MySQL三万字精华总结+面试100问,吊打面试官绰绰有余( 六 )
MyISAM主键索引与辅助索引的结构MyISAM引擎的索引文件和数据文件是分离的 。 MyISAM引擎索引结构的叶子节点的数据域 , 存放的并不是实际的数据记录 , 而是数据记录的地址 。 索引文件与数据文件分离 , 这样的索引称为"非聚簇索引" 。 MyISAM的主索引与辅助索引区别并不大 , 只是主键索引不能有重复的关键字 。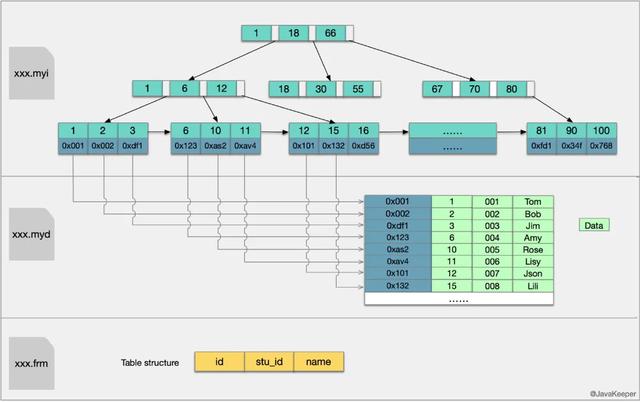 文章插图
文章插图
在MyISAM中 , 索引(含叶子节点)存放在单独的.myi文件中 , 叶子节点存放的是数据的物理地址偏移量(通过偏移量访问就是随机访问 , 速度很快) 。
主索引是指主键索引 , 键值不可能重复;辅助索引则是普通索引 , 键值可能重复 。
通过索引查找数据的流程:先从索引文件中查找到索引节点 , 从中拿到数据的文件指针 , 再到数据文件中通过文件指针定位了具体的数据 。 辅助索引类似 。
InnoDB主键索引与辅助索引的结构InnoDB引擎索引结构的叶子节点的数据域 , 存放的就是实际的数据记录(对于主索引 , 此处会存放表中所有的数据记录;对于辅助索引此处会引用主键 , 检索的时候通过主键到主键索引中找到对应数据行) , 或者说 , InnoDB的数据文件本身就是主键索引文件 , 这样的索引被称为“聚簇索引” , 一个表只能有一个聚簇索引 。
主键索引:我们知道InnoDB索引是聚集索引 , 它的索引和数据是存入同一个.idb文件中的 , 因此它的索引结构是在同一个树节点中同时存放索引和数据 , 如下图中最底层的叶子节点有三行数据 , 对应于数据表中的id、stu_id、name数据项 。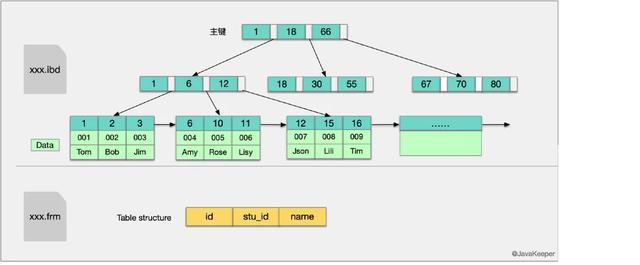 文章插图
文章插图
在Innodb中 , 索引分叶子节点和非叶子节点 , 非叶子节点就像新华字典的目录 , 单独存放在索引段中 , 叶子节点则是顺序排列的 , 在数据段中 。 Innodb的数据文件可以按照表来切分(只需要开启innodb_file_per_table) , 切分后存放在xxx.ibd中 , 默认不切分 , 存放在xxx.ibdata中 。
辅助(非主键)索引:这次我们以示例中学生表中的name列建立辅助索引 , 它的索引结构跟主键索引的结构有很大差别 , 在最底层的叶子结点有两行数据 , 第一行的字符串是辅助索引 , 按照ASCII码进行排序 , 第二行的整数是主键的值 。
这就意味着 , 对name列进行条件搜索 , 需要两个步骤:
① 在辅助索引上检索name , 到达其叶子节点获取对应的主键;
② 使用主键在主索引上再进行对应的检索操作
这也就是所谓的“回表查询”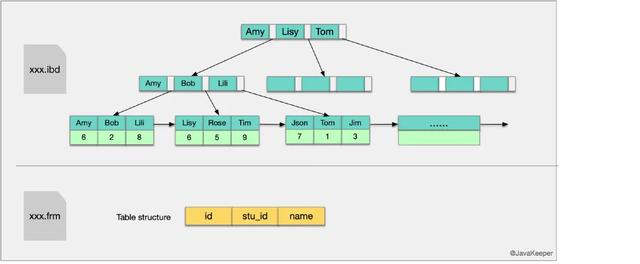 文章插图
文章插图
InnoDB 索引结构需要注意的点
- 数据文件本身就是索引文件
- 表数据文件本身就是按 B+Tree 组织的一个索引结构文件
- 聚集索引中叶节点包含了完整的数据记录
- InnoDB 表必须要有主键 , 并且推荐使用整型自增主键
?
那为什么推荐使用整型自增主键而不是选择UUID?
- UUID是字符串 , 比整型消耗更多的存储空间;
- 在B+树中进行查找时需要跟经过的节点值比较大小 , 整型数据的比较运算比字符串更快速;
- 自增的整型索引在磁盘中会连续存储 , 在读取一页数据时也是连续;UUID是随机产生的 , 读取的上下两行数据存储是分散的 , 不适合执行where id > 5--tt-darkmode-color: #D29D44;">在插入或删除数据时 , 整型自增主键会在叶子结点的末尾建立新的叶子节点 , 不会破坏左侧子树的结构;UUID主键很容易出现这样的情况 , B+树为了维持自身的特性 , 有可能会进行结构的重构 , 消耗更多的时间 。
为什么非主键索引结构叶子节点存储的是主键值?
保证数据一致性和节省存储空间 , 可以这么理解:商城系统订单表会存储一个用户ID作为关联外键 , 而不推荐存储完整的用户信息 , 因为当我们用户表中的信息(真实名称、手机号、收货地址···)修改后 , 不需要再次维护订单表的用户数据 , 同时也节省了存储空间 。
- 三星|顶配旗舰重回最低价,三个月降价四百,12G+256G+120W
- 路由器|千兆双频WiFi6,还能异地组网,什么神仙路由器只卖三百多?
- 电池|百元级散热器,超频三东海R4000拯救热到可以蒸蛋的机箱
- 荣耀|建议收藏!2021年底盘点:这三款旗舰可以让你安逸地使用两三年
- 酷派|酷派:国产手机“假高端”严重,用户不应分为三六九等
- 苹果|要是不看真实数据,我还以为国产机将iPhone打成下一个三星了呢
- 电池|2021年年底买千元机,这四款用三五年没问题,十二月购机必看
- wi-fi6|12月物超所值的三款高性价比手机推荐 价格不超过3000元
- iphone13|iPhone13 缺货问题得到改善,发货时间变快,第三方优惠将更大
- realme|买不起“十三香”?目前这4款真香机最值得买,三五年不卡顿