ZipInputStream 和 RSA 算法的纠葛
背景以前实现过一个系统升级操作:通过上传 zip 压缩包、并通过 RMI 方式调用另一个 Java 程序执行upgrade.sh 脚本完成的 。 其中有一个系统版本信息校验的逻辑 , 版本信息是一段经过 RSA 算法加密的 xml 信息 , 直接打包到 zip 文件中 。
系统升级操作 , 首先会对 zip文件中的版本描述信息进行解密 , 与当前系统数据库中维护的版本信息进行比对 , 校验通过才运行执行升级操作 。
该功能存在一个诡异的问题 , 只有我本机的 360压缩工具生成的 zip 文件 , 解密代码才不会出错 , 而用 winRAR 或者 7Zip 工具生成的压缩文件都报解密异常 。
这个问题困扰了我一年 , 因为这个不常用的功能 , 所以缺陷只有我知道 。 但是 , 这是个大坑 , 如果不解决 , 万一我的电脑挂了或者离职了 , 这个功能就无法正常运转了 。
某一天没事儿 , 想着把这个坑抹平 , 就下决心要找找原因 。 最终找到根源了 , 本文来分享一下 Java IO 操作中的坑 。
直接读取 ZIP 文件升级操作直接读取zip文件流中的加密密文 , Java 直接读取 Zip文件的流程如下:
public static void readFromZip(String zipFileName) throws IOException{ZipFile zf = null;InputStream in = null;ZipInputStream zin = null;try{zf = new ZipFile(zipFileName);in = new BufferedInputStream(new FileInputStream(zipFileName));zin = new ZipInputStream(in);ZipEntry ze = null;while ((ze = zin.getNextEntry()) != null) {String zipName = ze.getName();if(zipName.contains("descriptor")){//找到密文文件并读取InputStream inputStream = zf.getInputStream(ze);byte[] data = http://kandian.youth.cn/index/new byte[inputStream.available()];int len = 0;while ((len = inputStream.read(data))> 0) {System.out.println("length:"+len);}System.out.println("data is :"+Arrays.toString(data));}}} finally {try {zin.closeEntry();in.close();zf.close();} catch (IOException e1) {e1.printStackTrace();}} }直接使用 ZipInputStream类 , 逐个遍历压缩包中的每个文件 , 找到加密文件后读取该文件的内容到字节数组中 。 这里处理时有一个问题 , Java 对不同压缩工具生成的压缩文件处理方式有差异 。
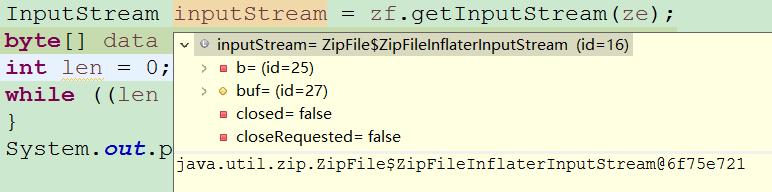
不同压缩工具的对应Java实现的差异1 、WinRAR压缩文件在使用Java IO工具读取时 , zf.getInputStream()流的实例对象为:
 文章插图
文章插图
这个类的read(data)操作 , 分了两次才读完数据 。 执行打印结果为:
length:765length:3
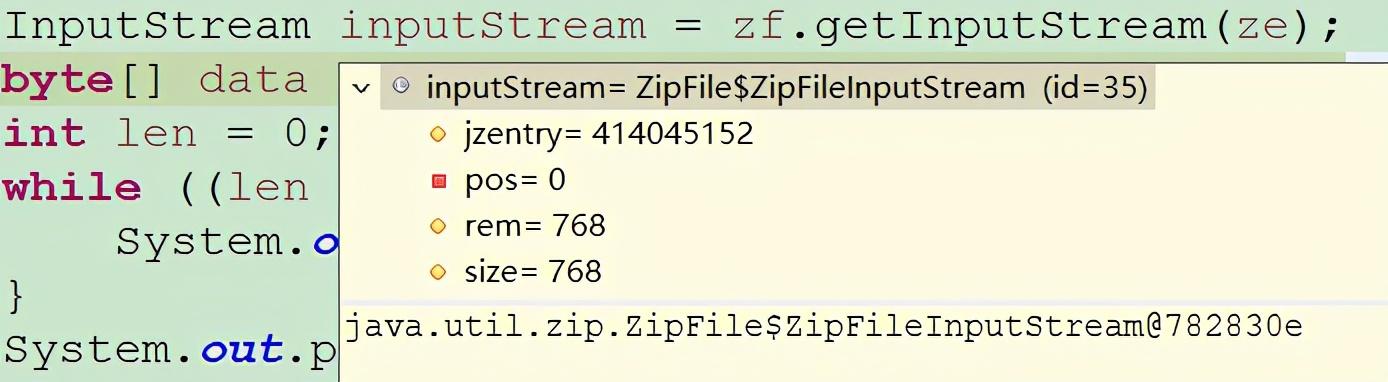
2、360压缩文件在使用Java IO工具读取时 , zf.getInputStream()流的实例对象为:
 文章插图
文章插图
这个类的read(data)操作 , 一次读完数据 。 执行打印结果为:
length:768
使用BufferedInputStream , 定义缓存取后 , 两种流都能一次读完加密数据 。
public static byte[] bufferedReadFromInputStream(InputStream inputstream) throws IOException{BufferedInputStream bufferedInputStream = new BufferedInputStream(inputstream);byte[] data = http://kandian.youth.cn/index/new byte[inputstream.available()];int len = 0;while ((len = bufferedInputStream.read(data))> 0) {}return data; }这是因为原始的 InputStream 的read()操作 , 是每完成一次 IO 读取 , 就往内部缓冲区执行写入一次数据;而缓冲区定义后 , 只有缓冲区写满或者读不到数据时才写入内存 , 这就能保证每次写入内存时的数据长度是有保障的 。
- 美国研发新工具可量化AI算法的可信度
- 自用:HMM隐马尔可夫模型学习笔记(2)-前向后向算法
- 又是一年1024,程序员:我写的算法不足以控制人类
- AI|图灵奖得主姚期智:人工智能算法还需突破哪些瓶颈
- 算法|堪比旗舰的摄影表现 vivo Y73s拍照体验
- 数据|「远见」个人信息保护法将出台 揭开数据算法的神秘“面纱”
- 十大经典排序算法(动图演示)
- 缓存淘汰算法LRU和LFU
- 用图形解释10种图形算法
- 德州点创教育:经典FOR循环打印星号三角形算法详解