使用Python进行异常检测
异常检测可以作为异常值分析的一项统计任务来处理 。 但是如果我们开发一个机器学习模型 , 它可以像往常一样自动化 , 可以节省很多时间 。
异常检测有很多用例 。 信用卡欺诈检测、故障机器检测或基于异常特征的硬件系统检测、基于医疗记录的疾病检测都是很好的例子 。 还有更多的用例 。 异常检测的应用只会越来越多 。
在本文中 , 我将解释在Python中从头开始开发异常检测算法的过程 。
公式和过程与我之前解释过的其他机器学习算法相比 , 这要简单得多 。 该算法将使用均值和方差来计算每个训练数据的概率 。
如果一个训练实例的概率很高 , 这是正常的 。 如果某个训练实例的概率很低 , 那就是一个异常的例子 。 对于不同的训练集 , 高概率和低概率的定义是不同的 。 我们以后再讨论 。
如果我要解释异常检测的工作过程 , 这很简单 。
- 使用以下公式计算平均值:
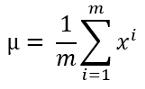 文章插图
文章插图这里m是数据集的长度或训练数据的数量 , 而$x^i$是一个单独的训练例子 。 如果你有多个训练特征 , 大多数情况下都需要计算每个特征能的平均值 。
- 使用以下公式计算方差:
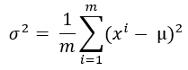 文章插图
文章插图这里 , mu是上一步计算的平均值 。
- 现在 , 用这个概率公式计算每个训练例子的概率 。
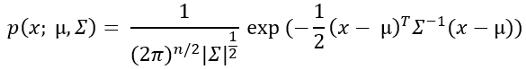 文章插图
文章插图不要被这个公式中的求和符号弄糊涂了!这实际上是Sigma代表方差 。
稍后我们将实现该算法时 , 你将看到它的样子 。
- 我们现在需要找到概率的临界值 。 正如我前面提到的 , 如果一个训练例子的概率很低 , 那就是一个异常的例子 。
这没有普遍的限制 。 我们需要为我们的训练数据集找出这个 。
我们从步骤3中得到的输出中获取一系列概率值 。 对于每个概率 , 通过阈值的设置得到数据是否异常
然后计算一系列概率的精确度、召回率和f1分数 。
精度可使用以下公式计算
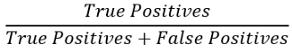 文章插图
文章插图召回率的计算公式如下:
文章插图在这里 , True positives(真正例)是指算法检测到一个异常的例子的数量 , 而它真实情况也是一个异常 。
False Positives(假正例)当算法检测到一个异常的例子 , 但在实际情况中 , 它不是异常的 , 就会出现误报 。
False Negative(假反例)是指算法检测到的一个例子不是异常的 , 但实际上它是一个异常的例子 。
从上面的公式你可以看出 , 更高的精确度和更高的召回率总是好的 , 因为这意味着我们有更多的真正的正例 。 但同时 , 假正例和假反例起着至关重要的作用 , 正如你在公式中看到的那样 。 这需要一个平衡点 。 根据你的行业 , 你需要决定哪一个对你来说是可以忍受的 。
一个好办法是取平均数 。 计算平均值有一个独特的公式 。 这就是f1分数 。 f1得分公式为:
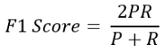 文章插图
文章插图这里 , P和R分别表示精确性和召回率 。
根据f1分数 , 你需要选择你的阈值概率 。
异常检测算法我将使用Andrew Ng的机器学习课程的数据集 , 它具有两个训练特征 。 我没有在本文中使用真实的数据集 , 因为这个数据集非常适合学习 。 它只有两个特征 。 在任何真实的数据集中 , 都不可能只有两个特征 。
- 想自学Python来开发爬虫,需要按照哪几个阶段制定学习计划
- 未来想进入AI领域,该学习Python还是Java大数据开发
- 或使用天玑1000+芯片?荣耀V40已全渠道开启预约
- 苹果将推出使用mini LED屏的iPad Pro
- 手机能用多久?如果出现这3种征兆,说明“默认使用时间”已到
- 微软|外媒:微软将对Windows 10界面进行彻底改进 已招兵买马
- Linux 5.11开始围绕PCI Express 6.0进行早期准备
- 苹果有望在2021年初发布首款使用mini LED显示屏的 iPad Pro
- AMP Robotics募资5500万美元 开发AI对可回收物进行分拣
- 笔记本保养有妙招!学会这几招笔记本再战三年