网易数据湖探索与实践( 四 )
 文章插图
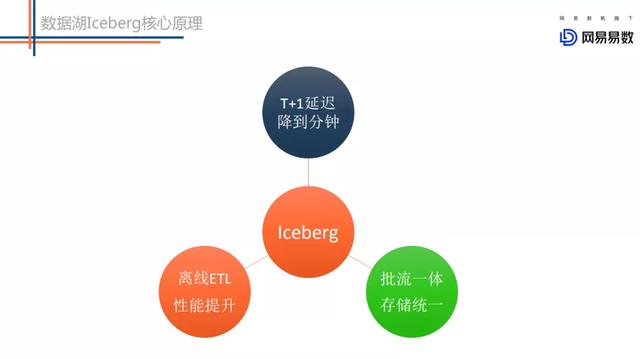
文章插图03
数据湖Iceberg社区现状
 文章插图
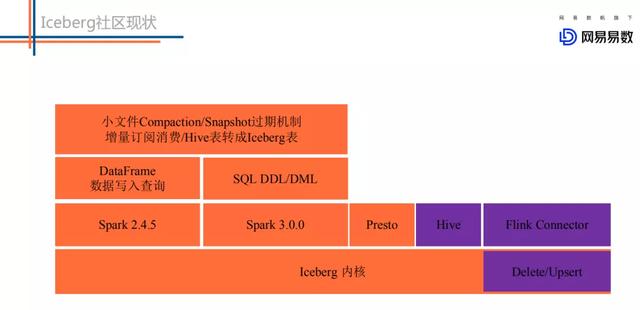
文章插图目前Iceberg主要支持的计算引擎包括Spark2.4.5、Spark 3.x以及Presto 。 同时 , 一些运维工作比如snapshot过期、小文件合并、增量订阅消费等功能都可以实现 。
在此基础上 , 目前社区正在开发的功能主要有Hive集成、Flink集成以及支持Update/Delete功能 。 相信下一个版本就可以看到Hive/Flink集成的相关功能 。
04
网易数据湖Iceberg实践之路
 文章插图
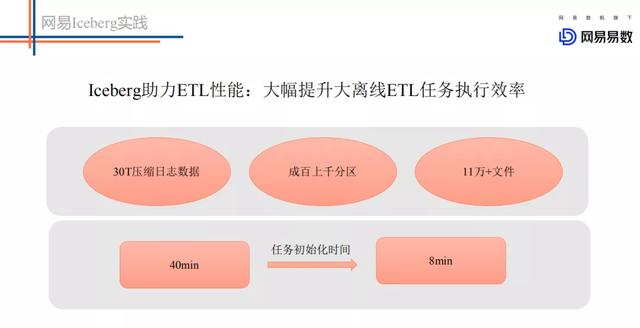
文章插图Iceberg针对目前的大数量的情况下 , 可以大大提升ETL任务执行的效率 , 这主要得益于新Partition模式下不再需要请求NameNode分区信息 , 同时得益于文件级别统计信息模式下可以过滤很多不满足条件的数据文件 。
 文章插图
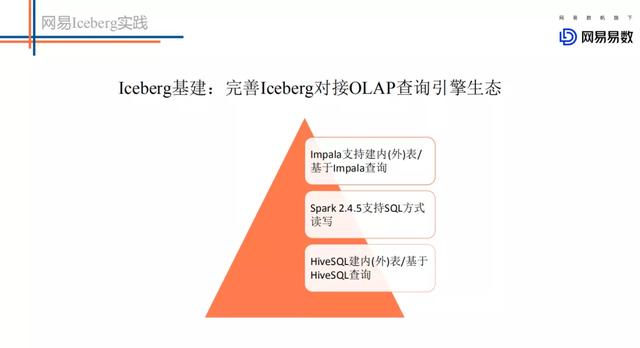
文章插图当前iceberg社区仅支持Spark2.4.5 , 我们在这个基础上做了更多计算引擎的适配工作 。 主要包括如下:
- 集成Hive 。 可以通过Hive创建和删除iceberg表 , 通过HiveSQL查询Iceberg表中的数据 。
- 集成Impala 。 用户可以通过Impala新建iceberg内表\外表 , 并通过Impala查询Iceberg表中的数据 。 目前该功能已经贡献给Impala社区 。
- 集成Flink 。 已经实现了Flink到Iceberg的sink实现 , 业务可以消费kafka中的数据将结果写入到Iceberg中 。 同时我们基于Flink引擎实现了小文件异步合并的功能 , 这样可以实现Flink一边写数据文件 , 一边执行小文件的合并 。 基于Iceberg的小文件合并通过commit的方式提交 , 不需要删除合并前的小文件 , 也就不会引起读取任务的任何异常 。
- 网易云音乐上线“一键迁移”虾米歌单功能:还免费送3个月黑胶VIP
- 虾米音乐别了!教你把虾米导入QQ音乐网易云音乐
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 虾米音乐活跃用户一千万不到,QQ音乐、网易云音乐花式抢客
- 虾米音乐歌单可导入QQ音乐、网易云音乐 方法这
- 市科委与联影集团联合首设“探索者计划”,共推基础及应用基础研究
- 美的探索工业互联网+5G+AI应用场景,成本可降低10%
- 网易数帆亮相中台战略大会,解读云原生软件生产力实践
- 聊聊网易云音乐:“心动模式”
- 小姐姐带你探索萌粉电竞显示器的秘密