标题|数据格式规范,这些方法的格式你都get了吗?( 二 )
除卡方检验,涉及使用加权格式数据的分析方法还有很多,比如
文章插图
5、重复测量方差
重复测量数据是指同一批样本(病例)在不同的时间点测量了多次数据,因此重复测量数据的特殊之处在于一定会有ID号(即样本或者病例号),以及时间点数据。
同一个ID会有多个时间点的数据,比如下面有12个样本(12个ID号),并且测量5个时间点。那么就一定会有12*5=60行数据。同一个ID号会重复5次,同一个时间点会重复12次。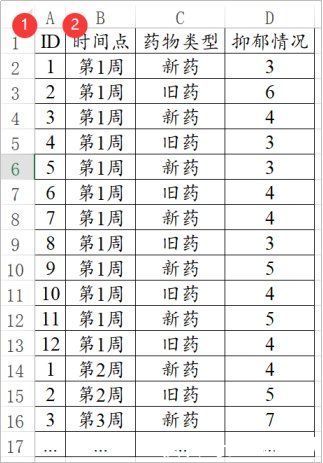
文章插图
6、时间序列
时间序列的格式包括时间和实际分析项共两列。ARIMA预测、ADF检验、偏(自)相关图等方法均是使用此类格式的数据进行分析。
比如下图中年份就是时间项,“阿里双十一销售额(亿元)”就是实际分析项。分析时并不需要设置时间项,但研究人员整理的数据一定是类似如下图,从上至下的日期递增,因为算法在分析时也是默认按照从上至下递增进行计算。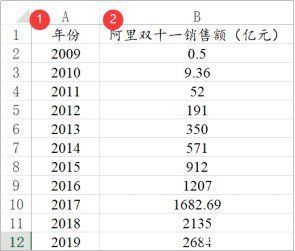
文章插图
7、面板数据
面板模型是针对面板数据进行分析,面板数据是一种特殊的数据格式。比如当前研究100家公司5年的财务数据。100家公司,每家5年,最终会有100*5=500行数据。
如果说100家公司全部都有完整的5年数据,即100*5=500行数据,这种叫平衡面板数据。如果说某家公司只有3年的数据,意味着有2年的缺失数据,这种叫非平衡面板数据。
使用SPSSAU进行分析时,‘个体ID’就是下图中的‘公司编号’,‘时间’就是下图中的‘年份’。‘公司编号’一般是指上市公司的股票代码,也或者只是个编号均可;‘年份’一般是指年或者时间点。‘公司编号’和‘年份’两项共同用于告诉系统当前为面板数据,通常无其它意义。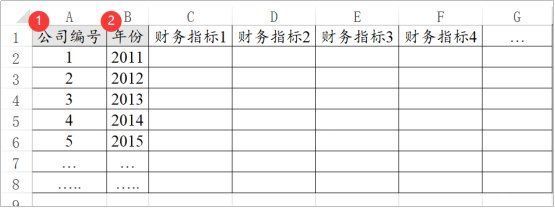
文章插图
三、综合评价中的数据格式综合评价中各个方法所需要的数据格式都比较特殊,这里列出单独进行说明。
1、模糊综合评价
模糊综合评价是对具有多种属性的事物,综合各因素作出一个总体评价。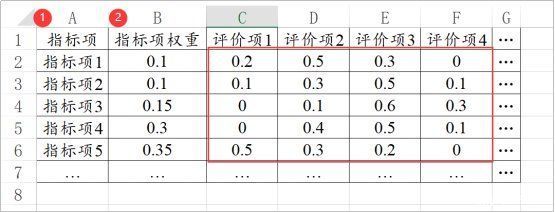
文章插图
上传的数据一般包括三个部分:指标项、权重项、评语项。
其中指标项为参与评价的考核指标,1行放1个。
评语项,是指类似于{优秀,良好,一般,差} 或{非常满意,满意,一般,不满意,非常不满意}这样的评价标准。1列放1个评价项。
