Flink流处理应用在IDEA中的执行流程分析
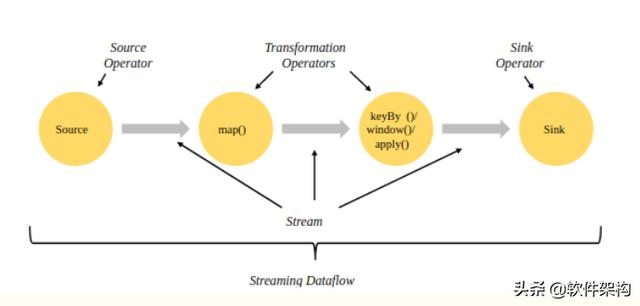
【Flink流处理应用在IDEA中的执行流程分析】Flink流式计算的核心概念就是将数据从输入流一个个传递给operator进行链式处理 , 最后交给输出流的过程 。 对数据的每一次处理在逻辑上成为一个operator(算子) 。
 文章插图
文章插图
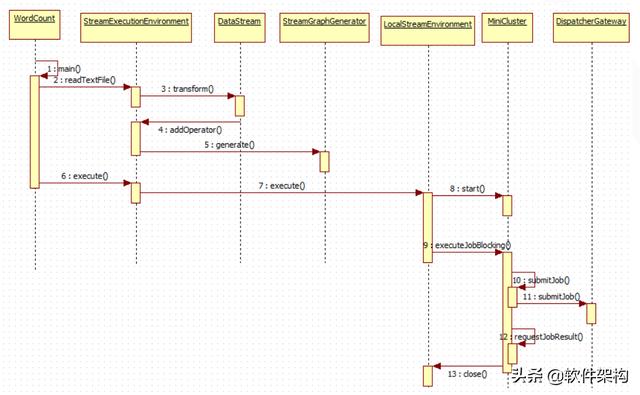
Flink经典示例WordCount流处理应用-整个执行流程如下图所示:
 文章插图
文章插图
第1~4步:main方法读取文件 , 增加算子;
第5步:产生StreamGraph , 从而可以得到JobGraph , 即将Stream程序转换成JobGraph;
第6~8步:LocalEnvironment 是本地执行任务的环境 , 负责启动MiniCluster , 在本地执行Flink任务 。 MiniCluster可以看做是内嵌的Flink运行时环境 , 所有的组件都在独立的本地线程中运行 。 MiniCluster的启动入口在LocalStreamEnvironment#execute(jobName)中 。
第9~12步:执行job;
第13步:关闭执行流程;
- NVIDIA 5nm架构猛料:流处理器超1.84万个
- FlinkSQL 动态加载 UDF 实现思路
- 18432个流处理器 网传下一代N卡性能强大
- 万字干货还原美团Flink实时数仓建设
- 网易云音乐基于Flink实时数仓实践
- flink消费kafka的offset与checkpoint
- 唯品会实时平台架构-Flink、Spark、Storm
- Apache Hudi与Apache Flink集成
- Flink的DataSet基本算子总结
- Flink中parallelism并行度和slot槽位的理解