清华大学刘知远:知识指导的自然语言处理( 二 )
 文章插图
文章插图
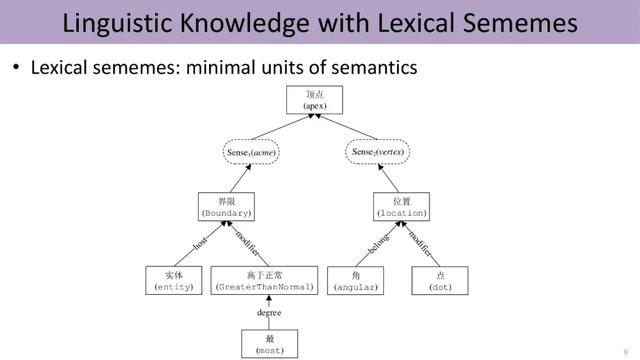
在人工标注义原方面 , 语言学家董振东先生辛劳数十年 , 手工标注了一个知识库HowNet , 发布于1999年 。 经过几轮迭代 , 现囊括约2000个不同的义原 , 并利用这些义原标注了中英文各十几万个单词的词义 。 文章插图
文章插图
然而深度学习时代 , 以word2vec为代表的大规模数据驱动的方法成为主流 , 传统语言学家标注的大规模知识库逐渐被推向历史的墙角 , HowNet、WordNet等知识库的引用明显下跌 。
那么 , 数据驱动是最终的AI解决方案么?
直觉上并非如此 。 数据只是外在信息、是人类智慧的产物 , 却无法反映人类智能的深层结构 , 尤其是高层认知 。 我们能否教会计算机语言知识呢?
HowNet与Word2Vec的融合
2017年 , 刘知远等人尝试将HowNet融入当时深度学习自然语言处理中一个里程碑式的工作Word2Vec , 取得了振奋人心的实验效果 。
下图展示了义原指导的word embedding , 该模型根据上下文来计算同一词语不同义原的注意力、得到不同词义的权重 , 从而进行消歧 , 进一步利用上下文学习该词义的表示 。 尽管利用了传统Word2Vec中skip-gram的方法 , 即由中心词Wt预测滑动窗口里上下文的词 , 然而中心词的embedding由标注好的义原的embedding组合而成 。 因此 , 这项研究将HowNet中word、sense和sememe三层结构融入word embedding中 , 综合利用了知识库和数据两方面的信息 。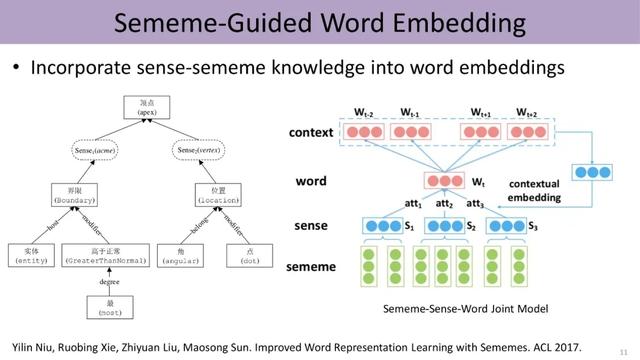 文章插图
文章插图
实验结果证明 , 融入HowNet的知识可以显著提升模型效果 , 尤其是涉及认知推理、类比推理等成分的任务 。 并且 , 我们能自动发现文本中带有歧义的词在具体语境下隶属于哪一个词义 。 不同于过去有监督或半监督的方法 , 该模型并未直接标注这些词所对应的词义 , 而是利用HowNet知识库来完成 。 由此可见 , 知识库对于文本理解能够提供一些有意义的信息 。 文章插图
文章插图
受到这项工作的鼓舞 , 刘知远的团队将知识的运用从词语层面扩展到句子级别 。 过去深度学习是直接利用上文的语义预测下一个词 , 现在把word、sense和sememe的三层结构嵌入预测过程中 。 首先由上文预测下一个词对应的义原 , 然后由这些义原激活对应的sense , 进而由sense激活对应的词 。 一方面 , 该方法引入知识 , 利用更少的数据训练相对更好的语言模型;另一方面 , 形成的语言模型具有更高的可解释性 , 能够清楚地表明哪些义原导致了最终的预测结果 。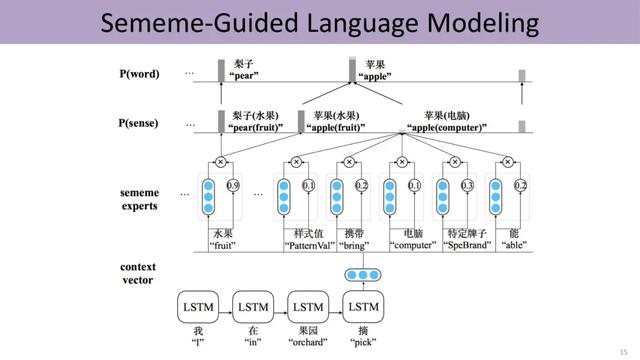 文章插图