如果说各个指标项有着自己的权重,那么就需要单独用一列表示‘指标项权重值’,‘如果没有此数据,则默认各个指标的权重完全一致。
特别提示:一个表格对应的是一个评价对象的数据。如果有多个评价对象就需要构建多个表格矩阵,分别上传进行分析。
2、灰色关联法
灰色关联法研究数据之间的关联程度,即特征序列与母序列的关联性情况。母序列单独使用一列标识,每个特征序列都使用1列标识。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。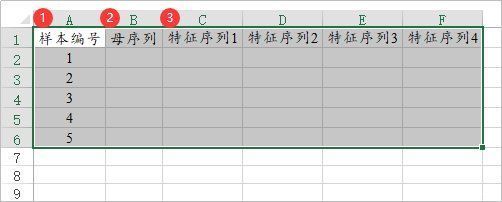
文章插图
3、AHP层次分析法
AHP层次分析法需要分别对各级指标两两比较得到判断矩阵,然后将指标数值填入白色单元格。
研究人员可修改指标项名称,以及白色单元格内的数字,‘蓝色’背景的信息会自动变化。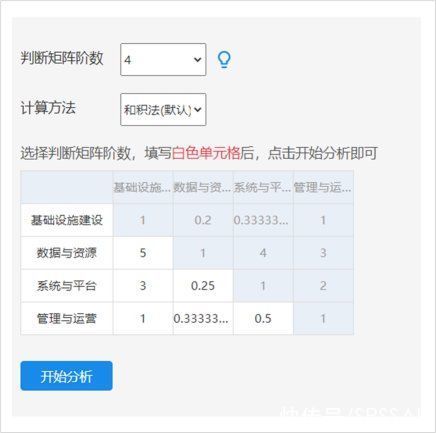
文章插图
4、熵值法
熵值法用于指标的权重情况。1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。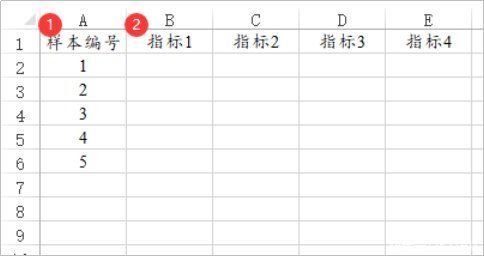
文章插图
熵值法的原理是针对数据不确定性进行度量,从而计算权重。无论是什么数据(包括面板数据),均可正常的进行熵值法,一般不需要进行处理。
当然面板数据进行熵值法分析时,也可以先筛选出不同的年份,重复进行多次熵值法均可。
5、TOPSIS法
TOPSIS法用于研究指标与理想解的接近度情况。1个指标占用1列数据。1个研究对象为1行,但研究对象在分析时并不需要使用,SPSSAU默认会从上到下依次编号。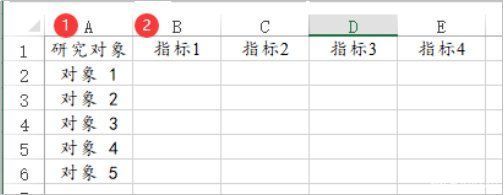
- 优派|美国很满意:150多家芯片厂商,都“自愿”提交了详细数据
- 苹果|要是不看真实数据,我还以为国产机将iPhone打成下一个三星了呢
- 短视频|运用5种套路写好短视频标题,视频播放量提升90%!
- 何树山|合肥国际互联网数据专用通道开通
- Python|联想真的没有问题?中国院士公布数据,胡锡进改变立场
- 台积电|夹击台积电?“银弹”风暴将袭来,交出数据后的台积电可能没料到
- 数据库|提前三天自动续费,这合理吗?
- 联想|联想5年前旧闻变新闻,公众苦网络平台“标题党”久矣
- 微软|打工人必备技能!django查询数据库操作合集!
- 安卓|django怎么连接数据库?你知道吗?