网易数据湖探索与实践( 三 )
- 表schema定义了一个表支持字段类型 , 比如int、string、long以及复杂数据类型等 。
- 表中文件组织形式最典型的是Partition模式 , 是Range Partition还是Hash Partition 。
- Metadata数据统计信息 。
- 封装了表的读写API 。 上层引擎通过对应的API读取或者写入表中的数据 。
① 在schema层面上没有任何区别:
 文章插图
文章插图都支持int、string、bigint等类型 。
② partition实现完全不同:
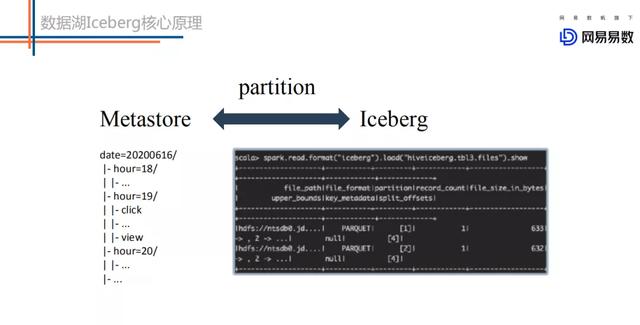 文章插图
文章插图两者在partition上有很大的不同:
metastore中partition字段不能是表字段 , 因为partition字段本质上是一个目录结构 , 不是用户表中的一列数据 。 基于metastore , 用户想定位到一个partition下的所有数据 , 首先需要在metastore中定位出该partition对应的所在目录位置信息 , 然后再到HDFS上执行list命令获取到这个分区下的所有文件 , 对这些文件进行扫描得到这个partition下的所有数据 。
iceberg中partition字段就是表中的一个字段 。 Iceberg中每一张表都有一个对应的文件元数据表 , 文件元数据表中每条记录表示一个文件的相关信息 , 这些信息中有一个字段是partition字段 , 表示这个文件所在的partition 。
很明显 , iceberg表根据partition定位文件相比metastore少了一个步骤 , 就是根据目录信息去HDFS上执行list命令获取分区下的文件 。
试想 , 对于一个二级分区的大表来说 , 一级分区是小时时间分区 , 二级分区是一个枚举字段分区 , 假如每个一级分区下有30个二级分区 , 那么这个表每天就会有24 * 30 = 720个分区 。 基于Metastore的partition方案 , 如果一个SQL想基于这个表扫描昨天一天的数据的话 , 就需要向Namenode下发720次list请求 , 如果扫描一周数据或者一个月数据 , 请求数就更是相当夸张 。 这样 , 一方面会导致Namenode压力很大 , 一方面也会导致SQL请求响应延迟很大 。 而基于Iceberg的partition方案 , 就完全没有这个问题 。
③ 表统计信息实现粒度不同:
 文章插图
文章插图Metastore中一张表的统计信息是表/分区级别粒度的统计信息 , 比如记录一张表中某一列的记录数量、平均长度、为null的记录数量、最大值\最小值等 。
Iceberg中统计信息精确到文件粒度 , 即每个数据文件都会记录所有列的记录数量、平均长度、最大值\最小值等 。
很明显 , 文件粒度的统计信息对于查询中谓词(即where条件)的过滤会更有效果 。
④ 读写API实现不同:
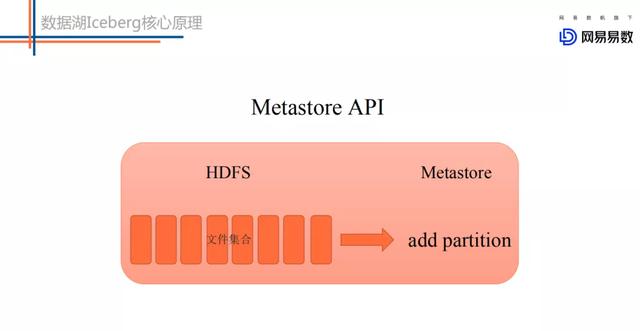 文章插图
文章插图metastore模式下上层引擎写好一批文件 , 调用metastore的add partition接口将这些文件添加到某个分区下 。
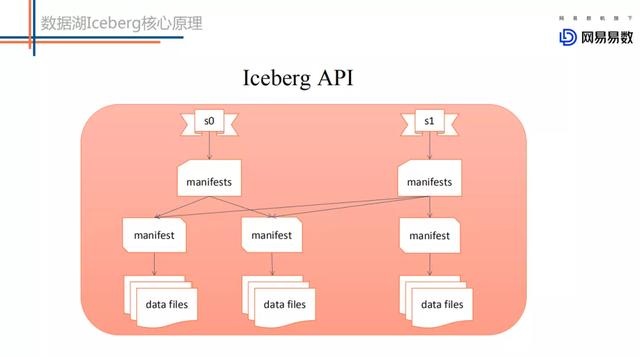 文章插图
文章插图Iceberg模式下上层业务写好一批文件 , 调用iceberg的commit接口提交本次写入形成一个新的snapshot快照 。 这种提交方式保证了表的ACID语义 。 同时基于snapshot快照提交可以实现增量拉取实现 。
总结下Iceberg相对于Metastore的优势:
- 新partition模式:避免了查询时n次调用namenode的list方法 , 降低namenode压力 , 提升查询性能
- 网易云音乐上线“一键迁移”虾米歌单功能:还免费送3个月黑胶VIP
- 虾米音乐别了!教你把虾米导入QQ音乐网易云音乐
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 虾米音乐活跃用户一千万不到,QQ音乐、网易云音乐花式抢客
- 虾米音乐歌单可导入QQ音乐、网易云音乐 方法这
- 市科委与联影集团联合首设“探索者计划”,共推基础及应用基础研究
- 美的探索工业互联网+5G+AI应用场景,成本可降低10%
- 网易数帆亮相中台战略大会,解读云原生软件生产力实践
- 聊聊网易云音乐:“心动模式”
- 小姐姐带你探索萌粉电竞显示器的秘密