Python数据处理,pandas 统计连续停车时长
 文章插图
文章插图
定期找些简单练习作为 pandas 专栏的练习题
知识点
- DataFrame.apply 以及 axis 的理解
- 分组计数
- DataFrame.iloc 切片
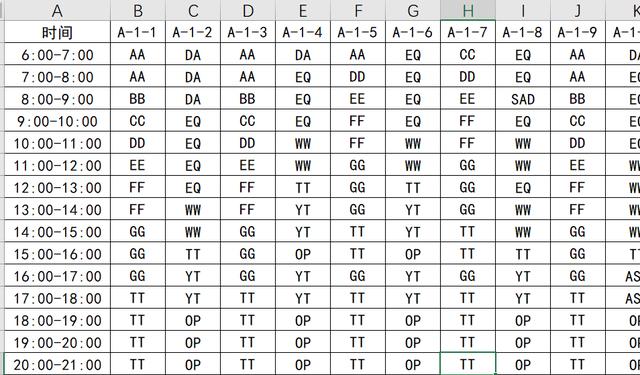 文章插图
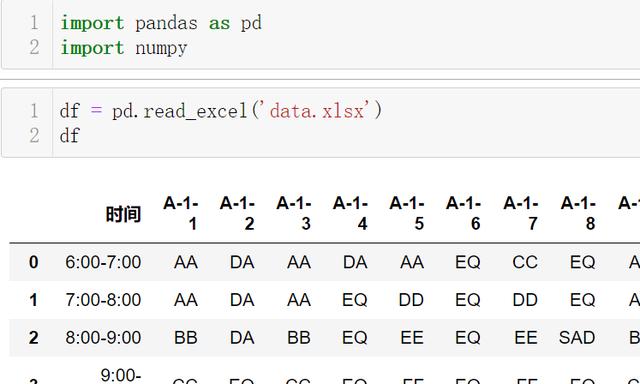
文章插图- 每行表示某时间段(总是1个小时)每个停车位停放是那辆车(内容视为车牌吧)
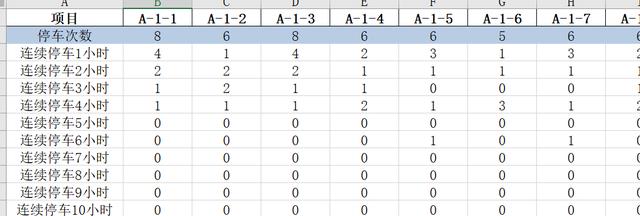 文章插图
文章插图共2个需求:
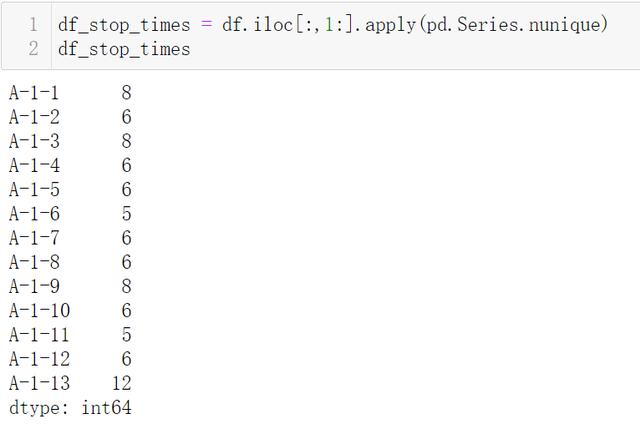
需求1:停车次数(蓝色行):一天中 , 每个停车位分别有多少不同的车停放 , 如下:
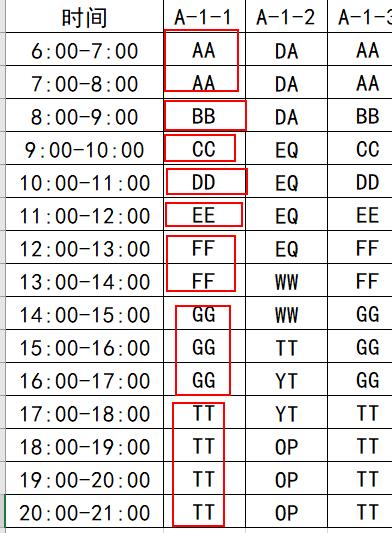 文章插图
文章插图- 分别有8辆不同车牌 , 因此这个停车位的"停车次数"是8
- 就算同一天有相同的车在不同时段停放 , 只算一次
如下:
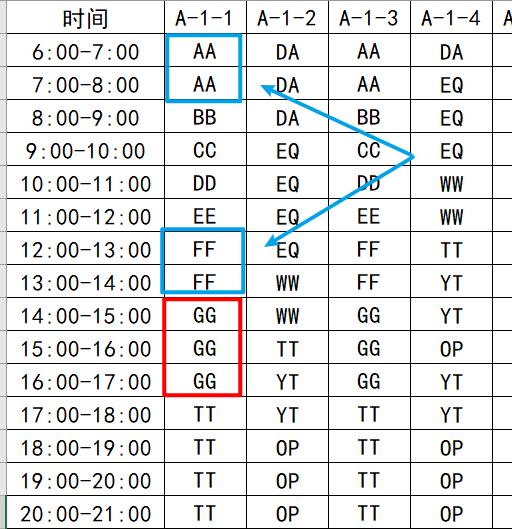 文章插图
