Python网络爬虫快速上手
环境准备:事先安装好 , pycharm打开File——>Settings——>Projext——>Project Interpriter
 文章插图
文章插图
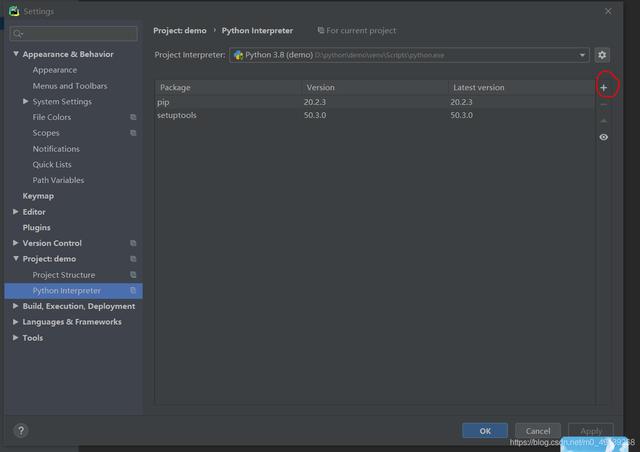
点击加号(图中红圈的地方)
 文章插图
文章插图
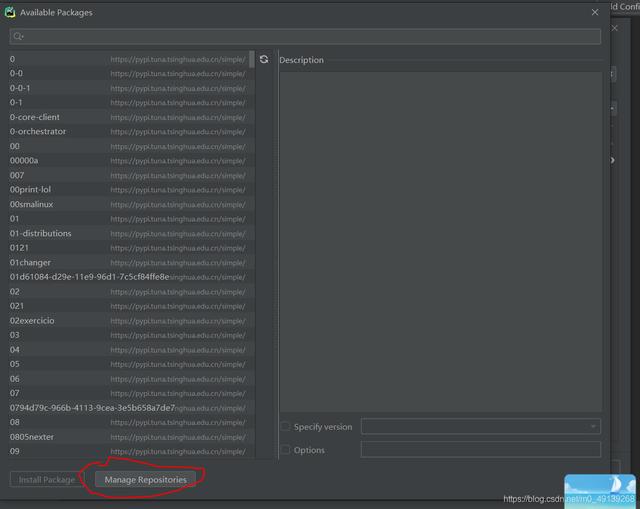
【Python网络爬虫快速上手】点击红圈中的按钮
 文章插图
文章插图
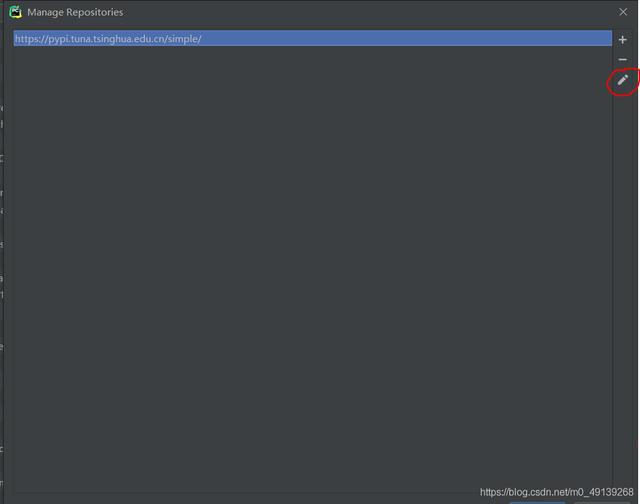
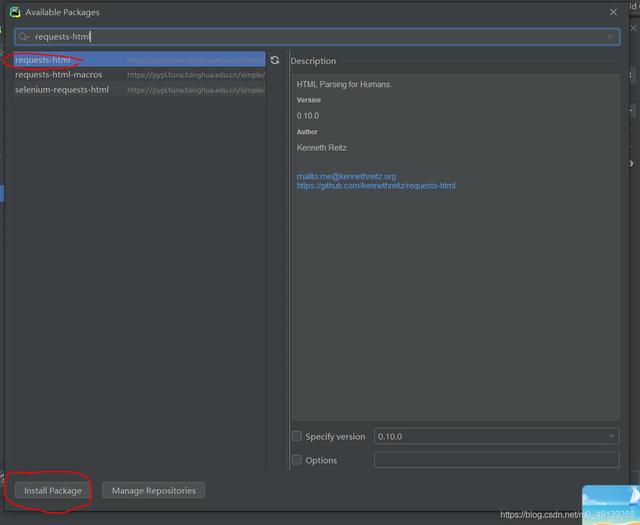
选中第一条 , 点击铅笔 , 将原来的链接替换为(这里已经替换过了):点击OK后 , 输入requests-html然后回车选中requests-html后点击Install Package
 文章插图
文章插图
等待安装成功 , 关闭
通过解析网页源代码实例内容:从某博主的所有文章爬取想要的内容 。 实例背景:从()博主的所有文章获取各文章的标题 , 时间 , 阅读量 。
- 导入requests_html中HTMLSession方法 , 并创建其对象
from requests_html import HTMLSessionsession = HTMLSession()123- 使用get请求获取要爬的网站,得到该网页的源代码 。
html = session.get("").html12- 找到所有文章
allBlog=html.xpath("//dl[@class='tab_page_list']") 1- 进入网站主页(本例: )
- 文章空白处右键检查可以定位到这文章的标签
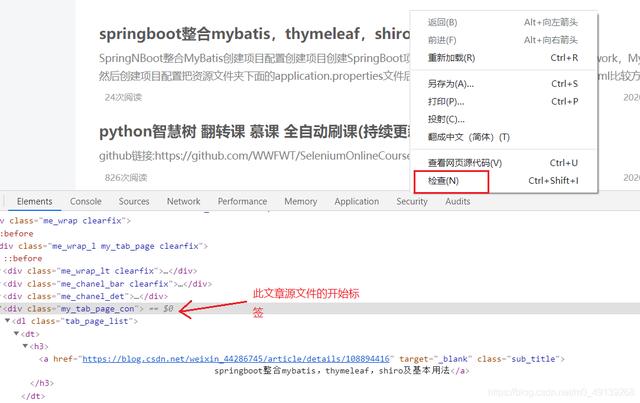 文章插图
文章插图- 其他文章一样操作 , 然后找到所有文章共同的标记(这里所有文章的class都是‘my_tab_page_con’)
- xpath 可以遍历html的各个标签和属性 , 来定位到我们需要的信息的位置 , 并提取 。
- 网页分析获取标题 , 阅读量 , 日期 。
for i in allBlog:title = i.xpath("dl/dt/h3/a")[0].textviews = i.xpath("//div[@class='tab_page_b_l fl']")[0].textdate = i.xpath("//div[@class='tab_page_b_r fr']")[0].textprint(title +' ' +views +' ' + date )12345网页分析:- 因为有多篇文章 , 分别获取使用for循环 , 上述代码已得到所有文章所以i表示一篇文章
