搜索|图解 ElasticSearch 原理,你可收好了!( 二 )
文章插图
Stored Field 字段查找
当我们想要查找包含某个特定标题内容的文件时,Inverted Index 就不能很好的解决这个问题,所以 Lucene 提供了另外一种数据结构 Stored Fields 来解决这个问题。
本质上,Stored Fields 是一个简单的键值对 key-value。默认情况下,ElasticSearch 会存储整个文件的 JSON source。
文章插图
Document Values 为了排序,聚合
即使这样,我们发现以上结构仍然无法解决诸如:排序、聚合、facet,因为我们可能会要读取大量不需要的信息。
所以,另一种数据结构解决了此种问题:Document Values。这种结构本质上就是一个列式的存储,它高度优化了具有相同类型的数据的存储结构。
文章插图
为了提高效率,ElasticSearch 可以将索引下某一个 Document Value 全部读取到内存中进行操作,这大大提升访问速度,但是也同时会消耗掉大量的内存空间。
总之,这些数据结构 Inverted Index、Stored Fields、Document Values 及其缓存,都在 segment 内部。
# 搜索发生时
搜索时,Lucene 会搜索所有的 Segment 然后将每个 Segment 的搜索结果返回,最后合并呈现给客户。
Lucene 的一些特性使得这个过程非常重要:
Segments 是不可变的(immutable):Delete?当删除发生时,Lucene 做的只是将其标志位置为删除,但是文件还是会在它原来的地方,不会发生改变。
Update?所以对于更新来说,本质上它做的工作是:先删除,然后重新索引(Re-index)。
随处可见的压缩:Lucene 非常擅长压缩数据,基本上所有教科书上的压缩方式,都能在 Lucene 中找到。
缓存所有的所有:Lucene 也会将所有的信息做缓存,这大大提高了它的查询效率。
# 缓存的故事
当 ElasticSearch 索引一个文件的时候,会为文件建立相应的缓存,并且会定期(每秒)刷新这些数据,然后这些文件就可以被搜索到。
文章插图
随着时间的增加,我们会有很多 Segments,如下图:
文章插图
所以 ElasticSearch 会将这些 Segment 合并,在这个过程中,Segment 会最终被删除掉。
文章插图
这就是为什么增加文件可能会使索引所占空间变小,它会引起 Merge,从而可能会有更多的压缩。
