AIPM要知道的NLP知识(1):词的表达( 二 )
 文章插图
文章插图
很有意思的是最初word embedding其实是为了训练NNLM(Neural Network Language Model)得到的副产品 。
训练语言模型会得到一个lookup table , 这个lookup table有点像地下工作者用的密码本;通过这个密码本可以将one-hot向量转换成更低维度的word embedding向量 , 可见词向量实现的关键就是得到密码本lookup table 。
后来更高效的得到word embedding的模型之一就是word2Vec , word2Vec又有两种模型 , 分别是CBOW和skip-gram;两者都可以得到lookup table , 具体模型和实现不在这里展开 。
word embedding可以作为判断语义相似度的一种手段 , 但更多的是作为其他nlp任务的第一步 。
实际中如果不是特殊领域(军事、法律等)的词典 , word embedding可以用别人训练好的 , 提高效率;所以word embedding也可以看做神经网络预处理的一种 。
另外说一下 , word embedding有个最大的问题是不能处理多义词 。
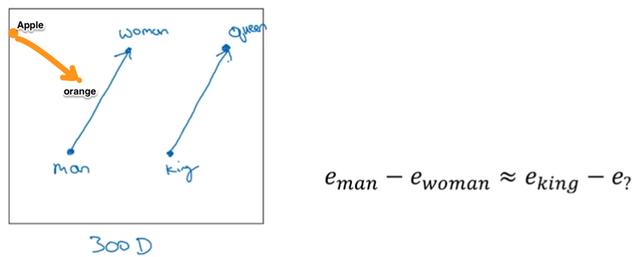
举个栗子“苹果员工爱吃苹果” , 第一个苹果是指苹果公司 , 第二个是指水果;但对于word embedding来说二者只能对应一个向量(比如[0.1 -0.3]) , 在处理后续任务时只要是苹果就对应成[0.1 -0.3] , 所以通过词向量并不能区分出苹果的不同词义 。
总结一下 , 词的表达我觉得要知道:
- 为什么需要词表达 。
- 几个常见名词(one-hot representation、distributed representation、word embedding、word2Vec)之间的关系 。
- word embedding比one-hot强在哪里 。
- word embedding有什么缺点 。
题图来自Unsplash , 基于CC0协议 。
- 删除|电脑老是自动安装软件,有时还自动跳出广告对话框,必须要根治!
- oppo reno|到OPPO线下体验了一番,终于知道Reno7系列为什么卖得这么好了
- 闪存|变频器要怎样使用才能确保省电?
- 耳机|获投近亿元,海归博士创业8年打造元宇宙入口,要颠覆现有互联网终端
- 华强北|揭露华强北屏幕维修猫腻,换个TP压个盖板就可以,你都知道吗?
- 苹果|要是不看真实数据,我还以为国产机将iPhone打成下一个三星了呢
- 安卓|要是国产手机都不能用安卓系统了,会怎样?
- 华为智慧屏|手机有必要上一亿像素吗?这组样张对比图给出了答案
- iPhone|iPhone 14传来好消息,终于要干掉千年的刘海了!
- 小米科技|干货来了!Windows11系统要怎么装?两种方法都可以实现安装!