如今 , 机器已经能够在理解、识别图像中的特征和对象等领域实现99%级别的准确率 。 生活中 , 我们每天都会运用到这一点 , 比如 , 智能手机拍照的时候能够识别脸部、在类似于谷歌搜图中搜索特定照片、从条形码扫描文本或扫描书籍等 。 造就机器能够获得在这些视觉方面取得优异性能可能是源于一种特定类型的神经网络——卷积神经网络(CNN) 。 如果你是一个深度学习爱好者 , 你可能早已听说过这种神经网络 , 并且可能已经使用一些深度学习框架比如caffe、TensorFlow、pytorch实现了一些图像分类器 。 然而 , 这仍然存在一个问题:数据是如何在人工神经网络传送以及计算机是如何从中学习的 。 为了从头开始获得清晰的视角 , 本文将通过对每一层进行可视化以深入理解卷积神经网络 。
 文章插图
文章插图
卷积神经网络在学习卷积神经网络之前 , 首先要了解神经网络的工作原理 。 神经网络是模仿人类大脑来解决复杂问题并在给定数据中找到模式的一种方法 。 在过去几年中 , 这些神经网络算法已经超越了许多传统的机器学习和计算机视觉算法 。 “神经网络”是由几层或多层组成 , 不同层中具有多个神经元 。 每个神经网络都有一个输入和输出层 , 根据问题的复杂性增加隐藏层的个数 。 一旦将数据送入网络中 , 神经元就会学习并进行模式识别 。 一旦神经网络模型被训练好后 , 模型就能够预测测试数据 。
另一方面 , CNN是一种特殊类型的神经网络 , 它在图像领域中表现得非常好 。 该网络是由YanLeCunn在1998年提出的 , 被应用于数字手写体识别任务中 。 其它应用领域包括语音识别、图像分割和文本处理等 。 在CNN被发明之前 , 多层感知机(MLP)被用于构建图像分类器 。 图像分类任务是指从多波段(彩色、黑白)光栅图像中提取信息类的任务 。 MLP需要更多的时间和空间来查找图片中的信息 , 因为每个输入元素都与下一层中的每个神经元连接 。 而CNN通过使用称为局部连接的概念避免这些 , 将每个神经元连接到输入矩阵的局部区域 。 这通过允许网络的不同部分专门处理诸如纹理或重复模式的高级特征来最小化参数的数量 。 下面通过比较说明上述这一点 。
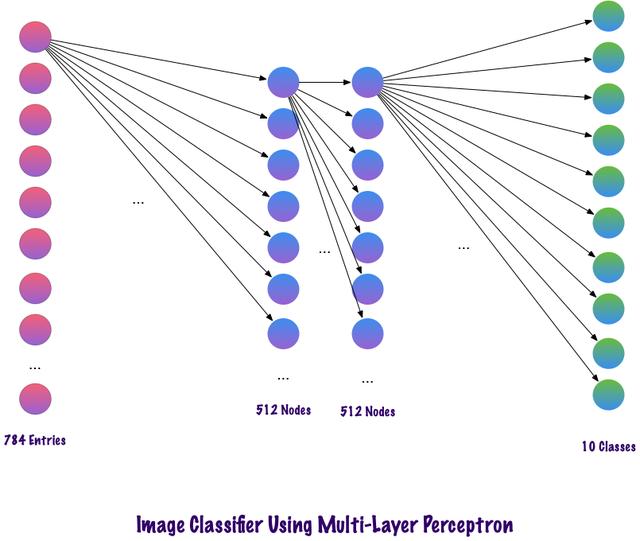
比较MLP和CNN因为输入图像的大小为28x28=784(MNIST数据集) , MLP的输入层神经元总数将为784 。 网络预测给定输入图像中的数字 , 输出数字范围是0-9 。 在输出层 , 一般返回的是类别分数 , 比如说给定输入是数字“3”的图像 , 那么在输出层中 , 相应的神经元“3”与其它神经元相比具有更高的类别分数 。 这里又会出现一个问题 , 模型需要包含多少个隐藏层 , 每层应该包含多少神经元?这些都是需要人为设置的 , 下面是一个构建MLP模型的例子:
Num_classes = 10Model = Sequntial()Model.add(Dense(512, activation=’relu’, input_shape=(784, )))Model.add(Dropout(0.2))Model.add(Dense(512, activation=’relu’))Model.add(Dropout(0.2))Model.add(Dense(num_classes, activation=’softmax’))上面的代码片段是使用Keras框架实现(暂时忽略语法错误) , 该代码表明第一个隐藏层中有512个神经元 , 连接到维度为784的输入层 。 隐藏层后面加一个dropout层 , 丢弃比例设置为0.2 , 该操作在一定程度上克服过拟合的问题 。 之后再次添加第二个隐藏层 , 也具有512谷歌神经元 , 然后再添加一个dropout层 。 最后 , 使用包含10个类的输出层完成模型构建 。 其输出的向量中具有最大值的该类将是模型的预测结果 。
这种多层感知器的一个缺点是层与层之间完全连接 , 这导致模型需要花费更多的训练时间和参数空间 。 并且 , MLP只接受向量作为输入 。
 文章插图
文章插图
- 三星发布新电视:99.99%屏占比 8K输出
- Facebook Messenger收集的数据量有多吓人?可视化对比图告诉你
- 数据可视化三节课之二:可视化的使用
- 历时 1 个月,做了 10 个 Python 可视化动图,用心且精美...
- 公牛推出电竞充电器,1A1C双输出,集成能量呼吸灯
- 在Linux系统中安装深度学习框架Pytorch
- 为何学习编程往往都是从编写输出HelloWorld的程序开始
- MOMAX推出20W 1A1C PD充电器,支持双口输出
- 数据|南方电网超高压公司成功举办首届数据可视化分析大赛
- 30行Python代码实现3D数据可视化!非常惊艳