开启Scrapy爬虫之路!听说你scrapy都不会用?
摘要七夜大佬的《python爬虫开发与项目实战》 , 买了好多年了 , 学习了好多东西 , 基本上爬虫都是在这里面学的 , 后期的scrapy框架爬虫一直不得门而入 , 前段时间补了下面向对象的知识 , 今天突然顿悟了!写个笔记记录下学习过程
1.scrapy安装# -i参数后跟清华镜像源 , 加速下载 , 其他pip的包也可这么操作pip install Scrapy -i测试如下图表示安装成功
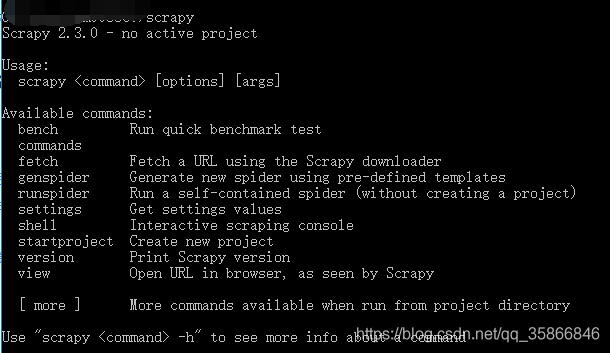 文章插图
文章插图
其他参考方法:win7安装scrapy
2.相关命令介绍scrapy命令分为
- 全局命令:全局命令就是在哪都能用;
- 项目命令:项目命令就是只能依托你的项目;
startproject、genspider、settings、runspider、shell、fetch、view、version
比较常用的有三个:
scrapy startproject project_name # 创建项目scrapy crawl spider_name # 运行名为spider_name的爬虫项目# 调试网址为的网站scrapy shell ""全局命令就是不依托项目存在的 , 也就是不关你有木有项目都能运行 , 比如:startproject它就是创建项目的命令 , 肯定是没有项目也能运行;详细用法说明:
- startproject# 使用频次最高 , 用于项目创建 , eg:创建一个名为:cnblogSpider的项目 scrapy strartproject cnblogSpider
# 用于创建爬虫模板 , example是spider名称,生成文件在spiders下面 , 也是后面写爬虫的地方# 注意spider名称不能和项目相同scrapy genspider example example.com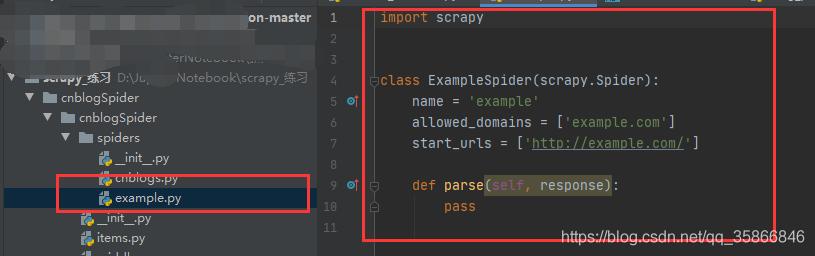 文章插图
文章插图settings
# 查看scray参数设置scrapy settings --get DOWNLOAD_DELAY # 查看爬虫的下载延迟scrapy settings --get BOT_NAME # 爬虫的名字【开启Scrapy爬虫之路!听说你scrapy都不会用?】runspider运行蜘蛛除了使用前面所说的scrapy crawl XX之外 , 我们还能用:runspider;crawl是基于项目运行 , runspide是基于文件运行 , 也就是说你按照scrapy的蜘蛛格式编写了一个py文件 , 如果不想创建项目 , 就可以使用runspider , eg:编写了一个:test.py的蜘蛛 , 你要直接运行就是:scrapy runspider test.pyshell# 这个命令比较重要 , 主要是调试用 , 里面还有很多细节的命令# 最简单常用的的就是调试 , 查看我们的选择器到底有木有正确选中某个元素scrapy shell ""# 然后我们可以直接执行response命令 , #比如我们要测试我们获取标题的选择器正不正确:response.css("title").extract_first()# 以及测试xpath路径选择是否正确response.xpath("//*[@id='mainContent']/div/div/div[2]/a/span").extract()- fetch这个命令其实也可以归结为调试命令的范畴!它的功效就是模拟我们的蜘蛛下载页面 , 也就是说用这个命令下载的页面就是我们蜘蛛运行时下载的页面 , 这样的好处就是能准确诊断出 , 我们的到的html结构到底是不是我们所看到的 , 然后能及时调整我们编写爬虫的策略!举个栗子 , 淘宝详情页 , 我们一般看得到 , 但你如果按常规的方法却爬不到 , 为神马?因为它使用了异步传输!因此但你发现获取不到内容的时候 , 你就要有所警觉 , 感觉用fetch命令来吧它的html代码拿下来看看 , 到底有木有我们想要的那个标签节点 , 如果木有的话 , 你就要明白我们需要使用js渲染之类的技术!用法很简单:scrapy fetch http://www.scrapyd.cn 1就这样 , 如果你要把它下载的页面保存到一个html文件中进行分析 , 我们可以使用window或者linux的输出命令 , 这里演示window下如下如何把下载的页面保存:scrapy fetch http://www.scrapyd.cn >d:/3.html 1可以看到 , 经过这个命令 , scrapy下载的html文件已经被存储 , 接下来你就全文找找 , 看有木有那个节点 , 木有的话 , 毫无悬念 , 使用了异步加载!
- Nginx服务器屏蔽与禁止屏蔽网络爬虫的方法
- Python爬虫入门第一课:如何解析网页
- 阿里旗下云盘(teambition)公测通道开启
- 专栏丨当代“爬虫”现状
- 太火!华为Mate40 RS保时捷设计开启抽签购买模式
- 三大运营商开启清网战略,5G网络成本过高,只能壮士断腕
- 速抢!OPPO Find X2英雄联盟S10限定版开启预约
- 真旗舰?iGame Z490 VulcanX的科学开启指南
- 马云终于不再“仁慈”?开启全面收费,喜欢网购的一定要看
- 爬虫程序优化要点—附Python爬虫视频教程