赛灵思姚颂:数字AI芯片进步趋缓,颠覆式创新难 | GTIC2020( 二 )
AI芯片核心解决的是什么问题?去堆并行算力?实际并不是 。
谷歌TPU第一代的论文中写道 , 其芯片最开始是为了自己设计的GoogLeNet做的优化 , CNN0的部分就是谷歌自己设计的Inception network , 谷歌设计的峰值性能是每秒92TeraOps , 而这个神经网络能跑到86 , 数值非常高;但是对于谷歌不太擅长的LSTM0 , 其性能只有3.7 , LSTM1的性能只有2.8 , 原因在于它整个的存储系统的带宽其实不足以支撑跑这样的应用 , 因而造成了极大的算力浪费 。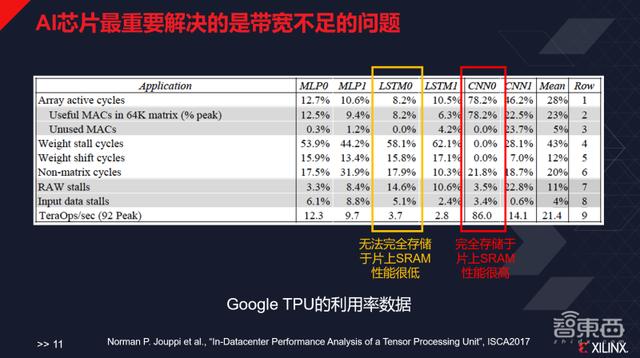 文章插图
文章插图
AI芯片最重要解决的是带宽不足的问题
AI芯片最重要解决的问题核心是带宽不足的问题 , 其中一种最粗暴且奢侈的方式就是用大量的片上SRAM(静态随机存取存储器) , 比如原来寒武纪用36MB DRAM做DianNao , 深鉴科技曾用10.13MB SRAM做EIE , TPU采用过28MB SRAM 。
而将这种工程美学发挥到中最“残暴”的公司 , 叫做Cerebras , 它把一整个Wafer只切一片芯片 , 有18GB的SRAM , 所有的数据、模型都存在片上 , 因此其性能爆棚 。
当然这种方式是非常奢侈的 , Cerebras要为它单独设计解决制冷、应力等问题 , 单片芯片的成本就在1百万美元左右 , 对外一片芯片卖500美元 , 这一价格非常高昂 。 因此业内就需要用微架构等其他方式解决这一问题 。
业内常用的有两种解决方式:
一是在操作时加一些buffer , 因为神经网络是一个虽然并行 , 但层间又是串行的结构 。 把前一层的输出buffer住 , 或把它直接用到下一层作为输入 。
二是在操作时做一些切块 , 因为神经网络规模比较大 , 每次将它切一小部分 , 比如16X16 , 把切出来这一块的计算一次性做完 , 在做这部分计算的时候同步开始读取下一块的数据 , 让这件事像流水线一样串起来 , 就可以掩盖掉很多存储、读取的延迟 。
现在在数字电路层面 , 业内更多在做一些架构的更新 , 根据不同的应用需求做架构的设计 。
三、数字AI芯片颠覆式创新难在谈到AI芯片产业特点时 , 姚颂说 , 首先AI芯片的概念非常宽泛 , 所以它并不一定是特别难的事 。 文章插图
文章插图
数字AI芯片产业特点
设计一颗特别通用的芯片很难 , 设计CPU和GPU同样很难 , 但是如果只做某一颗芯片 , 只支持某一个算法和某几个算法 , 其实并不太难 , 尤其是对算力的需求很低的时候 , 技术难度就没有那么大了 。 以至于现在对于一些简单的神经网络的加速 , 直接付钱给芯原微电子、GUC等机构 , 都可以帮助做前端定制 。 因此对于AI芯片还是要辩证看待 , 不同的东西难度也不同 。
第二 , 高集成度对于终端市场来说非常重要 , 这是所有做AI起家的公司都会认识到的一点 。
举例来说 , 如果厂商想要将AI芯片做到摄像头里面 , ISP怎么做、SoC谁来做?将AI芯片做到耳机里面 , 是语音唤醒的AI部分最终集成蓝牙做成SoC , 还是蓝牙的部分集成AI做成SoC?这些都是要考虑的问题 。
对于终端市场来说 , 一定是高集成度的方式比分立器件的方式占优势 , 所以对于终端市场一定要考虑全面 , 而不能仅仅考虑AI这一个IP 。
第三 , 软件生态才是AI芯片的核心壁垒 。
英伟达创始人兼CEO黄仁勋最近开发布会时说 , 英伟达已经有180万的开发者、30万个开源项目 , 99.99%的初学者在学AI时一定会买一块GPU , 下载一些Github上的开源项目做试验 。 这是英伟达最终的一个护城河 , 它会有源源不断的开发者加入 , 开发者又会为生态贡献新的项目 , 如果开发者没有达到一定数量 , 则很难突破AI芯片的生态壁垒 。
姚颂说 , 这与滴滴、淘宝以及其他互联网平台是一个逻辑 , 一边是商家一边是用户 , 一边是开发者一边是使用者 , 这是一个闭环软件生态的逻辑 , 是最核心的壁垒 。
在单纯的数字芯片领域、单纯的学术研究做微架构迭代的领域 , 数字集成电路领域从2016年开始至今没有见到特别大的创新 。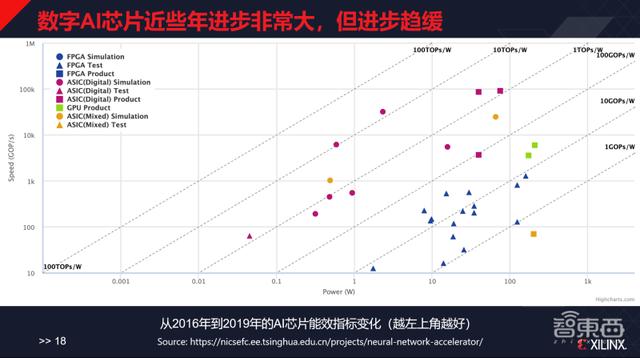 文章插图
文章插图
2016年至2019年AI芯片能效指标变化
上图中显示的是从2016年至2019年的AI芯片能效指标变化 , “方形”是实际量产的产品 。 这个图越往上代表性能越好 , 越往右是功耗越高 , 因此在这张图中 , 越偏向左上角意味着性能越好 。
而实际上大量的“方形”都落在了图的右上角 , 处于1~10TOPs/W的两条线之间 , 现在性能比较好的产品基本上在1~2TOPs/W的区间内 , 这几年在量产级别上没有见到特别大的变化 。 行业内有很多工程在往产品方向走 , 但是通用的微架构迭代的进步已经趋缓 。
- ip|永辉宣布启动自有品牌节 旗下家居类自有品牌优颂推出新IP形象
- 负载|专为HPC与大数据工作负载打造,赛灵思推出加速器卡Alveo U55C
- 钉钉|华为申请“大禹”商标:因治理滔天洪水而广受世人传颂
- 赛灵思|芯片大厂新一轮提价潮:ST、赛灵思等计划四季度涨价
- 自动驾驶|掘金自动驾驶,赛灵思看上了一家中国公司
- 赛灵思|中国不反对AMD收购Xilinx,根本不意外
- 平台|赛灵思刘珊珊:自适应、可编程平台正在加速工业视觉
- 千场巡讲进万家 智慧生活颂百年,淄博联通开展了这样一场活动
- 致敬匠心!他们,值得被歌颂
- AMD350亿美元收购赛灵思获得股东批准 还需获得监管部门批准