美团|美团面试题:JDK1.7和1.8的HashMap有哪些区别?

文章图片

文章图片

文章图片
文章图片
文章图片
文章图片
我们了解过了JDK1.7和1.8的HashMap源码 , 今天来总结下JDK1.7和1.8的Hashmap有哪些区别?这个问题也是大厂面试中最常问到的问题 。
一、JDK1.7和1.8的Hashmap有哪些区别?1、JDK1.7用的是头插法 , 而JDK1.8及之后使用的都是尾插法
JDK1.7是用单链表进行的纵向延伸 , 当采用头插法时会容易出现逆序且环形链表死循环问题 。 但是在JDK1.8之后使用尾插法 , 能够避免出现逆序且链表死循环的问题 。
2、扩容后数据存储位置的计算方式不一样
【美团|美团面试题:JDK1.7和1.8的HashMap有哪些区别?】在JDK1.7的时候是直接用hash值和需要扩容的二进制数进行&运算 , 见下图:
JDK1.8是扩容前的原始位置+扩容的大小值=JDK1.8的计算方式 , 而不再是JDK1.7中异或的方法 。 扩容后长度为原hash表的2倍 , 于是把hash表分为两半 , 分为低位和高位 , 如果能把原链表的键值对 ,一半放在低位 , 一半放在高位 , 而且是通过e.hash & oldCap == 0来判断 , 见下图:
e.hash & oldCap == 0 , 这个判断有什么优点呢?
