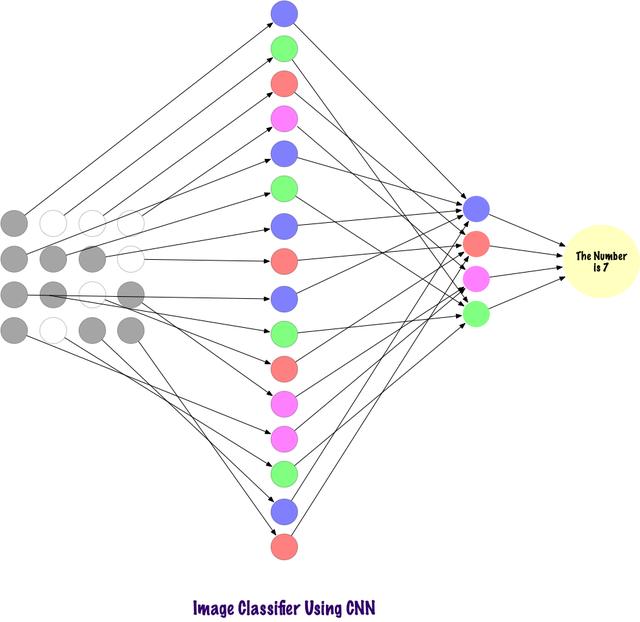
卷积使用稀疏连接的层 , 并且其输入可以是矩阵 , 优于MLP 。 输入特征连接到局部编码节点 。 在MLP中 , 每个节点都有能力影响整个网络 。 而CNN将图像分解为区域(像素的小局部区域) , 每个隐藏节点与输出层相关 , 输出层将接收的数据进行组合以查找相应的模式 。
 文章插图
文章插图
计算机如何查看输入的图像?看着图片并解释其含义 , 这对于人类来说很简单的一件事情 。 我们生活在世界上 , 我们使用自己的主要感觉器官(即眼睛)拍摄环境快照 , 然后将其传递到视网膜 。 这一切看起来都很有趣 。 现在让我们想象一台计算机也在做同样的事情 。
在计算机中 , 使用一组位于0到255范围内的像素值来解释图像 。 计算机查看这些像素值并理解它们 。 乍一看 , 它并不知道图像中有什么物体 , 也不知道其颜色 。 它只能识别出像素值 , 图像对于计算机来说就相当于一组像素值 。 之后 , 通过分析像素值 , 它会慢慢了解图像是灰度图还是彩色图 。 灰度图只有一个通道 , 因为每个像素代表一种颜色的强度 。 0表示黑色 , 255表示白色 , 二者之间的值表明其它的不同等级的灰灰色 。 彩色图像有三个通道 , 红色、绿色和蓝色 , 它们分别代表3种颜色(三维矩阵)的强度 , 当三者的值同时变化时 , 它会产生大量颜色 , 类似于一个调色板 。 之后 , 计算机识别图像中物体的曲线和轮廓 。。
下面使用PyTorch加载数据集并在图像上应用过滤器:
# Load the librariesimport torchimport numpy as npfrom torchvision import datasetsimport torchvision.transforms as transforms# Set the parametersnum_workers = 0batch_size = 20# Converting the Images to tensors using Transformstransform = transforms.ToTensor()train_data = http://kandian.youth.cn/index/datasets.MNIST(root='data', train=True, download=True, transform=transform)test_data = http://kandian.youth.cn/index/datasets.MNIST(root='data', train=False, download=True, transform=transform)# Loading the Datatrain_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, num_workers=num_workers)test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,num_workers=num_workers)import matplotlib.pyplot as plt%matplotlib inline dataiter = iter(train_loader)images, labels = dataiter.next()images = images.numpy()# Peeking into datasetfig = plt.figure(figsize=(25, 4))for image in np.arange(20): ax = fig.add_subplot(2, 20/2, image+1, xticks=[], yticks=[]) ax.imshow(np.squeeze(images[image]), cmap='gray') ax.set_title(str(labels[image].item())) 文章插图
文章插图
下面看看如何将单个图像输入神经网络中:
img = np.squeeze(images[7])fig = plt.figure(figsize = (12,12)) ax = fig.add_subplot(111)ax.imshow(img, cmap='gray')width, height = img.shapethresh = img.max()/2.5for x in range(width): for y in range(height): val = round(img[x][y],2) if img[x][y] !=0 else 0 ax.annotate(str(val), xy=(y,x), color='white' if img[x][y]上述代码将数字'3'图像分解为像素 。 在一组手写数字中 , 随机选择“3” 。 并且将实际像素值(0-255 )标准化 , 并将它们限制在0到1的范围内 。 归一化的操作能够加快模型训练收敛速度 。
构建过滤器
【输出层|PyTorch可视化理解卷积神经网络】过滤器 , 顾名思义 , 就是过滤信息 。 在使用CNN处理图像时 , 过滤像素信息 。 为什么需要过滤呢 , 计算机应该经历理解图像的学习过程 , 这与孩子学习过程非常相似 , 但学习时间会少的多 。 简而言之 , 它通过从头学习 , 然后从输入层传到输出层 。 因此 , 网络必须首先知道图像中的所有原始部分 , 即边缘、轮廓和其它低级特征 。 检测到这些低级特征之后 , 传递给后面更深的隐藏层 , 提取更高级、更抽象的特征 。 过滤器提供了一种提取用户需要的信息的方式 , 而不是盲目地传递数据 , 因为计算机不会理解图像的结构 。 在初始情况下 , 可以通过考虑特定过滤器来提取低级特征 , 这里的滤波器也是一组像素值 , 类似于图像 。 可以理解为连接卷积神经网络中的权重 。 这些权重或滤波器与输入相乘以得到中间图像 , 描绘了计算机对图像的部分理解 。 之后 , 这些中间层输出将与多个过滤器相乘以扩展其视图 。 然后提取到一些抽象的信息 , 比如人脸等 。
- 三星发布新电视:99.99%屏占比 8K输出
- Facebook Messenger收集的数据量有多吓人?可视化对比图告诉你
- 数据可视化三节课之二:可视化的使用
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...
- 公牛推出电竞充电器,1A1C双输出,集成能量呼吸灯
- 在Linux系统中安装深度学习框架Pytorch
- 为何学习编程往往都是从编写输出HelloWorld的程序开始
- MOMAX推出20W 1A1C PD充电器,支持双口输出
- 数据|南方电网超高压公司成功举办首届数据可视化分析大赛
- 30行Python代码实现3D数据可视化!非常惊艳