怎样让数据库再快一点?( 三 )
当作持久化内存使用时应用需关注的问题一、数据持久化当一条store指令完成后 , 数据并没有立即写到DIMM介质上 , 很有可能还存在于cpu cache中或者Memory Controller的Write Pending Queue中 , 掉电后还是会造成数据丢失 , 也就说这里是一个异步的持久化过程 。 所以应用需要显示flush cpu cache和WPQ后才能说明数据确实已经持久化 , 当然在Intel平台上ADR模块掉电后会触发硬件中断到Memory Controller并flush WPQ中的数据到DIMM介质上 。 即Intel平台上关注cpu cache就好 。 clflush、clflushopt、clwb指令都是用于flush cpu cache, 其中clflushopt、clwb是为了提升持久化内存的flush效率新引入的 , 不一定所有平台都支持 。 其中clflush是串行flush, 而clflushopt可以并行flush, clwb与clflush类似 , 只是并不一定会立即失效cache line , 提升后续读性能 。
 文章插图
文章插图
由于CPU乱序执行和cpu cahe 并行flush问题可能会导致两个数据对象实际在介质上持久化的顺序与应用写入的顺序相反 , 如果说这两个数据数据对象具有因果关系 , 那就出大问题了 。
如下面这段代码 , 如果list->length修改后的值所在的cache line先被flush到介质 , 而在list->tail->next修改后的值还未flush到介质之前机器掉电 , 重启后根据list->length再去遍历list就可能会造成崩溃 。
typedef struct List {int length;struct List* head;struct List* tail;};typedef struct Node {void * data;struct Node* next;}Node;void appendList(List* list, Node* node){list->tail->next = node;list->tail = node;list->length++;}正确的做法是在flush(list->tail = node;__mm_clwb(__mm_clwb(__mm_sfence();//list->length++;__mm_clwb(}二、数据一致性在X86平台上 , 仅不大于8字节的对象能够保证是原子写 , 大于8字节的数据对象可能写到一半出现机器掉电 , 重启后的数据是否完整无法得知 。 所以应用需要通过flag/redo log/undo log等方式判断数据是否完整 , 以及不完整时该怎么去处理 , 当然这势必会引入比较重的开销 。
再比如将Redis的索引结构(hash table)及数据都写入到持久化内存中 , 那么当用户写入一条数据时 , 内部可能发生hash table扩容 , hash entry搬迁等多个动作 , 要维护数据的一致性问题 , 那就也需要引入类似mini transaction的机制 。 所以把AEP当作持久化内存与易失性内存来使用时性能肯定是一定的差异的 。
一旦考虑把AEP当作持久化的内存来使用时 , 所写下的每一行代码都考虑怎么处理数据一致性的问题 , 这并不是一件容易的事情 。
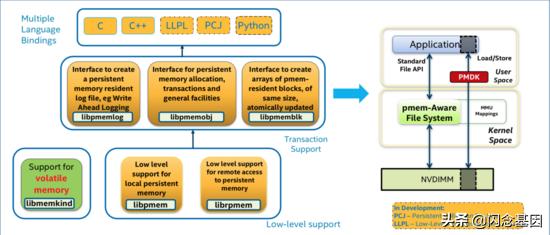
为了简化持久化内存在AppDirect下的使用 , Intel开发了 PMDK (Persistent Memory Development Kit) 。 我们可以直接在PMDK的基础上去开发自己的应用 , 但是这些通用的库也并不一定适合所有场景 。
 文章插图
文章插图
下面这几个库用的比较多一些:
1. libpmem: 用来将数据持久化到介质上 , 以及提供一些优化的内存操作(memcpy, memset等)函数 。
2. libpmemlog: 基于这个库可以用来写顺序追加的log等 。
3. ibpmemobj: 这个库实现了一套事务机制 , 用来保证数据的一致性问题 。
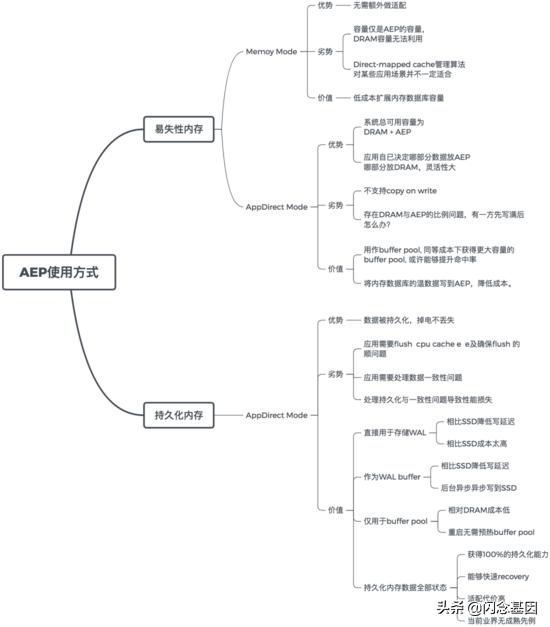
最后用一张图总结一下AEP的使用方式及在数据领域潜在的价值 。
 文章插图
文章插图
本文来源:微信公众号:腾讯云数据库
【怎样让数据库再快一点?】原文地址:;mid=2247488667 --tt-darkmode-bgcolor: #131313;">作者 张鹏义 , 腾讯云数据库高级工程师 , 曾参与华为Taurus分布式数据研发及腾讯CynosDB for PG研发工作 , 现从事腾讯云Redis数据库研发工作 。
- 今年过年不回家的你 应该怎样度过七天假期?
- 手机照片、视频怎样添加文字?原来很简单,4种方法一分钟搞定
- 怎样提高苹果6的运行速度?有这些问题就别救了,你用了几年了?
- DataPipeline亮相2020数据库技术大会,揽获「技术卓越奖」
- 跟风苹果取消附赠充电器引争议,小米会怎样体面地把手机卖了?
- WPC数据库中发现华为Mate 40E新型号 搭载麒麟990E芯片
- 数据|新基建时代,高大全的数据管理解决方案是怎样“炼”成的?
- MySQL数据库数据归档回收工具使用场景分享-爱可生
- 小鹏和特斯拉隔空“对喷”的背后又透露出怎样的信息?
- 屏幕面前 我们的双眼都经历了怎样的折磨?