文章插图
HowNet作为董振东先生一生非常重要的心血 , 已经开源出来供大家免费下载和使用 , 希望更多老师和同学认识到知识库的独特价值 , 并开展相关的工作 。 下面是义原知识相关的阅读列表 。 文章插图
文章插图
三、世界知识:听懂弦外之音
除了语言上的知识 , 世界知识也是语言所承载的重要信息 。 文章插图
文章插图
现实世界中有多种多样的实体以及它们之间各种不同的关系 , 比如莎士比亚创作了《罗密欧与朱丽叶》 , 这些世界知识可以构成知识图谱(knowledge graph) 。 在知识图谱中 , 每个节点可以看成一个实体 , 连接它们的边反映了这些实体之间的关系 。 图谱由若干三元组构成 , 每个三元组包括头实体、尾实体以及它们之间的关系 。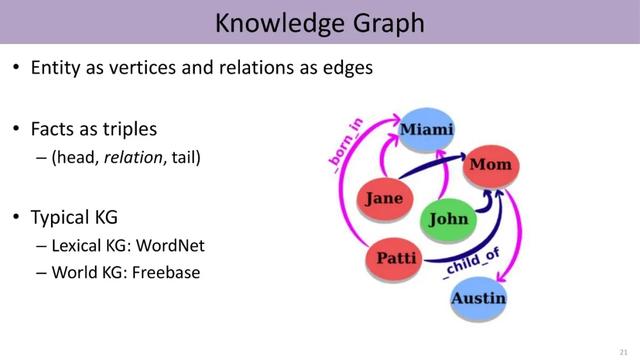 文章插图
文章插图
由于知识图谱中的实体隶属不同的类别 , 而且具有不同的连接信息 , 因此我们可以基于knowledge attention这种机制 , 把低维向量的知识表示与文本的上下文表示结合起来 , 进行细粒度实体分类的工作 。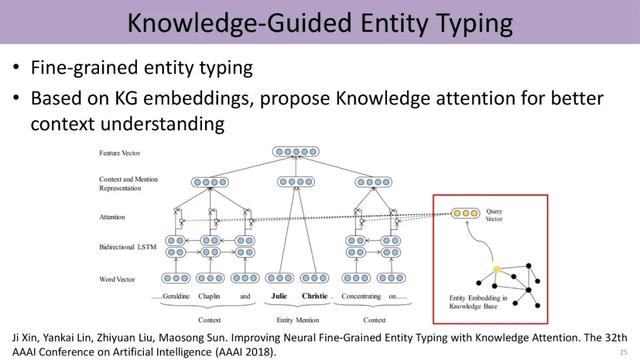 文章插图
文章插图
另一个方向是两个不同知识图谱的融合问题 , 实为一个典型的entity alignment的问题 , 过去一般要设计一些特别复杂的算法 , 发现两个图谱之间各种各样蛛丝马迹的联系 。 现在实验室提出了一个简单的方法 , 把这两个异质图谱分别进行knowledge embedding , 得到两个不同的空间 , 再利用这两个图谱里面具有一定连接的实体对、也就是构成的种子 , 把这两个图谱的空间结合在一起 。 工作发现 , 该方法能够更好地进行实体的对齐 。
- 快递|国家邮政局:推动邮政快递行业由劳动密集型向知识密集型发展
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 双行合一|关于Word我们要了解的知识(12)
- 经济总量|美国经济总量世界第一,究竟是靠哪些产业支撑的呢?看完长知识了
- 电脑知识|北大青鸟:零基础学电脑从哪里入手
- 打击|莫让知识产权侵权“打击”了家电行业的创新积极性
- 为什么手机大厂们都喜欢搞子品牌?看完算长知识了
- 今天才发现,微信长按2秒,还有6个隐藏功能,涨知识了
- 学习大数据需要具备哪些基础知识,以及应该重视哪些环节
- 又爆新作!阿里甩出架构师进阶必备神仙笔记,底层知识全梳理