举个栗子
有两个 Segment 将会 Merge:
文章插图
这两个 Segment 最终会被删除,然后合并成一个新的 Segment,如下图:
文章插图
这时这个新的 Segment 在缓存中处于 Cold 状态,但是大多数 Segment 仍然保持不变,处于 Warm 状态。
以上场景经常在 Lucene Index 内部发生的,如下图:
文章插图
# 在 Shard 中搜索
ElasticSearch 从 Shard 中搜索的过程与 Lucene Segment 中搜索的过程类似。
文章插图
与在 Lucene Segment 中搜索不同的是,Shard 可能是分布在不同 Node 上的,所以在搜索与返回结果时,所有的信息都会通过网络传输。
需要注意的是:1 次搜索查找 2 个 Shard=2 次分别搜索 Shard。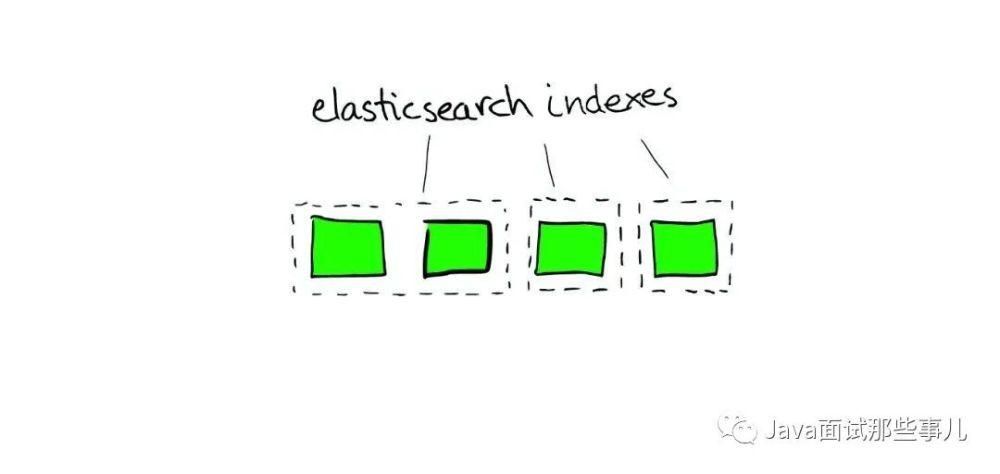
文章插图
对于日志文件的处理:当我们想搜索特定日期产生的日志时,通过根据时间戳对日志文件进行分块与索引,会极大提高搜索效率。
当我们想要删除旧的数据时也非常方便,只需删除老的索引即可。
文章插图
在上种情况下,每个 Index 有两个 Shards。
# 如何 Scale
如下图: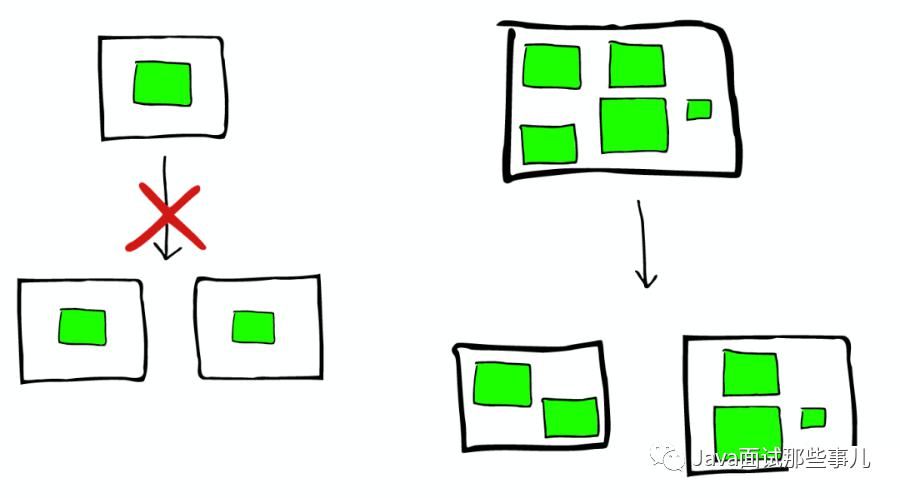
文章插图
Shard 不会进行更进一步的拆分,但是 Shard 可能会被转移到不同节点上。
文章插图
所以,如果当集群节点压力增长到一定的程度,我们可能会考虑增加新的节点,这就会要求我们对所有数据进行重新索引,这是我们不太希望看到的。
所以我们需要在规划的时候就考虑清楚,如何去平衡足够多的节点与不足节点之间的关系。
- 红米手机|全球搜索引擎市场份额:谷歌搜索92.54%,百度搜索1.08%
- 龚俊数字人走进搜索框
- 地址栏|Win10/Win11 学院:如何高效地使用搜索引擎
- se2021 年了,还有搜索引擎比 Google 更懂我?
- 剧本|线上推理你玩过吗?360搜索上线《推理档案局》线上推理项目
- 齐鲁在线网|中国搜索推出“5G融媒搜索” 将为5G全面商用带来全新体验
- 齐鲁在线网|中国搜索“多模态机器狗”亮相中国网络媒体论坛
- s开源神经搜索公司“Jina AI”完成3000万美元A轮融资
- 使用率|进一步打通视频号,微信的大搜索远望
- |千万别在手机上搜索见不得人的东西!真的是太尴尬了...