
 文章插图
文章插图
图注:(a)BiLSTMMax-PredExpl , (b)BiLSTM-Max-ExplPred-Seq2Seq和(c)BiLSTMMax-ExplPred-Att的预测标签和生成解释的示例 , 方括号中为正确性得分 。
1 论文成果
通过这两个方向的探索 , 作者首先揭示了仅使用输入特征来解释即便是简单模型的某些困难 。
尽管明显地隐含了一个假设 , 即解释方法应该寻找一种基于事实的特定解释 , 但对于某个预测而言 , 通常会有不止一种这样的解释 。
此外 , 两种流行的解释方法针对不同类型的事实解释 , 但却没有明确提及 。 而且 , 有时这些解释都不足以提供有关实例决策过程的完整视图 。
第二 , 作者介绍了一个用于自动验证真实性的框架 , 基于特征的事后解释方法可用来描述其旨在解释的模型的决策过程 。
该框架依赖于特定类型的模型 , 该模型有望提供对其决策过程的深入了解 。 作者分析了这种方法的潜在局限性 , 并介绍了缓解这些局限性的方法 。
作者引入的验证框架是通用的 , 可以在不同的任务和域上实例化以提供现成的健全性测试(sanity test) , 可用于测试基于特征的事后解释方法 。
作者在情感分析任务上实例化了此框架 , 并提供了健全性测试 , 在该测试中 , 作者展示了三种流行的解释方法的性能 。
第三 , 为了探索生成自解释神经模型的方向(模型为预测提供自然语言解释) , 作者在斯坦福自然语言推理(SNLI)数据集之上收集了约570K的人类书面自然语言解释的大型数据集 。 作者将该解释增强的数据集称为e-SNLI 。
 文章插图
文章插图
图注:e-SNLI数据集的示例 。 注释中提供了前提、假设和标签 , 强调了对标签至关重要的词语 , 并提供了解释 。
- 假期弯道超车 国美学习“神器”助孩子变身“学霸”
- 拜拜扫描仪!微信打开这个功能,文档表格扫一扫秒变电子档
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- Google AI建立了一个能够分析烘焙食谱的机器学习模型
- 日本工程师:潘多拉魔盒被美国打开,中国办芯片大学只为打破禁令
- 开会再也不用手写,微信打开这个设置,会议纪要一键生成
- 学习大数据是否需要学习JavaEE
- 美国媒体:潘多拉魔盒被中国打开,韩国这项科技超越中国问鼎全球
- 学习“时代楷模”精神 信息科技创新助跑5G智慧港口