最强|剑指临床试验的设计难题!达摩院提出新模型EBM-Net,比最强基线模型准确率高9.6%( 二 )
为了解决上述临床试验结果预测任务,达摩院的团队提出了针对循证医学的EBM-Net模型,其结构如图2所示,具体分为三步进行:
首先,用启发式方法收集隐式证据;
然后,用隐式证据预训练比较语言模型;
最后,用预训练的模型进行临床试验结果预测。
收集隐式证据临床证据常常以一种比较的形式表达,如“瑞德西韦比对照组有更好的治疗新冠肺炎的疗效”,而找到这些证据就可以为我们提供训练文本。
研究团队发现,PubMed和PubMed Central是一个提供生物医学方面的论文搜寻以及摘要,文献资源中就包含需要的证据文本(注:医学领域最好的大规模语言模型BioBERT的训练数据即来自PubMed)。
这篇论文提出用关键词匹配的方法,收集PubMed和PubMed Central中所有含有比较语义的句子:
为寻找表达升高和降低的语义,匹配含有“than”的句子,再进一步匹配形容词或副词的比较级,如“higher”,“smaller”等,同时含有“than”和一个或更多比较级的句子被收集;为寻找表达相似的语义,匹配含有“no difference between”和“similar to”模式的句子。
这些句子被称为隐式证据,因为它们往往隐式地含有临床证据所需要的PICO组分。他们还收集这些句子对应的文章摘要里的背景和方法的部分,作为隐式证据的背景B。
这种方法可以从PubMed和PubMed Central中提取出1180万条隐式证据,其中240万条表达结果降低,350万条表达结果相似,590万条表达结果升高。
预训练比较语言模型将收集到的隐式证据中提示结果语义的词去除,就构造了一个类似语言模型训练的问题,通过给定上下文信息,预测去除的比较词。
论文中改进语言模型,提出用比较语言模型预训练一个Transformer编码器模型,即EBM-Net,以获取预测临床试验结果的能力。具体地,两组样本被用于预训练:
1、用正序的隐式证据预测其结果;
2、用反序的隐式证据预测相反的结果。
加入反序的例子有利于模型学到治疗组和对照组之间的比较,而不是语言模型里的共现关系。
临床试验结果预测在微调和测试时,团队将一个新临床试验要研究的PICO要素拼接成E,将E和其研究背景B输入到上述预训练好的EBM-Net模型中,输出其预测的比较结果,从而预测临床试验的结果。
标准数据集的试验结果EBM-Net在临床试验结果预测任务的标准数据集Evidence Integration试验结果如图3所示: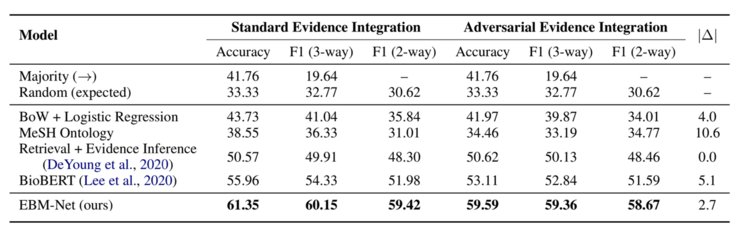
文章插图
从结果中可以看出:
1、EBM-Net相比其他方法,包括随机预测、词袋+逻辑回归、利用MeSH知识图谱、信息检索+阅读理解模型以及目前生物医学NLP领域的SOTA模型BioBERT,都有很大的提高:BioBERT作为最强的基线模型,也比EBM-Net低了10.7%的相对macro-F1和9.6%的准确率;
2、EBM-Net相比其他方法在对抗攻击下更鲁棒:用|Δ||Δ|,即在对抗数据集上的accuracy的相对减少的值来衡量模型的鲁棒性,|Δ||Δ|越大表示模型越易受攻击。
BioBERT的|Δ||Δ|几乎是EBM-Net的两倍(5.1%比2.7%),说明EBM-Net远比BioBERT鲁棒;
EBM-Net用于新冠肺炎相关临床试验达摩院团队还基于COVID-evidence数据库提取了截止5月12日前完成的22篇临床试验的结果,以本工作定义的临床试验结果预测的格式构建了一个小型数据集。
达摩院团队提出的EBM-Net模型在该数据集上进行留一法验证得到的macro-F1和accuracy都远高于BioBERT,分别是45.5%比36.1%和59.1%比50.0%,再一次验证了EBM-Net的有效性。
总结为了优化临床试验的设计过程,本文从NLP的角度定义了临床试验结果预测任务,并且提出了一种基于大规模隐式证据预训练的EBM-Net模型来解决这个任务。
EBM-Net在标准数据集和新冠肺炎相关临床试验上都有较好的表现,大幅超过生物医学NLP的SOTA模型BioBERT。
未来,临床试验可以在EBM-Net等相关模型的协助下进行设计:
当我们固定了想要研究的疾病人群(P)和观察指标(O)后,可以固定以现有的标准治疗为对照(C),遍历每种可能的新型治疗方式(I)以及其相关的背景介绍(B),用模型预测其成功的概率,优先选取所有可能的治疗方式中成功概率高的做临床试验。
当然,模型在技术上还需要进一步地提高才能更好地辅助临床试验设计。后续,我们可以把团队构建的大规模医学知识图谱集成在模型中,使其拥有更准确和鲁棒的预测能力。雷锋网
- spring|性能最强5G手机,现在现货供应,好评率97%
- 小米科技|雷军突然官宣,一切让人没有预料,可能是性能最强的小米手机
- 散热器|雷军官宣,可能是最强大的小米手机要来了,旧机型无奈加速退场
- 相机|官宣开始量产!小米新机要来了!可能是目前性能最强的小米手机了
- 荣耀|最强前置镜头?荣耀60系列或搭载5000万像素前摄
- 笔记本|OriginOS Ocean首张产品海报亮相!设计风格大改,冲击业界最强?
- gtx|英伟达最强4G显卡,GTX1650 Super游戏测试,显卡溢价的最佳选择
- 苹果|反击苹果正式开始!国内科技巨头发出最强声音!全球第二要换人
- 6e|1分钟看懂全球最强电视芯片:7nm联发科旗舰
- 高通骁龙|和联发科硬碰硬!高通新一代骁龙8处理器发布:参数史上最强