
文章图片

文章图片
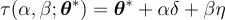
文章图片

文章图片

文章图片

前言一般情况下我们都是使用折线图绘制和监控我们的损失函数 ,y 轴是损失函数的值 , x 轴是训练的轮次 。这种情况下我们只有损失函数空间的一维视图 , 并且只能看到小范围的参数梯度 。
有没有一种方法能够让我们将的GPT的1750亿参数损失空间进行可视化呢?如果可以的话 , 那么这数十亿个参数的梯度会怎样?虽然理论上是可行的 , 但是这么大的参数对于我们现在的硬件条件来说还是不可行的 , 但是如果我们至少可以在一个小维度(比如 , 3维)空间中看到损失图像 , 这样是否可行呢?这篇介绍性文章简要说明了它是如何实现的 , 以及它是一个多么简单而又引人入胜的想法 。
You can’t step past [someone
in this [two
dimension. Observe this two-dimensional egg. If we were in the third dimension looking down we’d be able to see an unhatched chick in it just as a chick inside a three-dimensional egg could be seen by an observer in the fourth dimension
Prof. Farnsworth Futurama E15S7
在训练神经网络时 , 我们绘制的损失函数会根据模型架构、优化器、初始化方法等不同配置而不同 。虽然这些选择对最终目标的影响尚不清楚 , 但是我们可以将损失函数的收敛进行可视化 , 这不仅是为了好玩 , 也是为了深入了解训练的过程以及结果 。 损失函数三维图的有助于解释为什么神经网络可以优化极其复杂的非凸函数 , 以及为什么优化的最小值能够很好地被推广 。(例如 , 通过这种可视化观察到了对残差连接的一个有用的现象:它们可以防止模型将损失三维图变得混乱 , 因此在训练中很有用 [3
) 。
数据集为简单起见本文使用 MNIST 数据集 , 并探讨了可视化的几个方面 。更多关于其他数据集和这个想法方面的学术研究可以在关于这个问题的论文中找到 [2 3 4
首先让我们配置dataset和dataloader
from torchvision import transforms as T
transform = T.Compose([
T.ToTensor()
T.Resize((2828))
T.Normalize((0.1307) (0.3081))
)
dataset = Dataset(root='data' download=True train=False transform=transform)
dataloader = torch.utils.data.DataLoader(dataset
batch_size=len(dataset)
pin_memory=True num_workers=4)
目标然后 , 我们设 \uD835\uDEC9 是一个神经网络中所有参数的列表 。令\uD835\uDCDB(\uD835\uDC66 \uD835\uDC61; \uD835\uDEC9) 作为损失函数 , 其中\uD835\uDC66 是预测 , \uD835\uDC61 是目标 。我们通常绘制 \uD835\uDCDB 的收敛性以可视化 \uD835\uDC66 和 \uD835\uDC61 之间的差异 。但是在这里我们的目标略有不同 。 我们要让这个损失函数的输入 \uD835\uDC66 和 \uD835\uDC61 保持不变 。换句话说 , 我们打算绘制的图是 关于\uD835\uDEC9 的函数 , 即\uD835\uDCDB(\uD835\uDEC9; \uD835\uDC66 \uD835\uDC61) , 或者简称为\uD835\uDCDB(\uD835\uDEC9) 。我们要绘制的是对于一个给定的域 , 我们对网络架构、优化器、损失函数等的配置在图形上表现是什么样的 。
import torch
from torch.nn import functional as F
class Net(torch.nn.Module):
def __init__(self):
super(Net self).__init__()
self.conv1 = torch.nn.Conv2d(1 32 (33))
self.conv2 = torch.nn.Conv2d(32 64 (33))
self.drop1 = torch.nn.Dropout2d(0.25)
self.drop2 = torch.nn.Dropout2d(0.5)
self.fc1 = torch.nn.Linear(9216 128)
self.fc2 = torch.nn.Linear(128 10)
def forward(self x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.drop1(F.max_pool2d(x 2))
- Linux|整理了10个行业的30份可视化大屏模板,可直接拿走套用
- 高黎贡山|Facebook进元宇宙,快手入新市井,都有美好的未来
- 腾讯|新市井商业,与超5亿老铁共同进击
- 干旱|冰岛开打全球首个岩浆井
- |狂蟒之灾——井里全是蛇
- Netflix|助力网络安全发展,安全态势攻防赛事可视化
- 航天|智慧航天,数字孪生货运飞船运行可视化
- 北新桥|科学解密“锁龙井”拉不完的铁链,真的锁着龙吗?
- 马云|马云成立大井头,5名顾问月薪125万元,只为调动四大势力背后资源
- 无底洞|科拉钻井:是否真的存在“无底洞”?可以确定并不是什么地狱