领域|IEEE Fellow梅涛:视觉计算的前沿进展与挑战( 二 )
文章插图
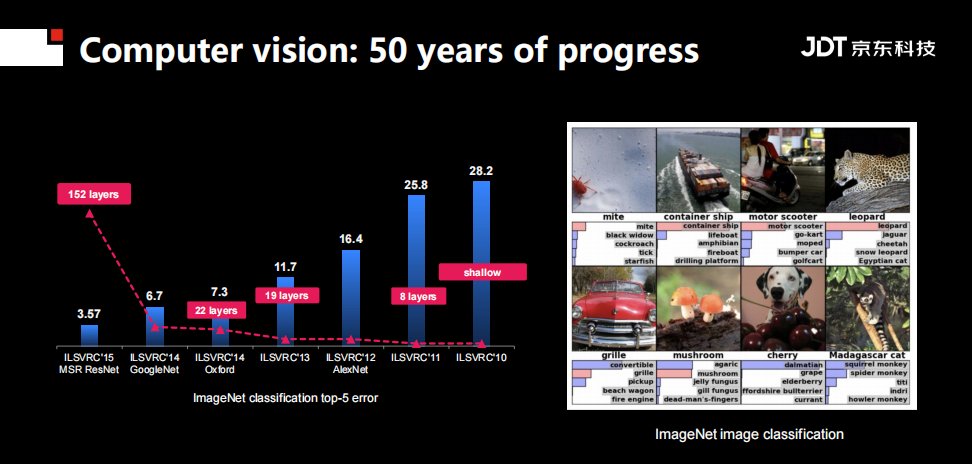
特定领域进展如何?在图像识别领域,最广为人知莫过于ImageNet竞赛。其任务是给定一张图,预测出五个相关的标签。随着深度学习网络的层数越来越深,识别的错误率越来越低,到2015年, ResNet已经它达到了152层,并且已经超过了人类识别图像的能力。
文章插图
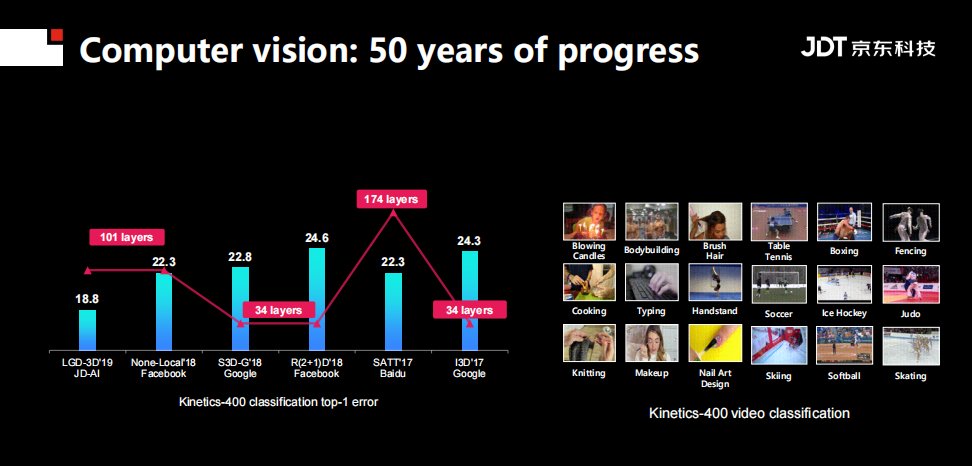
在视频分析领域。Kinetics-400 视频分析任务反应了该领域的进展,从2017年和2019年出现了各种适合视频任务的神经网络,其网络大小、深度并不一致,而且从准确率、识别精度上看,也没有一致的结果。换句话说,该领域存在大量的潜力(open question)。至于原因,个人认为有两种:
1.视频内容非常多样化,而且是时空连续的数据。
2.同样的语义,在视频中会有不同的含义。例如不同语气和不同表情下对同一个词的输出。

文章插图
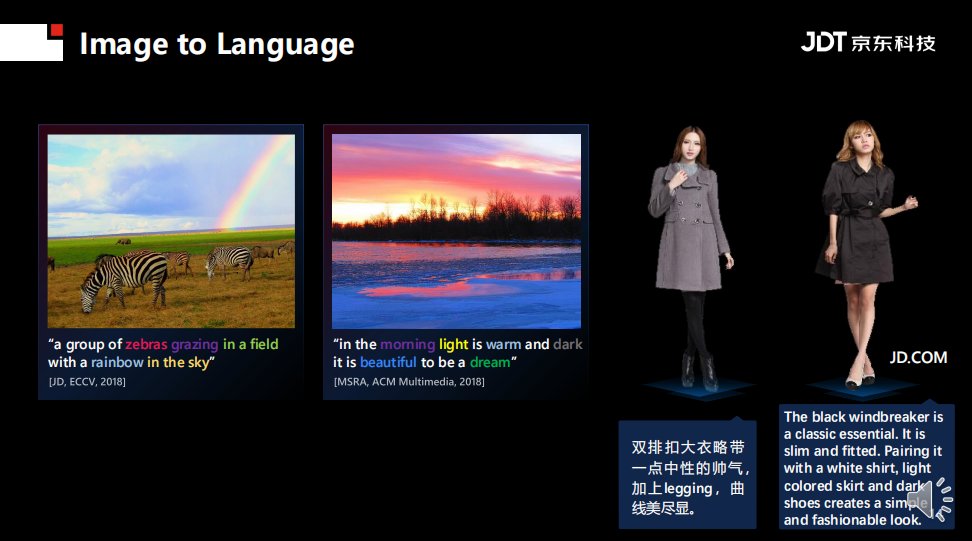
过去10~20年,视觉感知领域存在很多主题。如上图所示,从最小力度的像素级别到视频级别,基本上可以归为几大研究领域:语义分隔、物体检测、视频动作行为识别、图像分类、Vision and language。其中,Vision and language最近五年比较火热,其要求不仅从图视频内容里面生成文字描述,并且也可以反过来从文字描述生成视频或者图片的内容。
总结起来,目前视觉研究的主要方向还是进行RGB视频和图像研究,在不远的将来,成像的方式会发生变化,那时研究的数据将不仅是2D,更会过渡3D,甚至更多的多模态的数据。
在视觉理解领域,通用的视觉理解非常简单:例如区分猫和狗,区分车和人。但在自然界里,要真正的做到对世界的理解,其实要做到非常精细的粒度的图像识别。一个直观的例子是鸟类识别,理想中的机器需要识别10万种鸟类,才能达到人类对“理解世界”的要求。如果再精细一些,需要达到商品SKU细粒度识别。
注:一瓶200毫升和300毫升的矿泉水就是不同粒度的SKU。
过去几年,京东在这方面做了一些探索。探索路径包括:detection的方式,detection结合attention的方式,以及自监督的方式。涉及论文包括CVPR2019 的“Destruction and Construction Learning ”以及CVPR 2020的“Self-supervised”相关工作。

