黑芝麻智能杨宇欣:200T大算力芯片明年发布,产品路线图首次公布|GTIC2020( 四 )
 文章插图
文章插图
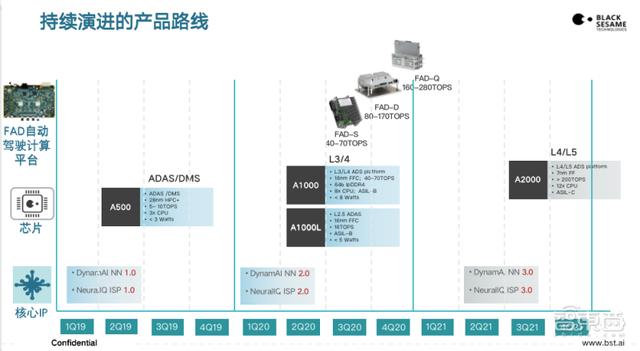
黑芝麻智能最新产品路线图
从技术来讲 , 黑芝麻智能提供完整端到端的解决方案 , 包括前端摄像头或者传感器的定制 。 其实传感器和主芯片关系非常密切 , 跟这些传感器厂商一起做定制 , 可以帮助车厂更好地做传感器选型 。 另外 , 基于车规级的高性能计算平台 , 围绕领先的图像处理能力、神经网络加速器技术 , 黑芝麻智能提供完整的自动驾驶方案 。
跟很多芯片设计公司不一样的是 , 大多数芯片设计公司采用通用IP来开发自己的产品 , 但黑芝麻智能团队认为这在自动驾驶领域会面临几个难点:第一 , 面向车规级的专用市场 , 很多的通用架构的核心IP不一定能满足;第二 , 跟全球的技术赛跑 , 要保证技术能够持续领先 , 需要有自己的核心武器 。
2016年成立后 , 黑芝麻智能研发第一款芯片花了三年时间 , 很多芯片设计公司拿通用IP来开发 , 可能第一颗芯片花一年或者一年半就能出来 , 而黑芝麻智能选择了相对来说 , 最初无论是行业还是投资人都觉得有点难走的路 。
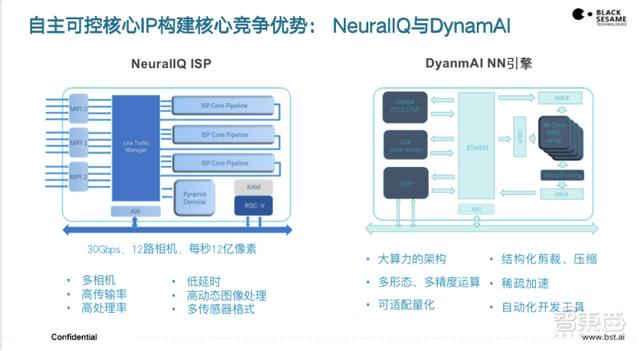
黑芝麻智能从核心IP开始开发 , 目前有两个核心IP 。 其中 , 一个是图像处理ISP IP , 一个是神经网络加速器NLP IP 。 黑芝麻智能的技术逻辑是要“看得清”、“看得准” 。
 文章插图
文章插图
“看得清”就是图像处理 , 自动驾驶摄像头是十分核心的传感器 , 随着摄像头数量的增加、像素的增加 , 需要处理的数据越来越多 。 在人工智能领域 , 当海量数据涌到神经网络去做处理的时候 , 如果数据的质量报告中有大量的像素看不清楚 , 会浪费很多算力去做补偿 。 而车规级的高性能ISP的目标是 , 把采集出来的每帧图像每个像素处理得足够清楚 , 这样在后面做推理的时候 , 可以用更简单的算法或者更少的算力得到更准确的结果 。 这是非常核心的技术 , 黑芝麻智能选择自己开发 , 因为可能买不到高性能车规级的ISP的IP 。
“看得准”就是神经网络架构系统 , 车载场景是很典型的边缘计算场景 , 要求算力不断提升 , 同时对能效比亦有要求 。 黑芝麻智能自研的NPU通过自己定义的核心架构 , 可以在数据处理中 , 在不同的卷积层处理时 , 减少很多数据的吞吐次数 , 提供非常高的能效 。 这也是黑芝麻智能能够确保从现在芯片的几十TOPS算力 , 达到下一代芯片几百TOPS算力的核心 。
电动车的芯片如果功耗达到几百瓦 , 对整个能源的管理 , 对电源电路部分的设计要求就会提高很多 , 整个车的稳定性、可靠性都会受影响 。 能效比对未来自动驾驶芯片来说非常重要 。
A1000是黑芝麻智能今年6月份发布的芯片 , INT8 40TOPS的算力 , 基本符合现在对L2.5到L3级别的市场需求 。
同时 , 黑芝麻智能在今年9月份发布了FAD系统 , 这套系统包括了以自研芯片为核心的完整的自动驾驶平台 , 有操作系统 , 有中间件 , 有开放的工具链体系 , 可以支撑合作伙伴把他们的应用放出来 。
FAD系统有单芯片、双芯片、四芯片不同的方案 , 双芯片方案做到80~140TOPS算力 。 而且 , 黑芝麻智能自己开发了比较复杂的软件中间件系统 , 做到双芯片的互为备份冗余等等 。 这也是特斯拉提出的思路 , 大算力芯片处理非常多的数据 , 难免里面有可能出现失效的问题 , 双芯片同时运行相同的算法 , 可以起到互相备份的作用 , 但前提是算力一定要足够大 。
目前车厂拿到的大算力自动驾驶的平台 , 一个是英伟达的Xavier平台 , 另一个就是黑芝麻智能的平台 。 自动驾驶这么大的赛道 , 未来一定是专用芯片在能效比、性价比等等效益方面有更好的优势 。
据杨宇欣分享 , 黑芝麻智能团队从Xavier开发者社区下载了两个模型 , 通过黑芝麻智能自己的工具转换到自己的芯片上 。 结果显示 , Xavier平台用11瓦的功耗达到300多帧的性能 , 黑芝麻智能的平台用6瓦的功耗达到500多帧的性能 。
- 联想正开发下一代ThinkReality智能眼镜
- 199元 小米有品众筹智能健腹轮:LED数显 轻松练出马甲线
- 智能手机时代,电池越来越不经用,怎么充电才能延长电视寿命?
- 人工智能|麻辣财经:我国“算力”增长迅速,有力支撑人工智能发展
- 人工智能有助于文学照亮人性
- 2021海口国际新能源汽车暨智能网联汽车展览会开幕
- 有没有必要给老年人买台智能手机?
- 人瑞人才(06919):未来3年系统平台将发力智能化,打造职业生态链平台
- 疫情背景下 智能录音笔成远程工作利器
- 识别|不摘口罩也能识别人脸?伊朗推出新型智能摄像头加强治安