文章插图- 第一个停车位中 , 连续出现3次的区域只有一个(3个"GG"), 因此这个停车位"连续停车3小时"结果是1
- 同理 , "连续停车2小时"结果是2(分别是"AA"与"FF")
 文章插图
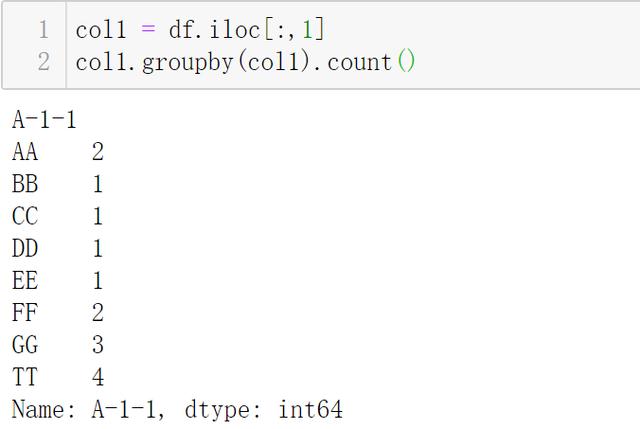
文章插图需求1按理解 , 可以描述为"不同车牌数量" , 相当于去重复后的车牌数 。
因此代码非常简单:
 文章插图
文章插图- df.iloc, 由于第一列是"时间" , 不是需要的数据 , 通过切片获取第一列到最后的所有列
- .apply, 注意参数 axis 默认为0 , 表示数据表每一列作为处理单位
- pd.Series.nunique 就是去重计数
 文章插图
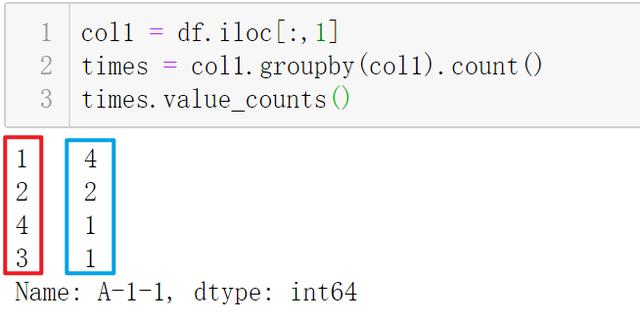
文章插图- 我这只考虑一列的处理情况 , 因为所有列批量处理只需要调用 apply 即可
- 这里同样可以使用 Series.value_counts() 做到一样的效果
 文章插图
文章插图- 行3:按之前的处理 , 统计次数
- 注意此时结果是一个 Series , index(上图红框) 是"连续n小时停车" 。 value(上图蓝框) 是连续n小时停车出现的次数
