「机器学习」截取caffe模型中的某层
通常情况下 , 训练好的caffe模型包含两个文件:
- prototxt:网络结构描述文件 , 存储了整个网络的图结构;
- caffemodel:权重文件 , 存储了模型权重的相关参数和具体信息
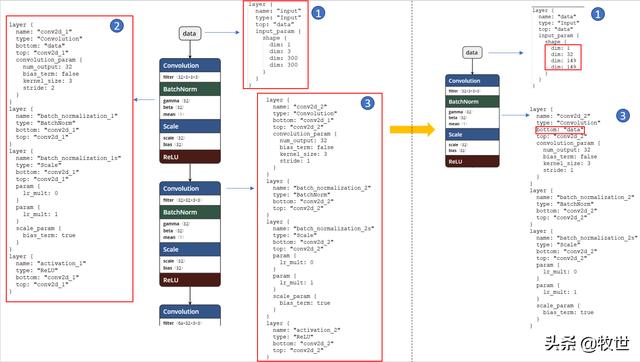
修改prototxt以Inception模型为例 , 如下图左则为使用Netron可视化的模型前3层及prototxt描述的内容 , 假设要截取第3层 , 修改后的模型如下图右则所示 , 修改方法为:
- 修改输入数据的维度为第2层的输出维度
- 删除第2层以及第3层后的所有层
- 修改第3层的bottom值为第一层的top值
 文章插图
文章插图截取权重数据首先要下载caffe源码
git clone 然后使用caffe的python接口读取修改后的prototxt和原始的权重文件caffemodel , 接着重新推理 , 最后保存新的权重文件 。【「机器学习」截取caffe模型中的某层】
import syscaffe_root='/your/path/caffe'sys.path.insert(0, caffe_root + '/python')import caffenet = caffe.Net("Inception.prototxt", "Inception.caffemodel", caffe.TRAIN)res = net.forward()net.save('Inception_conv2d_2.caffemodel')
- 系统性学习Node.js(5)—手写 fs 核心方法
- 我们是后浪|机器人,“乖乖听话”
- 使用半监督学习从研究到产品化的3个教训
- Rust语言学习:Beginning_Rust
- 如何编写JAVA小白第一个程序
- 不需要负样本对的SOTA的自监督学习方法:BYOL
- Linux培训完能到什么水平,之后还需要学习哪些技术?
- 抢险探测应急救援消防灭火 中国智能特种机器人都在这
- 宁夏举办第35届青少年科技创新大赛机器人竞赛项目
- 擎朗送餐机器人在2020国际智能机器人博览会打造智慧商业模式