- 第二行代码获取文章标题 , 于获取文章类似 , 鼠标放到标题上右键检查 , 因为文章只有一个标题所以用绝对路径也可以按标签一层层进到标题位置 。
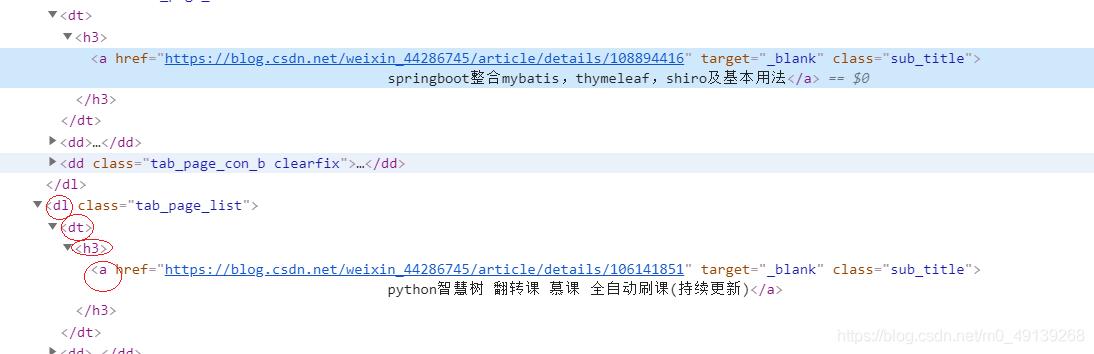 文章插图
文章插图- xpath返回的是列表 , 我们要第一个所以要加下标(列表里也只有一个元素) , 要输出的是文本 , 所以,text获取文本 。
- 阅读量和时间也是重复的操作
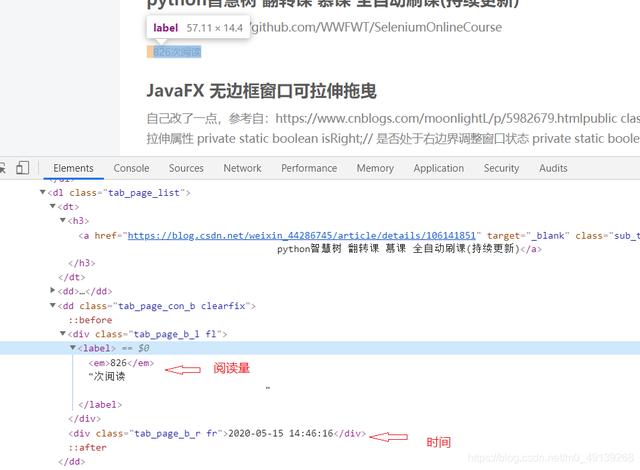 文章插图
文章插图- 可以用相对路径也可以用绝对路径 , 一般都是用相对路径 , 格式仿照代码 。
- 第五行代码 , 每得到一篇文章的信息就输出 , 遍历完就可以获得全部的信息 。
from requests_html import HTMLSessionsession = HTMLSession()html = session.get("").htmlallBlog=html.xpath("//dl[@class='tab_page_list']")for i in allBlog:title = i.xpath("dl/dt/h3/a")[0].textviews = i.xpath("//div[@class='tab_page_b_l fl']")[0].textdate = i.xpath("//div[@class='tab_page_b_r fr']")[0].textprint(title +' ' +views +' ' + date )1234567891011121314
- 第2天 | 12天搞定Python,运行环境(详细步骤)
- 退休主任医师的网络医生经验:一天最多能看20人 很要耐心
- Nginx服务器屏蔽与禁止屏蔽网络爬虫的方法
- 监控摄像头被黑!Mirai僵尸网络再作乱物联网设备成重灾区
- Python高级技巧:用一行代码减少一半内存占用
- 手把手教你用python编程写一款自己的音乐下载器
- 在图上发送消息的神经网络MPNN简介和代码实现
- Python爬虫入门第一课:如何解析网页
- 开启Scrapy爬虫之路!听说你scrapy都不会用?
- 刷爆全网的动态条形图,只需5行Python代码就能实现