网易数据湖探索与实践
今天主要和大家交流的是网易在数据湖Iceberg的一些思考与实践 。 从网易在数据仓库建设中遇到的痛点出发 , 介绍对数据湖Iceberg的探索以及实践之路 。
【网易数据湖探索与实践】主要内容包括:
- 数据仓库平台建设的痛点
- 数据湖Iceberg的核心原理
- 数据湖Iceberg社区现状
- 网易数据湖Iceberg实践之路
数据仓库平台建设的痛点
痛点一:
 文章插图
文章插图我们凌晨一些大的离线任务经常会因为一些原因出现延迟 , 这种延迟会导致核心报表的产出时间不稳定 , 有些时候会产出比较早 , 但是有时候就可能会产出比较晚 , 业务很难接受 。
为什么会出现这种现象的发生呢?目前来看大致有这么几点要素:
- 任务本身要请求的数据量会特别大 。 通常来说一天原始的数据量可能在几十TB 。 几百个分区 , 甚至上千个分区 , 五万+的文件数这样子 。 如果说全量读取这些文件的话 , 几百个分区就会向NameNode发送几百次请求 , 我们知道离线任务在凌晨运行的时候 , NameNode的压力是非常大的 。 所以就很有可能出现Namenode响应很慢的情况 , 如果请求响应很慢就会导致任务初始化时间很长 。
- 任务本身的ETL效率是相对低效的 , 这个低效并不是说Spark引擎低效 , 而是说我们的存储在这块支持的不是特别的好 。 比如目前我们查一个分区的话是需要将所有文件都扫描一遍然后进行分析 , 而实际上我可能只对某些文件感兴趣 。 所以相对而言这个方案本身来说就是相对低效的 。
- 这种大的离线任务一旦遇到磁盘坏盘或者机器宕机 , 就需要重试 , 重试一次需要耗费很长的时间比如几十分钟 。 如果说重试一两次的话这个延迟就会比较大了 。
 文章插图
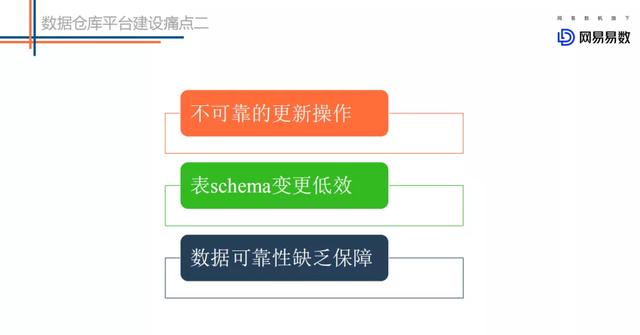
文章插图针对一些细琐的一些问题而言的 。 这里简单列举了三个场景来分析:
- 不可靠的更新操作 。 我们经常在ETL过程中执行一些insert overwrite之类的操作 , 这类操作会先把相应分区的数据删除 , 再把生成的文件加载到分区中去 。 在我们移除文件的时候 , 很多正在读取这些文件的任务就会发生异常 , 这就是不可靠的更新操作 。
- 表Schema变更低效 。 目前我们在对表做一些加字段、更改分区的操作其实是非常低效的操作 , 我们需要把所有的原始数据读出来 , 然后在重新写回去 。 这样就会非常耗时 , 并且低效 。
- 数据可靠性缺乏保障 。 主要是我们对于分区的操作 , 我们会把分区的信息分为两个地方 , HDFS和Metastore , 分别存储一份 。 在这种情况下 , 如果进行更新操作 , 就可能会出现一个更新成功而另一个更新失败 , 会导致数据不可靠 。
 文章插图
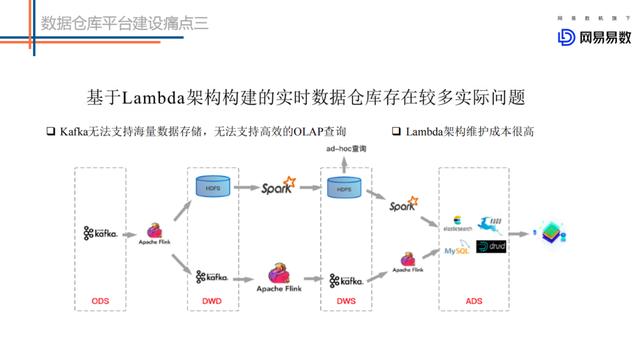
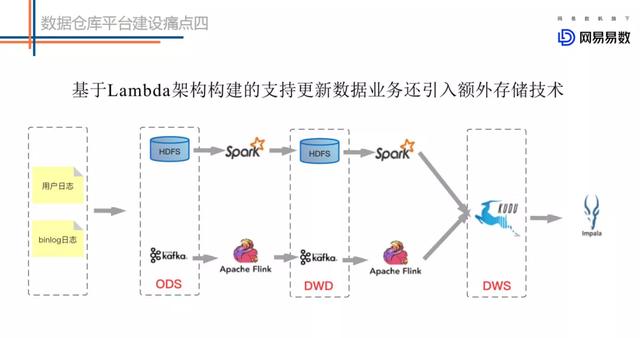
文章插图基于Lambda架构建设的实时数仓存在较多的问题 。 如上图的这个架构图 , 第一条链路是基于Kafka中转的一条实时链路(延迟要求小于5分钟) , 另一条是离线链路(延迟大于1小时) , 甚至有些公司会有第三条准实时链路(延迟要求5分钟~一小时) , 甚至更复杂的场景 。
- 两条链路对应两份数据 , 很多时候实时链路的处理结果和离线链路的处理结果对不上 。
- Kafka无法存储海量数据 ,无法基于当前的OLAP分析引擎高效查询Kafka中的数据 。
- Lambda维护成本高 。 代码、数据血缘、Schema等都需要两套 。 运维、监控等成本都非常高 。
 文章插图
文章插图
- 网易云音乐上线“一键迁移”虾米歌单功能:还免费送3个月黑胶VIP
- 虾米音乐别了!教你把虾米导入QQ音乐网易云音乐
- 虾米音乐宣布关停!我的歌单如何导入QQ音乐、网易云音乐?
- 虾米音乐活跃用户一千万不到,QQ音乐、网易云音乐花式抢客
- 虾米音乐歌单可导入QQ音乐、网易云音乐 方法这
- 市科委与联影集团联合首设“探索者计划”,共推基础及应用基础研究
- 美的探索工业互联网+5G+AI应用场景,成本可降低10%
- 网易数帆亮相中台战略大会,解读云原生软件生产力实践
- 聊聊网易云音乐:“心动模式”
- 小姐姐带你探索萌粉电竞显示器的秘密