文章插图
论文地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Destruction_and_Construction_Learning_for_Fine-Grained_Image_Recognition_CVPR_2019_paper.pdf

文章插图
论文地址:https://arxiv.org/abs/2003.14142
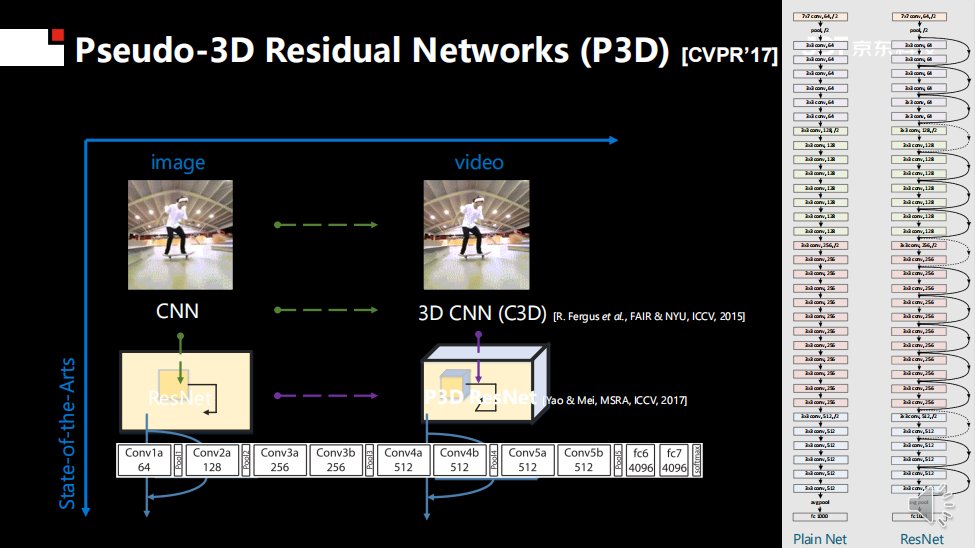
视频领域非常有挑战,当年我想借鉴ResNet,毕竟在图像识别领域它是非常有创新的网络,因为其里面包含skip level的调整。因此,当时我想把2D的CNN直接应用到3D领域。
其实,相关工作已经有人尝试,但存在一定的困难。例如Facebook发现,如果沿着xyz三个轴进行卷积,参数会爆炸,所以很难提高模型性能。因此在2015年,Facebook只设计了一个11层的3D卷积网络。
文章插图
我的尝试是基于ResNet进行3D卷积设计,但也遇到了和Facebook同样的困难,即参数爆炸。因此,在CVPR 2017年的一项工作中,我利用一个1*3*3的二维空间卷积和3*1*1的一维时域卷积来模拟常用的3*3*3三维卷积。
通过简化,相比于同样深度的二维卷积神经网络仅仅增添了一定数量的一维卷积,在参数数量、运行速度等方面并不会产生过度的增长。与此同时,由于其中的二维卷积核可以使用图像数据进行预训练,对于已标注视频数据的需求也会大大减少。目前该论文引用超过1000次,得到了行业的认可。

文章插图
论文地址:https://arxiv.org/abs/1711.10305
文章插图
其他研究领域也有很多问题有待开发。例如在3D视觉研究方面,不仅需要语义分割,还需要估计物体的姿态;在Image to Language研究中,不仅需要给定一张图片生成一段描述文字,还需要知道物体之间的空间关系语义关系。
- 汽车|大型内卷现场!华为进军汽车领域,问界M5搭载鸿蒙OS系统
- 芯片|清华大学不负众望,打破芯片领域技术限制,成功出货核心设备!
- 无线耳机|小米获多项专利授权,涉及拍照、显示、无线耳机等领域
- 华为|厉害了,华为在汽车领域又有新成果,智能汽车座舱管家软件获批
- 蒙版|涉人机交互领域,腾讯虚拟宠物外观编辑专利公布
- 互联网|规模万亿、新势力涌现、投资机构力挺,工业领域数字化进入加速期
- 工业和信息化|工信部:工业和信息化领域数据处理者应当对各类数据实行分级防护
- 高通骁龙|基于脑电图的非侵入性技术和接口,已经在相当广泛的领域中得到应用
- 工业和信息化|工信部:工业和信息化领域数据处理者境内收集和产生的重要数据向境外提供应进行数据出境安全评估
- 华为|大厂逐鹿全屋智能领域