clip|打破GANs“垄断”|OpenAI新研究:Diffusion Models 图文转换效果超越DALL-E( 二 )
受引导扩散模型生成逼真样本的能力以及文本到图像模型处理自由形式提示的能力的启发,研究人员将引导扩散应用于文本条件图像合成问题。首先,作者们训练了一个 35 亿参数扩散模型,该模型使用文本编码器以自然语言描述为条件。接下来,他们比较了两种将扩散模型引导至文本提示的技术:CLIP 引导和无分类器引导。使用人工和自动评估,发现无分类器的指导产生更高质量的图像。
研究人员发现GLIDE模型中,无分类器指导生成的样本栩栩如生,图像还蕴涵着广泛的世界知识。由人类参与者评估后,普遍给出评价:GLIDE“创造”的效果优于 DALL-E。

文章插图
论文的作者们分别在ImageNet 128×128上达到2.97的FID,在ImageNet 256×256上达到4.59的FID,在ImageNet512×512上达到7.72的FID,并且即使每个样本只有25次正向传递,其生成图像质量依然可以匹配BigGAN-deep,同时保持了更好的分布覆盖率(多样性)。
最后,作者团队发现分类器指导与上采样扩散模型可以很好地结合在一起,从而将ImageNet512×512上的FID进一步降低到3.85。
DeepMind曾于2018年在一篇 ICLR 2019 论文中提出了BigGAN,当时一经发表就引起了大量关注, 很多学者都不敢相信AI竟能生成如此高质量的图像,这些生成图像的目标和背景都相当逼真,边界也很自然。

文章插图
如今,Alex Nichol和Prafulla Dhariwal两位学者提出的扩散模型,终于可在图像合成上匹敌BigGAN。

文章插图
扩散模型是一类基于似然度的模型,最近被证明可用于生成高质量图像,同时保留理想的属性,如更高的分布覆盖率、稳定的训练目标和更好的可扩展性。这些模型通过逐步去除信号中的噪声来生成样本,其训练目标可以表示为一个重新加权的变分下界。
Nichol和Dhariwal发现,随着计算量的增加,这些模型不断改进,即使在高难度ImageNet256×256数据集上也能生成高质量的样本。
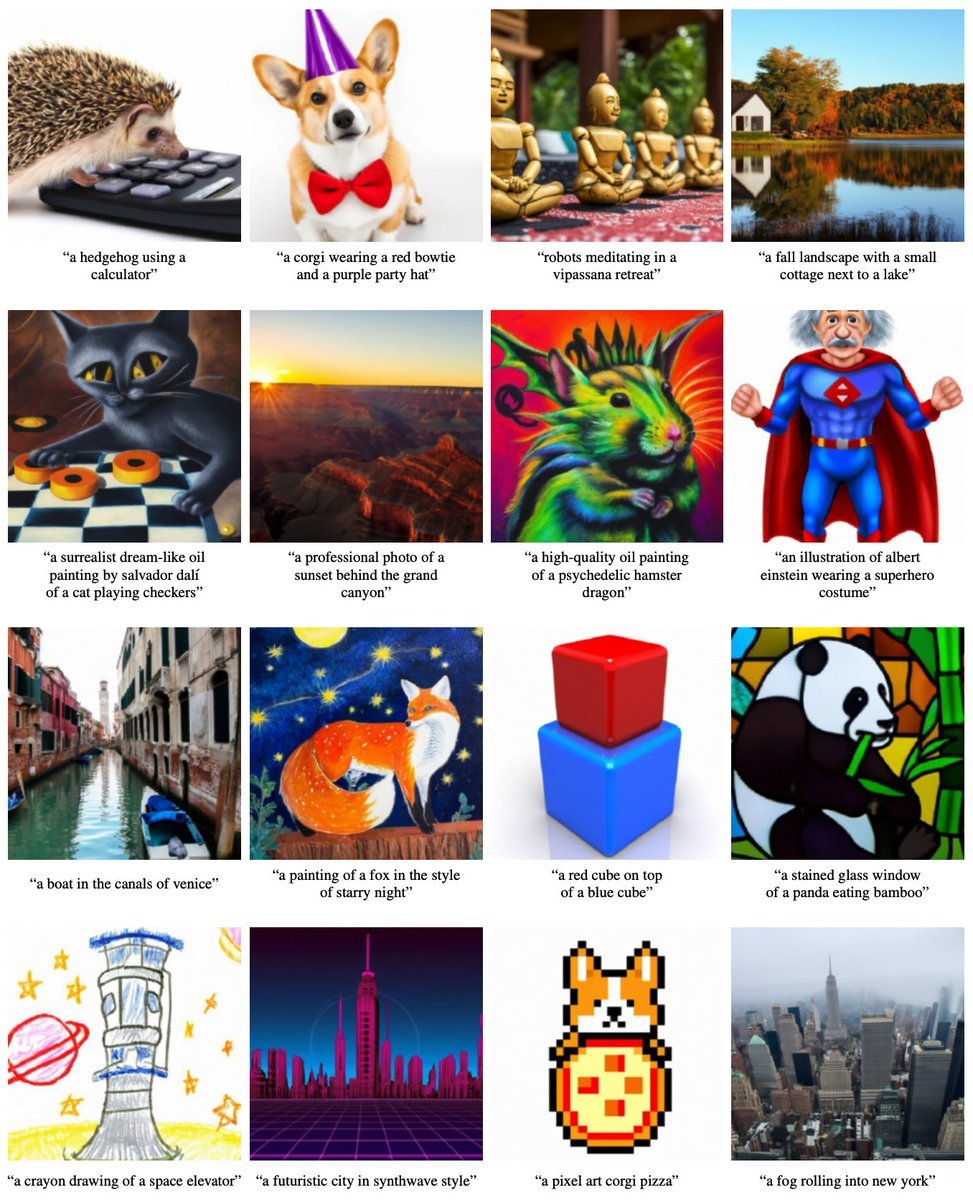
再来看看GLIDE的生成效果。下图是GLIDE基于不同的文本提示生成的16个图像集,例如“使用计算器的刺猬”、“戴着红色领带和紫色帽子的柯基”等等,如图所示,生成的图像基本符合文本描述。
文章插图
美中不足的是,这项研究发布的较小模型的准确性不如全尺寸模型那么完美。下图是由“刺猬”文本提示生成的16个样本。

