最强|剑指临床试验的设计难题!达摩院提出新模型EBM-Net,比最强基线模型准确率高9.6%

文章插图
雷锋网消息,日前,AI领域顶会EMNLP 2020落下帷幕。
今年全球仅有754篇论文被接受,接收率为24%,阿里巴巴凭借28篇论文成为入选论文数最多的中国科技公司。
据雷锋网了解,阿里相关研究成果覆盖情感分析、文本生成及医疗NLP等领域。
在今年疫情的大环境下,医疗领域的研究与成果产出也不断提速。
在名为《Predicting Clinical Trial Results by Implicit Evidence Integration》的论文中,达摩院研究团队设计了针对医学临床试验的进一步预训练任务,并提出全新的模型,帮助医学研究工作者更好地选择医学临床试验,以更快地找到有效的治疗方案。
研究团队在COVID-evidence数据集上完成了试验,并证明了模型的有效性。
论文链接:https://www.aclweb.org/anthology/2020.emnlp-main.114/
为此,该论文作者、达摩院算法专家谭传奇进行了解读。
文章插图
自18年谷歌BERT横空出世以来,预训练语言模型一跃成为自然语言处理领域的研究热点,“Pre-training + Fine-tune”也成为NLP任务的新范式,将自然语言处理由原来的手工调参、依靠机器学习专家的阶段,进入到可以大规模、可复制的大工业施展的阶段。
这篇论文在BioBERT(在医学数据上训练的BERT模型)的基础上,设计了针对医学临床试验的进一步预训练任务(Post-Pre-training),最终在真实医学临床试验数据上微调(Fine-tune)后,取得了超过10个百分点的结果提升。
而这项工作的意义在于,帮助医学研究工作者更好地选择医学临床试验,特别在COVID-19疫情下,更好的医学临床试验或许就意味着能更快地找到有效的治疗方案。
剑指临床试验的设计难题在循证医学的时代,任何的治疗都要有相应的临床证据支持。证据往往来自于高质量的临床试验。然而,实施临床试验耗时耗力,需要大量资源支持。
并且,设计有缺陷或者难以成功的临床试验占用了宝贵的病人资源,可能会使亟待实施的临床试验因招募不到足够的患者而被迫终止。
新冠肺炎疫情中的瑞德西韦临床试验就是一个例子:
因其他设计有缺陷或者难以成功的临床试验占用了不少病人资源,该试验没有招募到足够的病人资源,而没有得到统计学上显著的结果。
所以,研究者需要在设计阶段就去预测临床试验的结果,并优先进行成功概率较高的临床试验。
提出新的临床试验需要过往临床证据的支持,比如WHO为新冠肺炎推荐优先检测氯喹/羟氯喹,瑞德西韦,干扰素和洛匹那韦/利托那韦四种药物优先进行临床试验。
推荐的理由就是,这些药物在过往的实验室或人体试验中对相关冠状病毒有效。然而,人类综合过往临床证据的能力有限。
谭传奇引用了一个数据:一项研究发现大概86.2%的临床试验最终会失败,WHO专家推荐的某些新冠肺炎治疗方法,如氯喹/羟氯喹,也没有得到好的结果。
临床试验设计难题的核心是临床试验的结果无法准确预测。
所以,如果能准确地预测临床试验的结果,就可以有针对性地进行成功概率的临床试验,从而大大提高临床试验实施的效率。
因此,谭传奇团队表示,在本工作中,我们的贡献就在于:
第一、创新地从NLP的角度重新定义了临床试验结果预测任务;
第二、提出了一种基于大规模隐式临床证据预训练的模型EBM-Net(Evidence-Based Medicine Network)用以解决该任务,EBM-Net在各种指标上远超医学大规模语言模型BioBERT,如在标准数据集上有10.7%的相对F1提升,并且在新冠肺炎相关的临床试验上也被证明有效。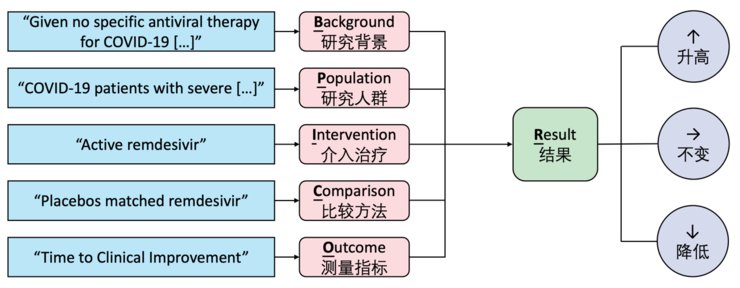
文章插图
【 最强|剑指临床试验的设计难题!达摩院提出新模型EBM-Net,比最强基线模型准确率高9.6%】在上面这张图中,参考医学临床试验在填报提案时需要的基本信息,输入是自然文本的形式的:
临床试验背景B,如“最新研究发现瑞德西韦在体外对新冠肺炎病毒有效……”;
要研究的人群P,如“重症新冠肺炎病人”;
治疗方法I,如“静脉注射瑞德西韦”;
对照方法C,如“与瑞德西韦相匹配的安慰剂”;
测量指标O,如“死亡率”
输出是其结果R,即在研究人群P中,治疗组I和对照组C的测量结果O的比较关系,有升高、降低和不变三种。
EBM-Net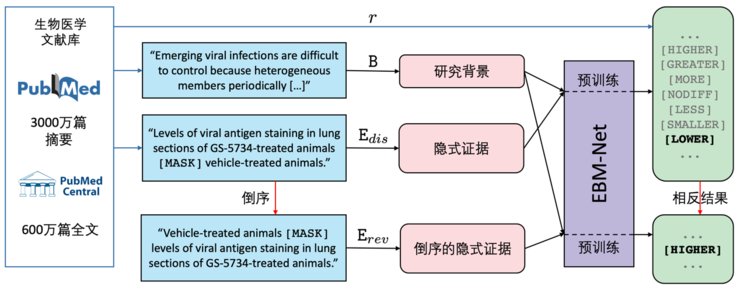
文章插图
- spring|性能最强5G手机,现在现货供应,好评率97%
- 小米科技|雷军突然官宣,一切让人没有预料,可能是性能最强的小米手机
- 散热器|雷军官宣,可能是最强大的小米手机要来了,旧机型无奈加速退场
- 相机|官宣开始量产!小米新机要来了!可能是目前性能最强的小米手机了
- 荣耀|最强前置镜头?荣耀60系列或搭载5000万像素前摄
- 笔记本|OriginOS Ocean首张产品海报亮相!设计风格大改,冲击业界最强?
- gtx|英伟达最强4G显卡,GTX1650 Super游戏测试,显卡溢价的最佳选择
- 苹果|反击苹果正式开始!国内科技巨头发出最强声音!全球第二要换人
- 6e|1分钟看懂全球最强电视芯片:7nm联发科旗舰
- 高通骁龙|和联发科硬碰硬!高通新一代骁龙8处理器发布:参数史上最强