举个例子:n = 16 , 二进制为10000 , 第5位为1 , e.hash & oldCap 是否等于0就取决于e.hash第5 位是0还是1 , 这就相当于有50%的概率放在新hash表低位 , 50%的概率放在新hash表高位 。
3、hash计算规则不一样
在计算hash值的时候 , JDK1.7用了9次扰动处理=4次位运算+5次异或 , 见下图:
而JDK1.8只用了2次扰动处理=1次位运算+1次异或 , 见下图:
4、底层数据结构不一样
JDK1.7使用的是数组+ 单链表的数据结构 。 但是在JDK1.8及之后时 , 使用的是数组+链表+红黑树的数据结构(当阈值是默认阈值0.75 , 链表的深度大于等于8 , 扩容的时候会把链表转成红黑树 , 时间复杂度从O(n)变成O(logN))
接下来看下关于HashMap的其他问题
二、哈希表如何解决Hash冲突?
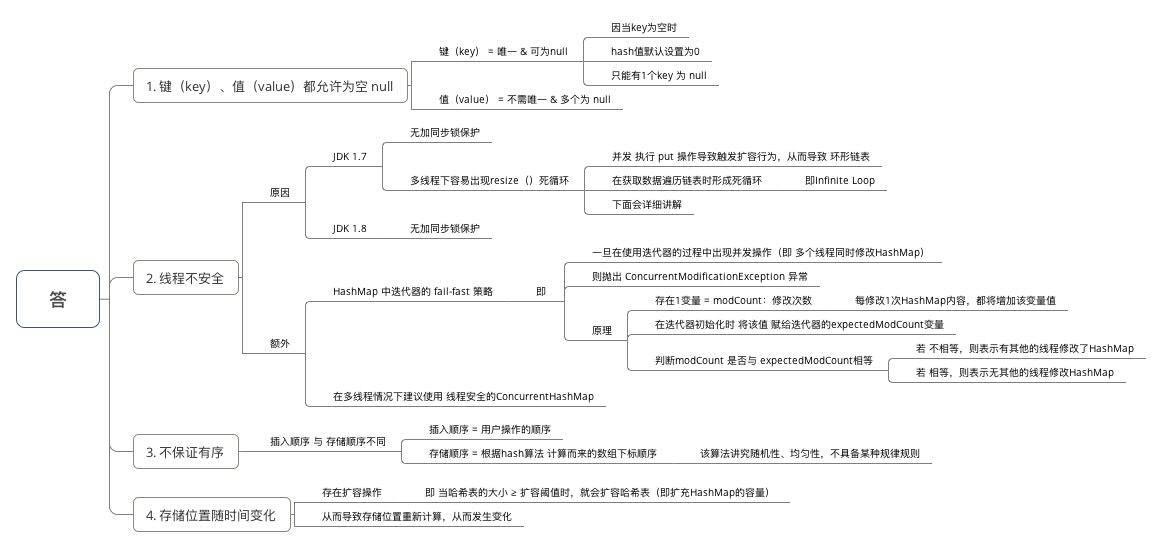
三、为什么HashMap具备那些特点?键-值(key-value)都允许为空、线程不安全、不保证有序、存储位置随时间变化
四、为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
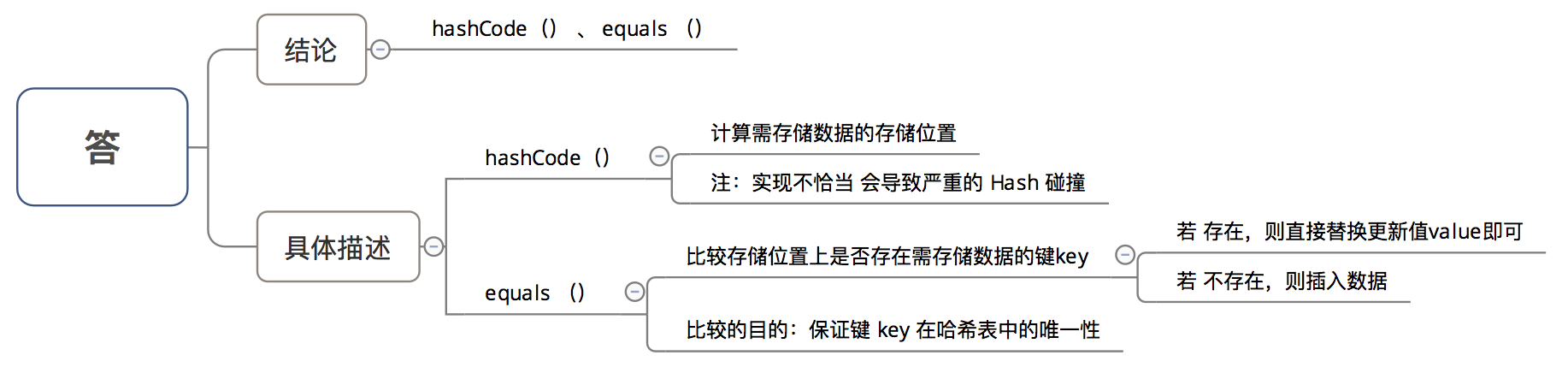
