Apache Hudi与Apache Flink集成
Apache Hudi是由Uber开发并开源的数据湖框架 , 它于2019年1月进入Apache孵化器孵化 , 次年5月份顺利毕业晋升为Apache顶级项目 。 是当前最为热门的数据湖框架之一 。
1. 为何要解耦Hudi自诞生至今一直使用Spark作为其数据处理引擎 。 如果用户想使用Hudi作为其数据湖框架 , 就必须在其平台技术栈中引入Spark 。 放在几年前 , 使用Spark作为大数据处理引擎可以说是很平常甚至是理所当然的事 。 因为Spark既可以进行批处理也可以使用微批模拟流 , 流批一体 , 一套引擎解决流、批问题 。 然而 , 近年来 , 随着大数据技术的发展 , 同为大数据处理引擎的Flink逐渐进入人们的视野 , 并在计算引擎领域获占据了一定的市场 , 大数据处理引擎不再是一家独大 。 在大数据技术社区、论坛等领域 , Hudi是否支持使用flink计算引擎的的声音开始逐渐出现 , 并日渐频繁 。 所以使Hudi支持Flink引擎是个有价值的事情 , 而集成Flink引擎的前提是Hudi与Spark解耦 。
同时 , 纵观大数据领域成熟、活跃、有生命力的框架 , 无一不是设计优雅 , 能与其他框架相互融合 , 彼此借力 , 各专所长 。 因此将Hudi与Spark解耦 , 将其变成一个引擎无关的数据湖框架 , 无疑是给Hudi与其他组件的融合创造了更多的可能 , 使得Hudi能更好的融入大数据生态圈 。
2. 解耦难点Hudi内部使用Spark API像我们平时开发使用List一样稀松平常 。 自从数据源读取数据 , 到最终写出数据列表 , 无处不是使用Spark RDD作为主要数据结构 , 甚至连普通的工具类 , 都使用Spark API实现 , 可以说Hudi就是用Spark实现的一个通用数据湖框架 , 它与Spark的绑定可谓是深入骨髓 。
此外 , 此次解耦后集成的首要引擎是Flink 。 而Flink与Spark在核心抽象上差异很大 。 Spark认为数据是有界的 , 其核心抽象是一个有限的数据集合 。 而Flink则认为数据的本质是流 , 其核心抽象DataStream中包含的是各种对数据的操作 。 同时 , Hudi内部还存在多处同时操作多个RDD,以及将一个RDD的处理结果与另一个RDD联合处理的情况 , 这种抽象上的区别以及实现时对于中间结果的复用 , 使得Hudi在解耦抽象上难以使用统一的API同时操作RDD和DataStream 。
3. 解耦思路理论上,Hudi使用Spark作为其计算引擎无非是为了使用Spark的分布式计算能力以及RDD丰富的算子能力 。 抛开分布式计算能力外 , Hudi更多是把 RDD作为一个数据结构抽象 , 而RDD本质上又是一个有界数据集 , 因此 , 把RDD换成List,在理论上完全可行(当然 , 可能会牺牲些性能) 。 为了尽可能保证Hudi Spark版本的性能和稳定性 。 我们可以保留将有界数据集作为基本操作单位的设定 , Hudi主要操作API不变 , 将RDD抽取为一个泛型 ,Spark引擎实现仍旧使用RDD,其他引擎则根据实际情况使用List或者其他有界数据集 。
解耦原则:
1)统一泛型 。 Spark API用到的JavakRDD,JavaRDD,JavaRDD
2)去Spark化 。 抽象层所有API必须与Spark无关 。 涉及到具体操作难以在抽象层实现的 , 改写为抽象方法 , 引入Spark子类实现 。
例如:Hudi内部多处使用到了JavaSparkContext#map()方法 , 去Spark化 , 则需要将JavaSparkContext隐藏 , 针对该问题我们引入了HoodieEngineContext#map()方法 , 该方法会屏蔽map的具体实现细节 , 从而在抽象层实现去Spark化 。
3)抽象层尽量减少改动 , 保证hudi原版功能和性能;
4)使用HoodieEngineContext抽象类替换JavaSparkContext , 提供运行环境上下文 。
4.Flink集成设计Hudi的写操作在本质上是批处理 , DeltaStreamer的连续模式是通过循环进行批处理实现的 。 为使用统一API , Hudi集成flink时选择攒一批数据后再进行处理 , 最后统一进行提交(这里flink我们使用List来攒批数据) 。
这批操作最容易想到的是通过使用时间窗口来实现 , 然而 , 使用窗口 , 在某个窗口没有数据流入时 , 将没有输出数据 , Sink端难以判断同一批数据是否已经处理完 。 因此我们使用flink的检查点机制来攒批 , 每两个barrier之间的数据为一个批次 , 当某个子任务中没有数据时 , mock结果数据凑数 。 这样在Sink端 , 当每个子任务都有结果数据下发时即可认为一批数据已经处理完成 , 可以执行commit 。
DAG如下: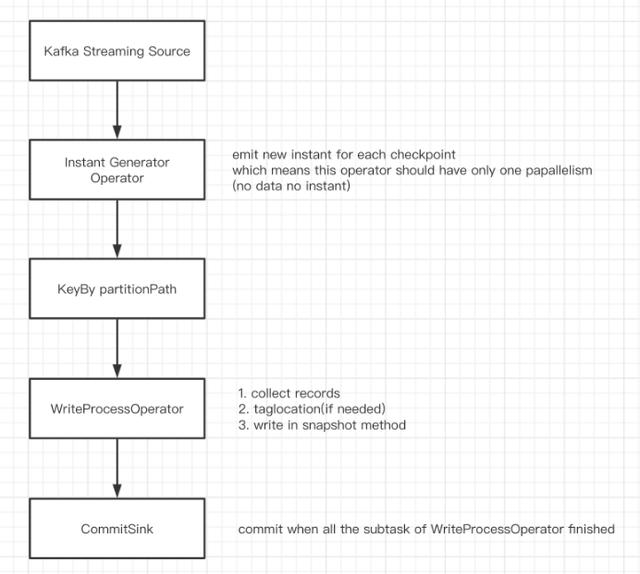 文章插图
文章插图
- C++|嵌入式开发:C++中的结构与类
- 苏宁易购|透视2022年家电市场 头部家电品牌与苏宁易购敲定提升策略
- 摄像头|李彦宏《智能交通》与百度Apollo,还是小瞧它的胃口了!
- 智能网联汽车|我国智慧城市基础设施与智能网联汽车协同发展第二批试点城市公布
- 原创|别花冤枉钱,我教你怎么样给电脑装系统,安装版与Ghost都不难!
- 华为|12月刚开始,手机圈就传来两个重磅消息,与iPhone、华为有关
- 腾讯云|白银市政府与腾讯云达成战略合作
- 华为|Windows 11明年将让用户自定义开始菜单,显示更多应用与推荐项目
- playstation5|一加10 Pro传言消息汇总,有一点与往年不同
- |与任正非并称“二任”,把千亿公司给国家,堪称中国“并购之王”