不需要负样本对的SOTA的自监督学习方法:BYOL
作者:Abe Fetterman , Josh Albrecht
编译:ronghuaiyang
导读
对自监督学习中学习的本质进行剖析 , 扩展了对比学习中负样本的概念 , 并不是一定要使用不同的图像才可以产生负样本 , batch normalization同样也可以产生负样本 。
概要与之前工作SimCLR和MoCo不同 , 最近的一篇来自DeepMind的论文"Bootstrap Your Own Latent" 展示了一个先进的自监督学习的方法 , 不需要明确的对比损失函数 。 通过消除损失函数中对负样本的需要 , 简化了训练 。 我们复现BYOL的时候 , 强调了两个令人惊讶的发现:
(1)在删除batch normalization时 , BYOL的性能通常不比random好
(2)batch normalization的存在隐式地导致了一种对比学习的形式
这些发现强调了在学习表征时正样本和负样本对比的重要性 , 并帮助我们更基本地理解自监督学习是如何以及为什么有效的 。
论文代码:https://github.com/untitled-ai/self_supervised
为什么自监督学习很重要?机器学习通常是在“监督”的方式下完成的:我们使用一个由输入和“正确答案”(输出)组成的数据集 , 来找到从输入数据映射到正确答案的最佳函数 。 相比之下 , 在自监督学习中 , 在数据集中没有正确的答案 , 因此我们学习一个函数 , 把输入数据映射输入到本身(比如:使用图像的右半部分预测图像的左半部分) 。
从语言到图像和音频 , 这种方法已经被证明是成功的 。 事实上 , 最近的语言模型 , 从word2vec到BERT和GPT-3 , 都是自监督方法的例子 。 最近 , 这种方法在音频和图像方面也取得了一些令人难以置信的成果 , 而且[一些人相信]( -self- learning- isketo -human-级智能/全文) , 它可能是类人智能的一个重要组成部分 。 这篇文章关注的是图像表示的自监督学习 。
自监督学习中的SOTA对比学习在BYOL发布之前 , 性能最好的算法是MoCo和SimCLR 。 MoCo和SimCLR都是对比学习的例子 。
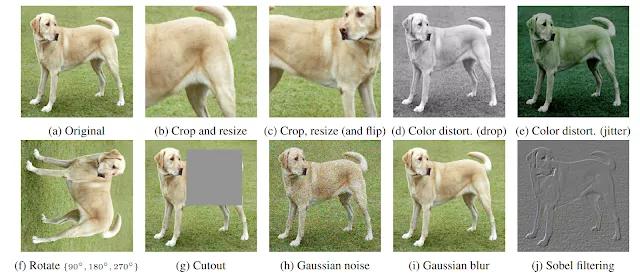
对比学习是训练分类器区分“相似”和“不同”输入数据的过程 。 具体到MoCo和SimCLR , 分类器的正样本是同一幅图像的不同的修改版本 , 负样本是同一数据集中的其他图像 。 假设有一张狗的图片 。 在这种情况下 , 正样本可以是对该图像的不同的crop , 而负样本可以是来自完全不同的图像的crop 。
 文章插图
文章插图
狗的原始图片的增强版本(a) 。 其中任何两个都可以用作是正样本对 。
BYOL: 不需要对比学习的自监督学习?并不完全是 。 MoCo和SimCLR在其损失函数中使用正样本和负样本的对比学习 , 而BYOL在损失函数中只使用正样本 。 乍一看 , BYOL似乎在进行自监督学习的时候完全没有对比不同的图像 。 然而 , BYOL能起作用的主要原因似乎是它确实是在做一种对比学习 —— 只不过是通过一种间接的机制 。
为了更深入地理解BYOL中的这种间接的对比学习 , 我们应该首先回顾一下这些算法是如何工作的 。
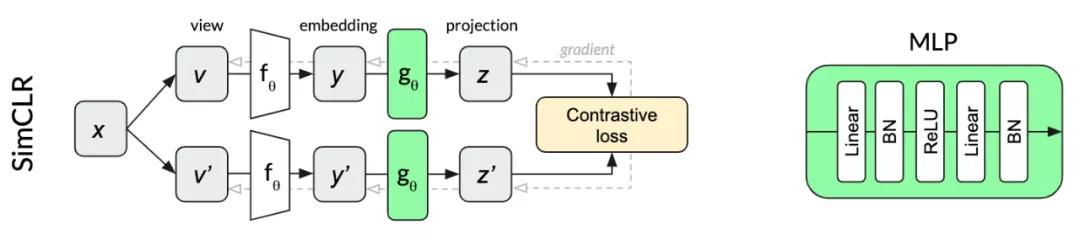
SimCLRSimCLR是一个特别优雅的自监督算法 , 它简化了以前的方法 , 使其成为核心 , 并提高了性能 。 同一幅图像x的两个变换v和v ' 通过同一个网络产生两个投影z和z ' 。 对比损失的目的是使同一个输入x的两个投影的相似度最大化 , 同时使同一个minibatch内其他图像的投影相似度最小化 。 继续使用我们的狗的例子 , 对同一张狗的图像进行不同的crop投影要比从其他随机图像中的crop在同个batch中更相似 。
在SimCLR中用于投影的多层感知器(MLP)在每个线性层之后使用batch normalization 。
 文章插图
文章插图
SimCLR结构
MoCo相对于SimCLR, MoCo v2能够减少batch size(从4096减少到256)并提高性能 。 不像SimCLR , 两个网络共享相同的参数、MoCo将单一网络分为一个
- 为什么苹果手机不需要“杀毒软件”?看完答案后,又涨知识了
- 中国手机市场没有绝对的“硬骨头”,苹果也要妥协,12又降价了
- 雷军签名版小米11曝光:绝对的理财产品
- 扫码枪将钱扫走,却不需要密码,安全吗?
- 松山湖科学城打造美好生活样本
- 下沉市场不需要巨头,但很需要社区团购
- 为何谷歌、脸书都热衷黑客马拉松?百度的选择或许是对的
- “朋友圈”寻人只需8小时,互联网需要正能量,不需要巨头卖菜
- leetcode哈希表之好数对的数目
- 毕亚兹Type-C拓展坞评测:不买贵的只买对的,四口足矣