Flink中parallelism并行度和slot槽位的理解
Flink应用程序在一个分布式环境中并行执行 。 当一个数据流程序提交到作业管理器(JobManager)执行时 , 系统将会创建一个数据流图 , 然后准备执行需要的操作符 。 每一个操作符将会并行化到一个或者多个任务中去 。 每个算子的并行任务都会处理这个算子的输入流中的一份子集 。 一个算子并行任务的个数叫做算子的并行度 。 它决定了算子执行的并行化程度 , 以及这个算子能处理多少数据量 。
算子的并行度可以在执行环境这个层级来控制 , 也可以针对每个不同的算子设置不同的并行度 。 默认情况下 , 应用程序中所有算子的并行度都将设置为执行环境的并行度 。 执行环境的并行度(也就是所有算子的默认并行度)将在程序开始运行时自动初始化 。 如果应用程序在本地执行环境中运行 , 并行度将被设置为CPU的核数 。 当我们把应用程序提交到一个处于运行中的Flink集群时 , 执行环境的并行度将被设置为集群默认的并行度 , 除非我们在客户端提交应用程序时显式的设置好并行度 。
parallelism指的是并行度的意思 。 在 Flink 框架中代表每个任务的并行度 , 适当的提高并行度可以大大提高 job 的执行效率 。
【Flink中parallelism并行度和slot槽位的理解】slot指的是任务槽位的意思 , flink中任务的并行性由每个 Task Manager 上可用的 slot 决定 。
并行度是动态概念 , 任务槽数量是静态概念 。 并行度<=任务槽数量 。 一个任务槽最多运行一个并行度 。
一、如何设置flink job的parallelism(1)在flink的配置文件中flink-conf.yaml , 默认的并行度为1;
parallelism.default: 1
(2)在通过shell方式提交flink job的时候 , 可以使用-p指定程序的并行度;
./bin/flink run -p 10 ../word-count.jar
(3)在flink job程序内设置并行度;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(10);
(4)每个算子指定并行度;
 文章插图
文章插图
data.keyBy(new xxxKey())
.flatMap(new xxxFlatMapFunction()).setParallelism(2)
.map(new xxxMapFunction).setParallelism(2)
.addSink(new xxxSink()).setParallelism(1)
上面每个算子设置的并行度优先级要高于前面 env设置的并行度 , 然后才是配置文件中默认并行度 。
二、如何理解flink中的slot?slot 是指 taskmanager 的并发执行能力 。
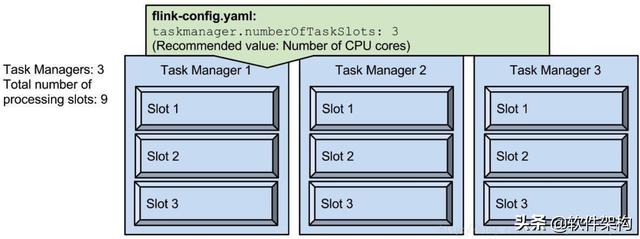
flink-conf.yaml中默认taskmanager.numberOfTaskSlots=1
下面 , 我们设置taskmanager.numberOfTaskSlots=3;即每一个 taskmanager 中分配 3 个 TaskSlot, 3 个 taskmanager 一共有 9 个 TaskSlot 。
 文章插图
文章插图
 文章插图
文章插图
三、调整parallelism并行度设置parallelism 是指 taskmanager 实际使用的并发能力 。
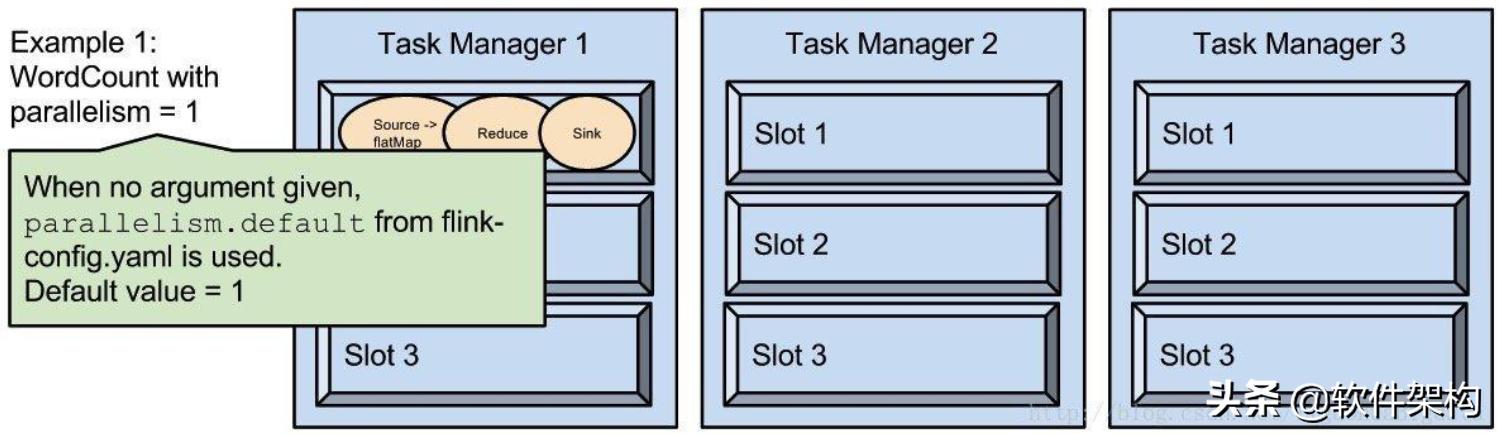
parallelism.default=1;即运行程序默认的并行度为 1 , 9 个 TaskSlot 只用了 1 个 , 有 8 个空闲 。 设置合适的并行度才能提高效率 。
 文章插图
文章插图
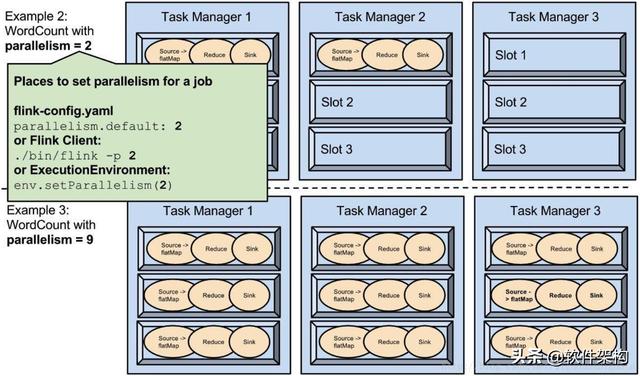
parallelism 是可配置;下面我们调整parallelism 并行度 。
图中 example2 每个算子设置的并行度是 2 ,example3 每个算子设置的并行度是 9 , 所有slot槽位都占用了 。
 文章插图
文章插图
- FlinkSQL 动态加载 UDF 实现思路
- 万字干货还原美团Flink实时数仓建设
- 微单与单反并行 佳能中国副总裁石井俊幸访谈
- 网易云音乐基于Flink实时数仓实践
- flink消费kafka的offset与checkpoint
- 坐拥1.3亿用户,招行APP最新打法来了!从获客转战流量经营,MAU和AUM并行不悖
- 唯品会实时平台架构-Flink、Spark、Storm
- Apache Hudi与Apache Flink集成
- Flink的DataSet基本算子总结
- Flink到底能不能实现exactly-once语义?