五、HashMap 中的 key若 Object类型 ,则需实现哪些方法?
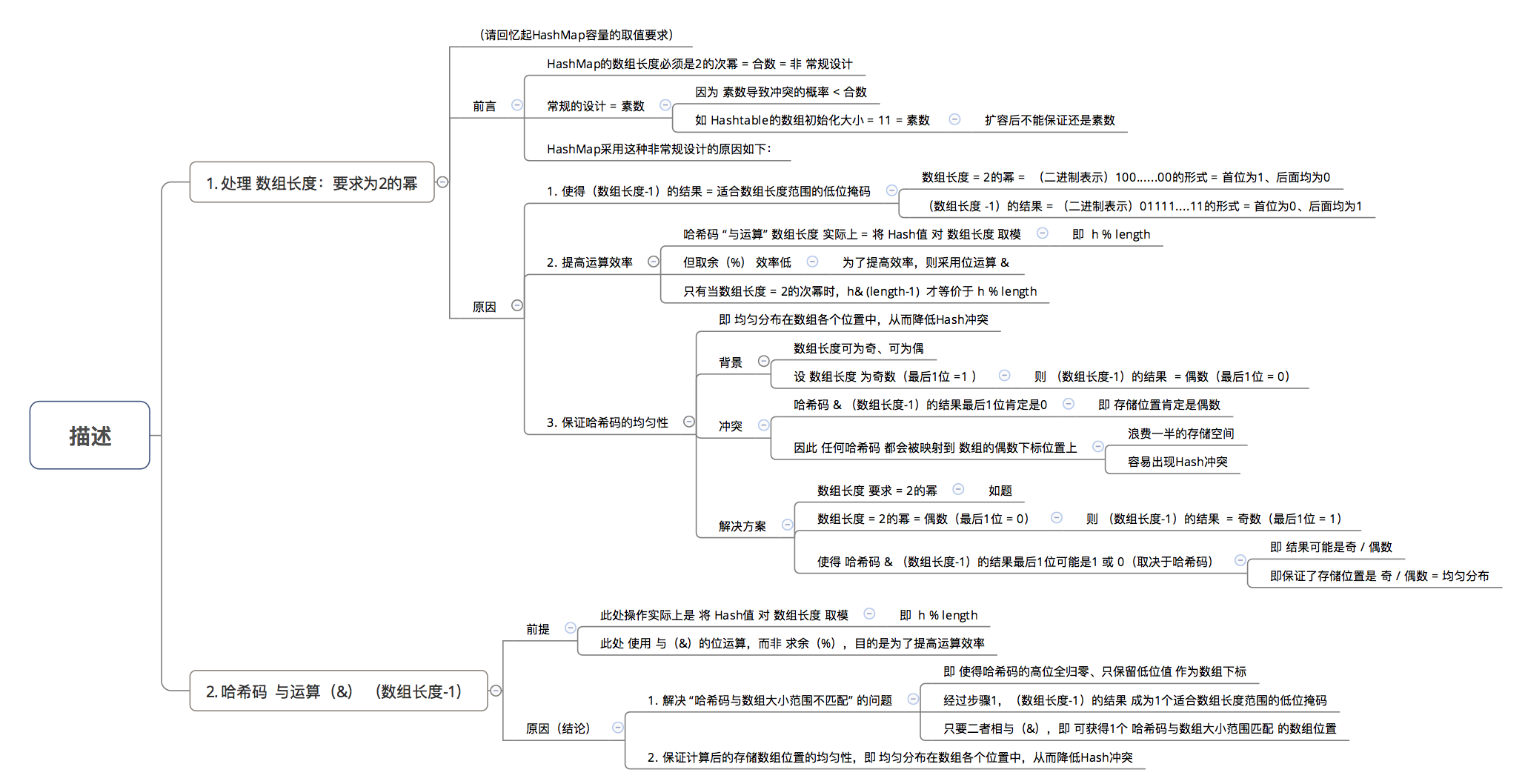
六、为什么不直接采用经过hashCode()处理的哈希码作为存储数组table的下标位置?容易出现哈希码与数组大小范围不匹配的情况 , 即计算出来的哈希码可能不在数组大小范围内 , 从而导致无法匹配存储位置
七、为什么采用 哈希码 与运算(&) (数组长度-1) 计算数组下标?根据HashMap的容量大小(数组长度) , 按需取 哈希码一定数量的低位作为存储的数组下标位置 , 从而解决 “哈希码与数组大小范围不匹配” 的问题
- 摩拜单车|那个曾经将摩拜单车卖给美团的创始人,套现27亿后,现在过得如何
- 美团|如果完全没有中间商赚差价,会对整个经济产生什么影响?
- 蚂蚁花呗|美团,无人配送
- 美团|美团招员工也是与劳务派遣公司合作,那么劳务派遣服务是?
- 美团|黄峥后院起火:美团杀入拼多多腹地
- 胡玮炜|那个将摩拜单车卖给美团,套现27亿的女记者,如今在干什么?
- 美团|3天亏掉600亿,仍还要养活400万人?美团的钱都进了谁的口袋?
- 外卖小哥|美团外卖小哥电梯内瘫倒,下一秒满血复活,状态无缝切换让人泪目
- 美团点评|10年美团,是否会开出“恶之花”?
- 美团|谁雇佣了世界上最庞大的一支员工队伍?美团399万骑手当之无愧