文章插图
除了图文转换,该论文还包括一个交互式系统的原型,用于逐步细化图像的选定部分。这些图像中的一切都是自动生成的,从整个房间开始,对绿色区域进行迭代细化。

文章插图
在下图中,研究人员将他们的模型与之前最先进的基于MS-COCO字幕的文本条件图像生成模型进行了比较,发现其模型在无需CLIP 重新排序或挑选的情况下生成了更逼真的图像。对于XMC-GAN,从用于文本到图像生成的跨模态对比学习采集了样本。对于DALL-E,在温度0.85下生成样本,并使用CLIP重新排序从256个样本中选择最好的。对于GLIDE,使用2.0刻度的CLIP引导和3.0刻度的无分类器引导。作者没有为GLIDE执行任何CLIP重新排序或挑选。

文章插图
研究人员使用人类评估协议将GLIDE与DALL-E进行比较(如下表所示)。请注意,GLIDE使用的训练计算与DALL-E大致相同,但模型要小得多(35亿对120亿参数)。此外,它只需要更少的采样延迟,并且没有CLIP 重新排序。

文章插图
研究人员在DALL-E和GLIDE之间执行三组比较。首先,当不使用CLIP重新排序时,比较两种模型。其次,只对DALL-E使用CLIP重新排序。最后,对DALL-E使用CLIP重新排序,并通过DALL-E使用的离散VAE投影GLIDE样本。后者允许研究者评估DALLE模糊样本如何影响人类的判断。他们使用DALL-E模型的两个温度来进行所有的评估,其模型在所有设置中都受到人类评估人员的青睐,即使在非常支持DALL-E的配置中,也允许它使用大量的测试时间计算(通过CLIP重新排序)同时降低GLIDE样本质量(通过VAE模糊)。
- vivo|vivoX80Pro+曝光:打破传统束缚,性能与美的碰撞
- Linux|启中教育:直通车很烧钱?如何打破?
- 阿里巴巴|阿里自研赶跑外资,为马云省下几百亿,彻底打破外资垄断
- 光刻胶|徐州博康将光刻胶纯度提升10倍,打破日企垄断,华为加码3亿
- 芯片|清华大学不负众望,打破芯片领域技术限制,成功出货核心设备!
- 红米手机|打破技术封锁,K50电竞版加持国产A+原色屏,比DC调光更护眼
- 华为|正式发布,华为官宣新消息!外媒:这是要彻底打破
- 半导体|又一领域打破垄断,良率99.99%,性能逼近三星,华为率先提供支持
- ar眼镜|Java培训:如何通过几次点击加速 Eclipse
- 空间站|骄傲!5G只是其中之一,这四大重器看中国打破西方垄断