清华大学刘知远:知识指导的自然语言处理( 三 )
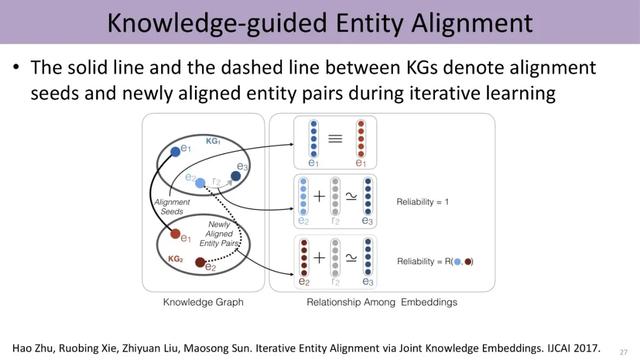 文章插图
文章插图
同时 , 知识也能指导我们进行信息检索 , 计算query和文档之间的相似度 。 除了考虑query和document中词的信息 , 我们可以把实体的信息、以及实体跟词之间的关联形成不同的矩阵 , 从而支持排序模型的训练 。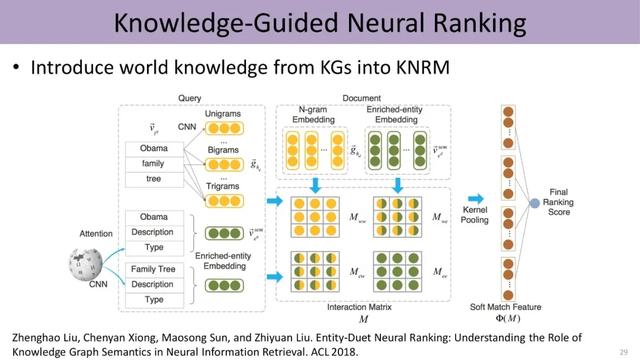 文章插图
文章插图
最后 , 预训练语言模型的诞生 , 把深度学习从原来有监督的数据扩展到了大规模无监督数据 。 事实上 , 这些大规模文本中的每句话 , 都包含大量实体以及它们之间的关系 。 我们理解一句话 , 往往需要外部的世界知识的支持 。
能否把外部知识库加入预训练语言模型呢?2019年 , 刘知远所在的团队提出ERNIE模型 , 使用知识表示算法(transE)将知识图谱中的实体表示为低维的向量 , 并利用一个全新的收集器(aggregator)结构 , 通过前馈网络将词相关的信息与实体相关的信息双向整合到一起 , 完成将结构化知识加入到语言表示模型的目的 。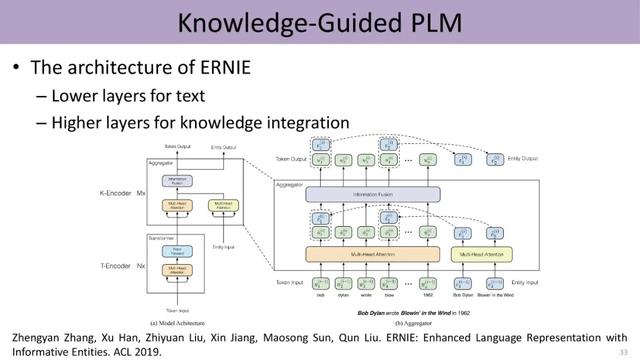 文章插图
文章插图
四、总结
本次报告主要从义原知识和世界知识两个方面 , 阐述了知识指导的自然语言处理相关的工作 。 未来自然语言处理的一个重要方向 , 就是融入人类各种各样的知识 , 从而深入地理解语言 , 读懂言外之意、听出弦外之音 。 针对面向自然语言处理的表示学习 , 刘知远等人也发表了一本专著 , 供大家免费下载研读 。 文章插图
文章插图
【清华大学刘知远:知识指导的自然语言处理】相关链接及参考文献: 文章插图
文章插图 文章插图
文章插图 文章插图
文章插图 文章插图
文章插图
- 快递|国家邮政局:推动邮政快递行业由劳动密集型向知识密集型发展
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 双行合一|关于Word我们要了解的知识(12)
- 经济总量|美国经济总量世界第一,究竟是靠哪些产业支撑的呢?看完长知识了
- 电脑知识|北大青鸟:零基础学电脑从哪里入手
- 打击|莫让知识产权侵权“打击”了家电行业的创新积极性
- 为什么手机大厂们都喜欢搞子品牌?看完算长知识了
- 今天才发现,微信长按2秒,还有6个隐藏功能,涨知识了
- 学习大数据需要具备哪些基础知识,以及应该重视哪些环节
- 又爆新作!阿里甩出架构师进阶必备神仙笔记,底层知识全梳理