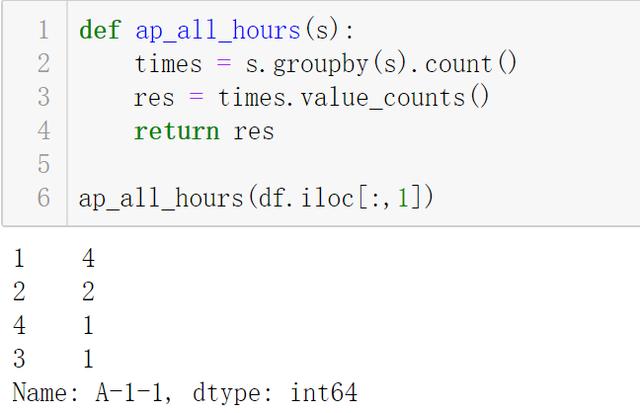 文章插图
文章插图- 行6:选出一列执行看看效果
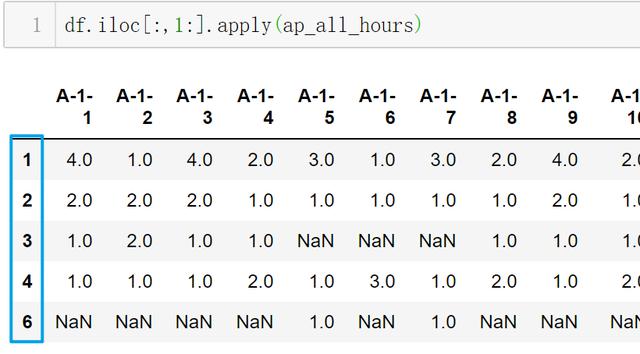 文章插图
文章插图- 注意 行索引(蓝框) 是"连续n小时停车"
reindex 就是为了这种场景而设计:
 文章插图
文章插图- 行4:顺手把空值填成 0
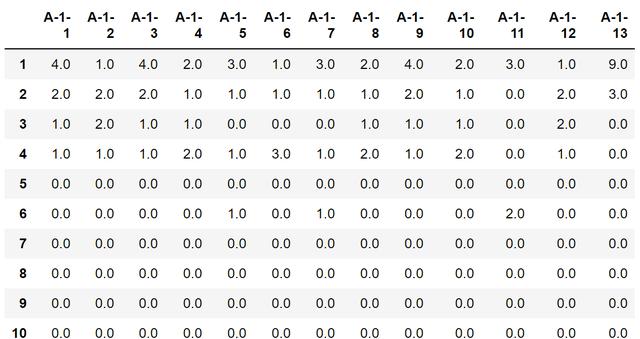 文章插图
文章插图之后只是合并2个需求结果输出 Excel 即可 , 具体看源码
但是 , 结果真的对吗?!!!
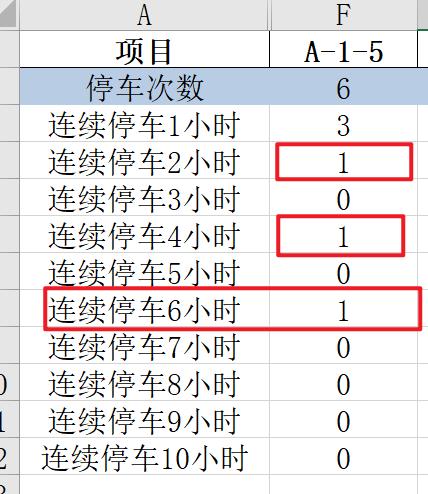
看看第5个停车点:
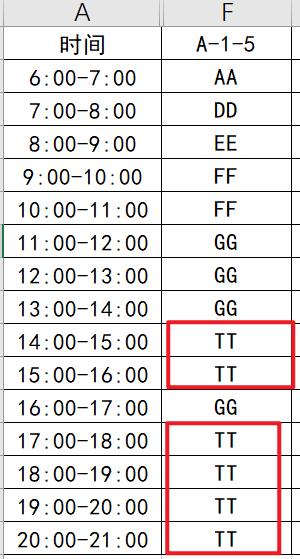 文章插图
文章插图- 连续停4个小时应该有1个吧
- 大于4个小时的应该是0吧
 文章插图
文章插图- 连续6小时竟然有1次
也就是说我们的处理过程根本没有反映需求中的"连续"的意义
怎么办?我也想不到 , 希望大家给点建议
或者看看专栏关于"波动走势处理"的相关章节 , 说不定找到答案
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?
- Pandas教程