
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
文章图片

文章图片

前言
HashMap是一个非常重要的集合 , 日常使用也非常的频繁 , 同时也是面试重点 。
本文并不打算讲解基础的使用api , 而是深入HashMap的底层 , 讲解关于HashMap的重点知识 。 需要读者对散列表和HashMap有一定的认识 。
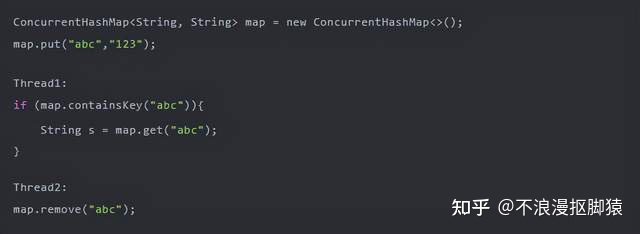
HashMap本质上是一个散列表 , 那么就离不开散列表的三大问题:散列函数、哈希冲突、扩容方案;同时作为一个数据结构 , 必须考虑多线程并发访问的问题 , 也就是线程安全 。 这四大重点则为学习HashMap的重点 , 也是HashMap设计的重点 。
HashMap属于Map集合体系的一部分 , 同时继承了Serializable接口可以被序列化 , 继承了Cloneable接口可以被复制 。 他的的继承结构如下:
HashMap并不是全能的 , 对于一些特殊的情景下的需求官方拓展了一些其他的类来满足 , 如线程安全的ConcurrentHashMap、记录插入顺序的LinkHashMap、给key排序的TreeMap等 。
文章内容主要讲解四大重点:散列函数、哈希冲突、扩容方案、线程安全 , 再补充关键的源码分析和相关的问题 。
本文所有内容如若未特殊说明 , 均为JDK1.8版本 。
哈希函数
哈希函数的目标是计算key在数组中的下标 。 判断一个哈希函数的标准是:散列是否均匀、计算是否简单 。
HashMap哈希函数的步骤:
- 对key对象的hashcode进行扰动
- 通过取模求得数组下标
static final int hash(Object key) {
int h;
// 获取到key的hashcode , 在高低位异或运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
也就是低16位是和高16位进行异或 , 高16位保持不变 。 一般的数组长度都会比较短 , 取模运算中只有低位参与散列;高位与低位进行异或 , 让高位也得以参与散列运算 , 使得散列更加均匀 。 具体运算如下图(图中为了方便采用8位进行演示 , 32位同理):
对hashcode扰动之后需要对结果进行取模 。 HashMap在jdk1.8并不是简单使用%进行取模 , 而是采用了另外一种更加高性能的方法 。 HashMap控制数组长度为2的整数次幂 , 好处是对hashcode进行求余运算和让hashcode与数组长度-1进行位与运算是相同的效果 。 如下图:
但位与运算的效率却比求余高得多 , 从而提升了性能 。 在扩容运算中也利用到了此特性 , 后面会讲 。 取模运算的源码看到putVal()方法 , 该方法在put()方法中被调用:
final V putVal(int hash K key V value boolean onlyIfAbsent
boolean evict) {
...
// 与数组长度-1进行位与运算 , 得到下标
if ((p = tab[i = (n - 1) & hash
) == null)
...
完整的hash计算过程可以参考下图:
上面我们提到HashMap的数组长度为2的整数次幂 , 那么HashMap是如何控制数组的长度为2的整数次幂的?修改数组长度有两种情况:
- 初始化时指定的长度
- 扩容时的长度增量
- 德尔塔|新冠病毒“最厉害变种”来袭,或从艾滋病患者体内进化而来
- 免疫系统|新冠最新毒株!比德尔塔还厉害,疫苗还管用吗?
- 飞利浦·斯塔克|MySQL统计总数就用count,别花里胡哨的《死磕MySQL系列 十》
- 飞利浦|飞利浦今年第2款智能手机上市,名为PH2线上首发价仅759元,面向百元级市场
- 科学家|?又?一变异株出现,或已攻入亚洲!科学家严厉警告,比德尔塔还可怕
- 飞利浦·斯塔克|中国广电将从五个方面推动网络建设:第四家运营商服务越来越近!
- |价值千万的核磁共振仪有多厉害?为什么我国造不出来,只能进口?
- 国际热核聚变实验堆|再冲新高,1亿摄氏度“燃烧”100秒?中国“人造太阳”有多厉害
- |最厉害的成功学是什么?
- |揭秘人体极限,来看看自己究竟有多厉害!