怎样让数据库再快一点?( 二 )
一、Memory Mode根据AEP在存储层次结构中所处的位置 , 自然想到的是将DRAM作为AEP的缓存 , AEP中的热数据缓存在DRAM中 , 这也符合计算机存储系统一惯的设计思想 。 在这种模式下AEP和DRAM共同组成了一块对上层透明且容量更大的易失性内存 , 这时系统的总容量等于AEP的容量 , 应用无需做任何额外的修改即可使用 。 DRAM到AEP的缓存算法由IMC(集成在CPU里的memory controller)硬件管理 。
当前的缓存策略采用 direct-mapped-cache 算法实现, 数据以cache line的粒度换入换出 , 但是这种算法会把AEP中多块内存映射到DRAM中的同一个位置 , 以致于在某些场景下出现冲突不命中的情况可能比较严重 。 所以这么一个通用的算法并不能很好地将热数据从AEP中分离出来 。
Memory Mode配置方法:
ipmctl create -goal memorymode=100 (ipmctl是Intel开发的一个管理持久化内存的工具)reboot后 free -g 就可以看到系统内存容量等于AEP的总容量 。
二、AppDirect Mode应用可以不经过DRAM而直接访问AEP , 用由应用自己管理 , 这种使用方式叫做AppDirect Mode 。 那么在这种模式下应用怎么访问AEP?SNIA(Storage Networking Industry Association)制定了一套编程模型 , 如下图所示 , 其中NVDIMM指非易失性内存模块 , 即AEP设备 。
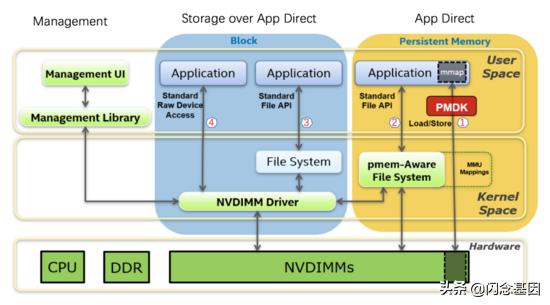 文章插图
文章插图
传统的文件系统都有一层page cache, 访问数据时先将数据copy到page cache中,然后再copy到应用buffer 中 。 对于低延迟及可按字节寻址的AEP来说 , 没这个必要 。 Pmem-Aware File System指的是支持直接访问设备(DAX)的文件系统 , DAX特性从IO路径上移除page cache, 同时允许mmap()直接建立到持久化内存的映射关系 。 目前ext4和xfs都已支持DAX特性 。
AppDirect Mode配置方法:ipmctl create -goal PersistentMemoryType=appdirectreboot (reboot后就可以在/dev下看到pmem0 , pmem1设备)ndctl create-namespace -m fsdax -r 0mkfs -t ext4 /dev/pmem0mount -odax /dev/pmem0 /mnt/pmem0 (-o dax开启DAX)
配置完成后就可以在/mnt/pmem0下创建、删除、读写文件了 , 但是一般不会直接这么使用 。 通常在/mtn/pmem0/上通过mmap建立memory-map file, 一旦映射建立后 , 用户虚拟地址空间通过MMU就直接映射到AEP的物理空间中 , 应用无需陷入内核态即可高效地以字节寻址的方式访问AEP 。 再借助于libmemkind库 , 就可像使用DRAM一样来使用AEP 。 Libmemkind将create/open file, mmap进行了封闭 , 并提供类malloc/free的接口在AEP上分配内存 。 所以应用需要显示通过类malloc/free接口决定哪些数据直接写到AEP , 对已经代码要做一定的修改 。
要注意的是mmap必须是以shared的方式建立映射 , 如果是以private的方式映射 , 更新数据时并不会写到介质上 , 而是写到进程私有的空间中(page cache中) , 然而这里AppDirect模式下是没有page cache的 。 这里引出了一个问题:如果进程在AEP中分配了一块内存 , 然后fork一个子进程 , 那么子进程也是能够看到父进程对这块内存的更新 , 因为两个父子进程的更新都会立即反映到同一块物理内存上 。 所以对于分配在AEP上的内存就没办法利用fork的copy on write机制来获取一致性的内存状态 。 (Redis正是利用fork的copy on write机制获取一对致性内存状态做备份操作) 。
AppDirect下即可以将AEP当作易失性的内存使用也可以当作持久化的内存使用 。 当作易失性内存使用时 , 仅仅是我们不关注重启后AEP上的数据内容而已 , 并不是指掉电后AEP上的内容真的丢失了 。 如果当持久化的内存使用 , 则应用需要处理持久化及数据一致性等问题 , 下节详细讲 。
三、Storage over App Direct如上图中的第三、四条路径 , 分别对外提供block接口和标准的文件接口 , 应用无需额外的适配工作 , 这和使用SSD并没有什么区别 , 仅仅是延迟更小 。 但是这种使用方式软件栈上的开销所占的比例相当大 , 并不能发挥出很好发挥出AEP的极致性能 , 基本不用考虑这种用法 , 除非是已有代码确实不能改动但又想获得低延迟访问的情况 。
- 今年过年不回家的你 应该怎样度过七天假期?
- 手机照片、视频怎样添加文字?原来很简单,4种方法一分钟搞定
- 怎样提高苹果6的运行速度?有这些问题就别救了,你用了几年了?
- DataPipeline亮相2020数据库技术大会,揽获「技术卓越奖」
- 跟风苹果取消附赠充电器引争议,小米会怎样体面地把手机卖了?
- WPC数据库中发现华为Mate 40E新型号 搭载麒麟990E芯片
- 数据|新基建时代,高大全的数据管理解决方案是怎样“炼”成的?
- MySQL数据库数据归档回收工具使用场景分享-爱可生
- 小鹏和特斯拉隔空“对喷”的背后又透露出怎样的信息?
- 屏幕面前 我们的双眼都经历了怎样的折磨?