点云分类的自动放大框架 PointAugment( 二 )
AutoAugment 提出了一种强化学习策略 , 通过交替训练代理任务和策略控制器 , 然后将学习到的放大函数应用于输入数据 , 从而找到最佳的放大函数集 。 不久之后 , 另两项研究 , FastAugment 和 PBA 探索了先进的超参数优化方法 , 以更有效地找到放大的最佳转换 。 与这些学习为所有训练样本找到固定的放大策略的方法不同 , PointAugment 是样本感知的 , 这意味着在训练过程中根据单个训练样本的属性和网络能力动态生成转换函数 。 最近 , Tang 等人张等建议学习使用对抗策略的目标任务的放大策略 。 倾向于直接最大化增加样本的损失 , 以提高图像分类网络的泛化能力 。 与之不同的是 , PointAugment 通过一个明确设计的边界扩大了放大后的点云与原始点云之间的损失;动态地调整了放大样本的难度 , 以便放大的样本能够更好地满足不同训练阶段的分类要求 。
(2)点云数据放大
在现有的点处理网络中 , 数据放大主要包括围绕重力轴的随机旋转、随机缩放和随机抖动[23,24] 。 这些手工制定的规则在整个训练过程中都是固定的 , 因此可能无法获得最佳样本来有效地训练网络 。 到目前为止 , 还没有发现有任何研究利用三维点云来实现网络学习最大化的工作 。
(3)点云深度学习
在 PointNet 架构的基础上 , 有几篇文章[24 , 17 , 18]探索了局部结构来放大特征学习 。 另一些人通过创建局部图[36,37,29,45]或几何元素[11,22]来探索图形卷积网络 。 另一个工作流程[32 , 34 , 19]将不规则点投影到规则空间中 , 以允许传统的卷积神经网络工作 。 与上述工作不同 , 目标不是设计一个新的网络 , 而是通过有效地优化点云样本的增加来提高现有网络的分类性能 。 为此 , 设计了一个放大器来学习一个特殊的放大函数 , 并根据分类器的学习进度调整放大函数 。
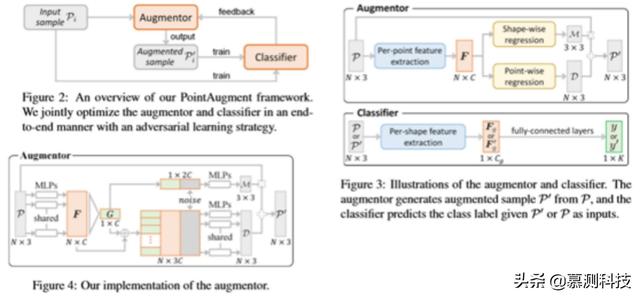
3. Overview这项工作的主要贡献是 PointAugment 框架 , 该框架自动优化输入点云样本的放大 , 以便更有效地训练分类网络 。 图 2 说明了框架的设计 , 有两个深层神经网络组件:(i)一个放大器 A 和(ii)一个分类器 C 。
在阐述 PointAugment 框架之前 , 首先讨论框架背后的关键思想 。 这些都是新的想法(在以前的作品[3,14,8]中没有出现) , 使能够有效地增加训练样本 , 这些样本现在是三维点云 , 而不是二维图像 。
- 样本感知 。 目标是通过考虑样本的基本几何结构 , 为每个输入样本回归一个特定的放大函数 , 而不是为每个输入数据样本找到一套通用的放大策略或过程 。 称之为样本感知的自动放大 。
- 2D 与 3D 放大 。 与二维图像放大不同 , 三维放大涉及更广阔和不同的空间域 。 应该考虑云的两种变形点(包括点云的变换和点云的变换)的放大(包括点云的变换和点云的变换) 。
- 联合优化 。 在网络训练过程中 , 分类器将逐渐学习并变得更加强大 , 因此需要更具挑战性的放大样本 , 以便更好地训练分类器 , 因为分类器变得更强 。 因此 , 以端到端的方式设计和训练 PointAugment 框架 , 这样就可以共同优化放大器和分类器 。 为此 , 必须仔细设计损失函数 , 动态调整增加样本的难度 , 同时考虑输入样本和分类器的容量 。
4.1. Network Architecture放大器 。 不同于现有的工作[3 , 14 , 8] , 放大器是样本感知的 , 学习生成一个特定的函数来放大每个输入样本 。 从现在起 , 为了便于阅读 , 去掉了下标 i , 并将 P 表示为 A 的训练样本输入 , P′表示 A 的相应放大样本输出 。 放大器的总体架构如图 3(上图)所示 。
 文章插图
文章插图
- 原来华为手机是开会神器,60秒输出500字,一键自动记录
- 搭建自己的云签到平台,解放双手每日自动签到-超详细
- 网络安全:如何使用MSFPC半自动化生成强大的木码?「下集」
- 面向销售自动化的基于数据扩增和真实图像合成的鲁棒多目标检测
- 不怕恶劣天气的芯片要来了,或让自动驾驶汽车视野更广无盲点
- 特斯拉全自动驾驶新测试版本数天内发布
- IntelliJ IDEA 如何设置自动下载源代码和文档
- 开发好物推荐9之自动生成在线接口+文档-Knife4j
- 微信打开这个功能,手机秒变扫描仪,扫描文档自动识别
- 京东|京东探索稀疏三维空间点云Global Context学习方法获认可