flink消费kafka的offset与checkpoint
生产环境有个作业 , 逻辑很简单 , 读取kafka的数据 , 然后使用hive catalog , 实时写入hbase , hive , redis 。 使用的flink版本为1.11.1 。
为了防止写入hive的文件数量过多 , 我设置了checkpoint为30分钟 。
env.enableCheckpointing(1000 * 60 * 30); // 1000 * 60 * 30 => 30 minutes达到的效果就是每30分钟生成一个文件 , 如下:
hive> dfs -ls /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/ ;Found 10 items-rw-r--r--3 hdfs hive0 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/_SUCCESS-rw-r--r--3 hdfs hive248895 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10911-rw-r--r--3 hdfs hive306900 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10912-rw-r--r--3 hdfs hive208227 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-0-10913-rw-r--r--3 hdfs hive263586 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10911-rw-r--r--3 hdfs hive307723 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10912-rw-r--r--3 hdfs hive196777 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-1-10913-rw-r--r--3 hdfs hive266984 2020-10-18 00:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10911-rw-r--r--3 hdfs hive338992 2020-10-18 00:50 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10912-rw-r--r--3 hdfs hive216655 2020-10-18 01:20 /opt/user/hive/warehouse/dw.db/ods_analog_zgyp/dt_day=2020-10-18/dt_hour=00/part-5b7b6d44-993a-4af7-b7ee-1a8ab64d3453-2-10913hive> 但是 , 同时也观察到归属于这个作业的kafka消费组积压数量 , 每分钟消费数量 , 明显具有周期性消费峰值 。
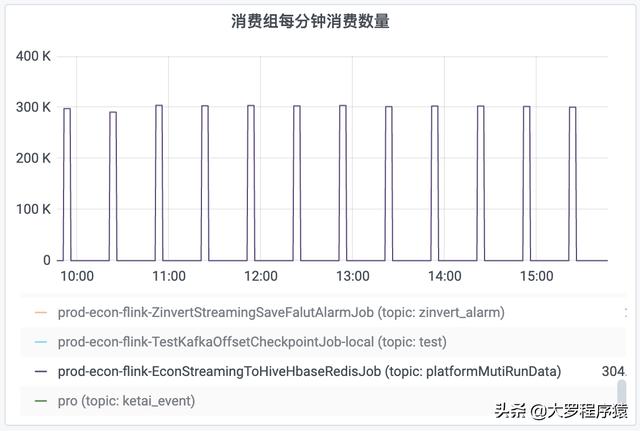
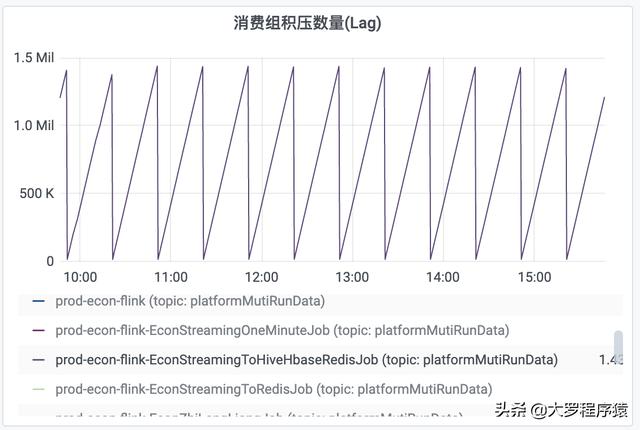
比如 , 对于每30分钟时间间隔度的一个观察 , 前面25分钟的“每分钟消费数量”都是为0 , 然后 , 后面5分钟的“每分钟消费数量”为300k 。 同理 , “消费组积压数量”也出现同样情况 , 积压数量一直递增 , 但是到了30分钟的间隔 , 就下降到数值0 。 如图 。
 文章插图
文章插图
消费组每分钟消费数量
 文章插图
文章插图
消费组积压数量
但其实 , 通过对hbase , hive , redis的观察 , 数据是实时写入的 , 并不存在前面25分钟没有消费数据的情况 。
查阅资料得知 , flink会自己维护一份kafka的offset , 然后checkpoint时间点到了 , 再把offset更新回kafka 。
为了验证这个观点 , “flink在checkpoint的时候 , 才把消费kafka的offset更新回kafka” , 同时 , 观察 , savepoint机制是否会重复消费kafka , 我尝试写一个程序 , 逻辑很简单 , 就是从topic "test"读取数据 , 然后写入topic "test2" 。 特别说明 , 这个作业的checkpoint是1分钟 。
- 索尼欲将新款360 Reality Audio扬声器带入消费者家中
- 全真互联网,产业互联网和消费互联网的融合
- 消费者报告 | 美团充电宝电量不足也扣费,是质量问题还是系统缺陷?
- 中消协点名大数据网络杀熟 反对利用消费者个人数据画像
- 它“骗了”消费者多年,工厂早已停产,靠商标一年“捞金”12亿
- 莫让差评超长审核期侵害消费者权益
- 低欲望的后厂村:遍地985、211,高收入低消费,偏爱996
- 康宁列举蓝宝石玻璃种种缺点 不适合用于消费级市场
- 小米11传来好消息,给消费者一个“后悔”的机会
- FlinkSQL 动态加载 UDF 实现思路